Every line of code you write carries the requirement of maintenance through the lifetime of an application. The more lines of code you have, the more maintenance is required, and the more code you have to change as the application adapts to the evolving requirements.

Unfortunately, popular wisdom decrees that we need more test code than application code. In this post, I’m going to discuss why this idea is not quite correct, and how we can improve our code to actually avoid writing so many tests.
First, we should address a few things:
I’ve seen some online courses proclaim that advanced TypeScript is simply picking a few complex features from the laundry list of TypeScript features, such as conditional types.
In truth, advanced TypeScript uses the compiler to find logic flaws in our application code. Advanced TypeScript is the practice of using types to restrict what your code can do and uses tried-and-trusted paradigms and practices from other type systems.
Type-driven development is writing your TypeScript program around types and choosing types that make it easy for the type checker to catch logic errors. With type-driven development, we model the states our application transitions in type definitions that are self-documenting and executable.
Non-code documentation becomes out of date the moment it is written. If the documentation is executable, we have no choice but to keep it up to date. Both tests and types are examples of executable documentation.
I am shamelessly stealing the above heading from the excellent talk, Making Impossible States Impossible by Richard Feldman.
For my money, the real benefit of using a powerful type system like TypeScript is to express application logic in states that only reveal their fields and values depending on the current context of the running application.
In this post, I will use an authentication workflow as an example of how we can write better types to avoid writing so many tests.
Jump ahead:
ts-pattern instead of switch statementsThe Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
When thinking about authentication, it boils down to whether or not the current user is known to the system.
The following interface seems uncontroversial, but it hides several hidden flaws:
export interface AuthenticationStates {
readonly isAuthenticated: boolean;
authToken?: string;
}
If we were to introduce this seemingly small interface into our code, we would need to write tests to verify the many branching if statements. We would also have to write code to check whether or not a given user is authenticated.
One big problem with the interface is that nothing can stop us from assigning a valid string to the authToken field while isAuthenticated is false. What if it was possible for the authToken field only to be available to code when dealing with a known user?
Another niggle is using a boolean field to discriminate states. We stated earlier that our types should be self-documenting, but booleans are a poor choice if we want to support this. A better way of representing this state is to use a string union:
export interface AuthenticationStates {
readonly state: 'UNAUTHENTICATED' | 'AUTHENTICATED';
authToken?: string;
}
The biggest problem with our AuthenticationStates type is that only one data structure houses all of our fields. What if, after a round of testing, we found that we wanted to report system errors to the user?
With the single interface approach, we end up with several optional fields that create more branching logic and swell the number of unit tests we need to write:
export interface AuthenticationStates {
readonly state: 'UNAUTHENTICATED' | 'AUTHENTICATED';
authToken?: string;
error?: {
code: number;
message: string;
}
}
The refactored AuthenticationStates type below is known, in high-falutin functional programming circles, as an algebraic data type (ADT):
export type AuthenticationStates =
| {
readonly kind: "UNAUTHORIZED";
}
| {
readonly kind: "AUTHENTICATED";
readonly authToken: string;
}
| {
readonly kind: "ERRORED";
readonly error: Error;
};
One kind of algebraic type (but not the only one) is the discriminated union, as is the AuthenticationStates type above.
A discriminated union is a pattern that indicates to the compiler all the possible values a type can have. Each union member must have the same primitive field (boolean, string, number) with a unique value, known as the discriminator.
In the example above, the kind field is the discriminator and has a value of "AUTHENTICATED", "UNAUTHENTICATED", or "ERRORED". Each union member can contain fields that are only relevant to its specific kind. In our case, the authToken has no business being in any union member other than AUTHENTICATED.
The code below takes this example further by using the AuthenticationStates type as an argument to a getHeadersForApi function:
function getHeadersForApi(state: AuthenticationStates) {
return {
"Accept": "application/json",
"Authorization": `Bearer ${state.??}`; // currently the type has no authToken
}
}
Suppose our code doesn’t contain any logic to determine or narrow the kind of state our application is in. In that case, even as we type the code into our text editor, the type system is keeping us safe and not giving us the option of an authToken:
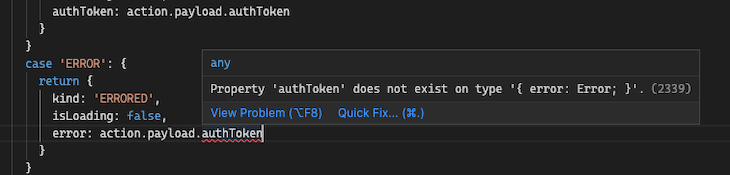
If we can programmatically determine that state can only be of kind AUTHENTICATE, then we can access the authToken field with impunity:
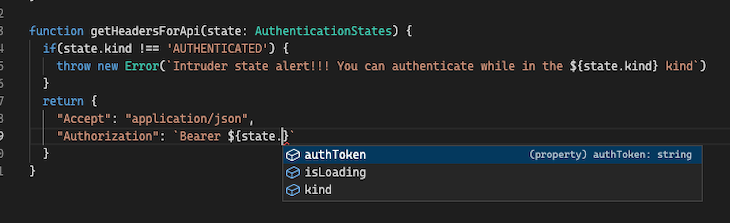
The above code throws an error if the state is not of the kind AUTHENTICATED.
Throwing an exception is one way to tell the compiler which of the union members is current. Drilling down into a single union member is also known as type narrowing. Type narrowing on a discriminated union is when the compiler knows its precise discriminator field. Once the compiler knows which discriminator field is assigned, the other properties of that union member become available.
Narrowing the type in this way and throwing an exception is like having a test baked into our code without the ceremony of creating a separate test file.
type AuthenticationStates =
| {
readonly kind: "UNAUTHORIZED";
readonly isLoading: true;
}
| {
readonly kind: "AUTHENTICATED";
readonly authToken: string;
readonly isLoading: false;
}
| {
readonly kind: "ERRORED";
readonly error: Error;
readonly isLoading: false;
};
type AuthActions =
| {
type: 'AUTHENTICATING';
}
| {
type: 'AUTHENTICATE',
payload: {
authToken: string
}
}
| {
type: 'ERROR';
payload: {
error: Error;
}
}
function reducer(state: AuthenticationStates, action: AuthActions): AuthenticationStates {
switch(action.type) {
case 'AUTHENTICATING': {
return {
kind: 'UNAUTHORISED',
isLoading: true
}
}
case 'AUTHENTICATE': {
return {
kind: 'AUTHENTICATED',
isLoading: false,
authToken: action.payload.authToken
}
}
case 'ERROR': {
return {
kind: 'ERRORED',
isLoading: false,
error: action.payload.error
}
}
default:
return state;
}
}
With discriminated unions, we can get instant feedback from our text editor and IntelliSense about which fields are currently available.
The screenshot below shows a silly developer (me) trying to access the authToken while in the ERROR case statement. It simply is not possible:
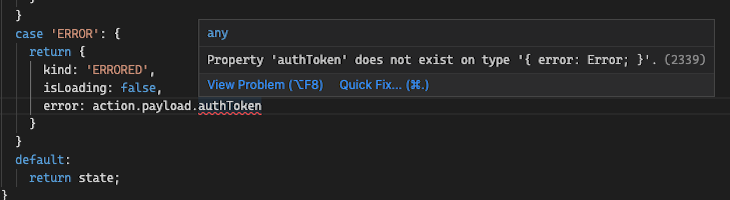
What is also nice about the above code is that isLoading is not an ambiguous boolean that could be wrongly assigned and introduce an error. The value can only be true in the AUTHENTICATING state. If the fields are only available to the current union member, then less test code is required.
ts-pattern instead of switch statementsSwitch statements are extremely limited and suffer from a fall-through hazard that can lead to errors and bad practices. Thankfully, several npm packages can help with type-narrowing discriminated unions, and the ts-pattern library is an excellent choice.
ts-pattern lets you express complex conditions in a single, compact expression akin to pattern matching in functional programming. There is a tc-39 proposal to add pattern matching to the JavaScript language, but it is still in stage 1.
After installing ts-pattern, we can refactor the code to something that resembles pattern matching:
const reducer = (state: AuthenticationStates, action: AuthActions) =>
match<AuthActions, AuthenticationStates>(action)
.with({ type: "AUTHENTICATING" }, () => ({
kind: "UNAUTHORISED",
isLoading: true
}))
.with({ type: "AUTHENTICATE" }, ({ payload: { authToken } }) => ({
kind: "AUTHENTICATED",
isLoading: false,
authToken
}))
.with({ type: "ERROR" }, ({ payload: { error } }) => ({
kind: "ERRORED",
isLoading: false,
error
}))
.otherwise(() => state);
The match function takes an input argument that patterns can be tested against and each with function defines a condition or pattern to test against the input value.
We’ve all written those horrible form validation functions that validate user input like the following:
function validate(values: Form<User>): Result<User> {
const errors = {};
if (!values.password) {
errors.password = 'Required';
} else if (!/^(?=.*?[A-Z])(?=.*?[a-z])(?=.*?[0-9])(?=.*?[#?!@$%^&*-]).{8,}$/i.test(values.password)) {
errors.password = 'Invalid password';
}
// etc.
return errors;
};
These validate functions require a lot of test code to cover all the various branching if statements that will inevitably multiply exponentially in the function bodies.
A better way is to analyze the data and create a type-safe schema that can execute against the incoming data at runtime. The excellent package Zod brings runtime semantics to TypeScript without duplicating existing types.
Zod allows us to define schemas that define the shape in which we expect to receive the data, with the bonus of being able to extract TypeScript types from the schema. We dodge a plethora of if statements and the need to write many tests with this approach.
Below is a simple UserSchema that defines four fields. The code calls z.infer to extract the User type from the schema, which is impressive and saves a lot of duplicated typing.
export const UserSchema = z.object({
uuid: z.string().uuid(),
email: z.string().email(),
password: z.string().regex(/^(?=.*?[A-Z])(?=.*?[a-z])(?=.*?[0-9])(?=.*?[#?!@$%^&*-]).{8,}$/),
age: z.number().optional()
});
export type User = z.infer<typeof UserSchema>;
/* returns
type User = {
uuid: string;
email: string;
password: string;
age?: number | undefined;
}
*/
When we parse instead of validate, we analyze the data, create a schema that can parse the data, and we get the types for free. This code is self-documenting, works at runtime, and is type-safe.
As a bonus, Zod comes with many out-of-the-box validations. For example, the uuid field will only accept valid UUID strings, and the email field will only accept strings correctly formatted as emails. A custom regex that matches the application password rules is given to the regex function to validate the password field. All this happens without any if statements or branching code.
I am not saying in this post that we should stop writing tests and put all our focus into writing better types.
Instead, we can use the type check function to check our logic directly against the application code — and in the process, we can write a hell of a lot less unit testing code in favor of writing better integration and end-to-end tests that test the whole system. By better, I do not mean we have to write a ton more tests.
Remember the golden rule: the more code you have, the more problems you have.

LogRocket lets you replay user sessions, eliminating guesswork by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks, and with plugins to log additional context from Redux, Vuex, and @ngrx/store.
With Galileo AI, you can instantly identify and explain user struggles with automated monitoring of your entire product experience.
Modernize how you understand your web and mobile apps — start monitoring for free.

A real-world debugging session using Claude to solve a tricky Next.js UI bug, exploring how AI helps, where it struggles, and what actually fixed the issue.

CSS wasn’t built for dynamic UIs. Pretext flips the model by measuring text before rendering, enabling accurate layouts, faster performance, and better control in React apps.

Why do real-time frontends break at scale? Learn how event-driven patterns reduce drift, race conditions, and inconsistent UI state.

Test out Auth.js, Clerk, WorkOS, and Better Auth in Next.js 16 to see which auth library fits your app in 2026.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

