GraphQL and REST are the two most popular architectures for API development and integration, facilitating data transmissions between clients and servers. In a REST architecture, the client makes HTTP requests to different endpoints, and the data is sent as an HTTP response, while in GraphQL, the client requests data with queries to a single endpoint.

In this article, we’ll evaluate both REST and GraphQL so you can decide which approach best fits your project’s needs.
Editor’s note: This article was last updated by Temitope Oyedele in March 2025 to include decision-making criteria for when to use GraphQL vs. REST, as well as to update relevant code snippets.
REST (Representational State Transfer) is a set of rules that has been the common standard for building web API since the early 2000s. An API that follows the REST principles is called a RESTful API.
A RESTful API helps structure resources into a set of unique uniform resource identifiers (URIs), which serve as addresses for different types of resources on a server. The URIs are used in combination with HTTP verbs, which tell the server what we want to do with the resource.
These verbs are the HTTP methods used to perform CRUD (Create, Read, Update, and Delete) operations:
POST: Means to createGET: Means to readPUT: Means to updateDELETE: Means to deleteSome requests, like POST and PUT, sometimes include a JSON or form-data payload that contains server-side information. The server processes the request and responds with an HTTP status code that indicates the outcome, which, most of the time, can include a response body containing data or details.
The HTTP status codes are as follows:
200-level: A request was successful400-level : Something was wrong with the request500-level : Something is wrong at the server level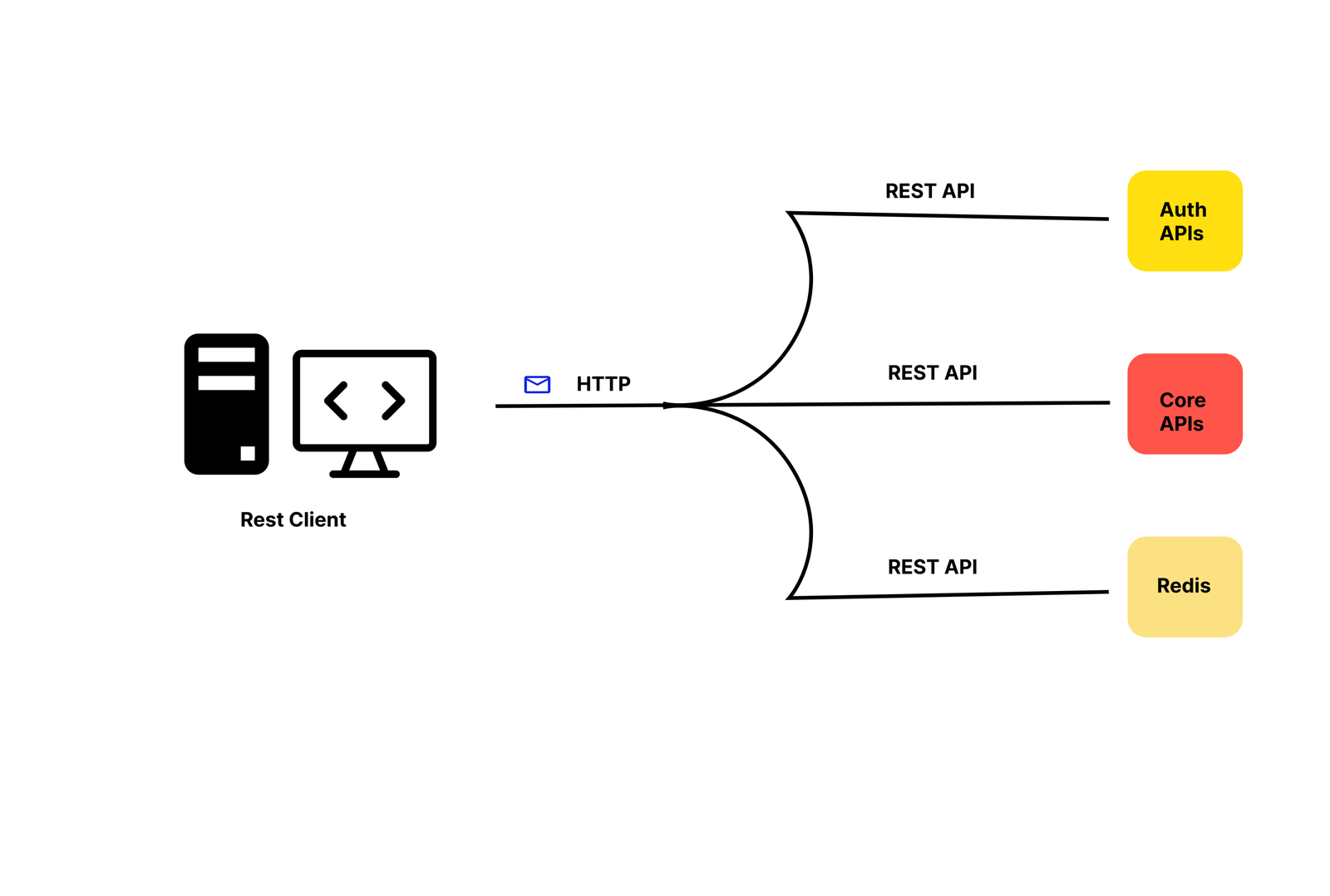
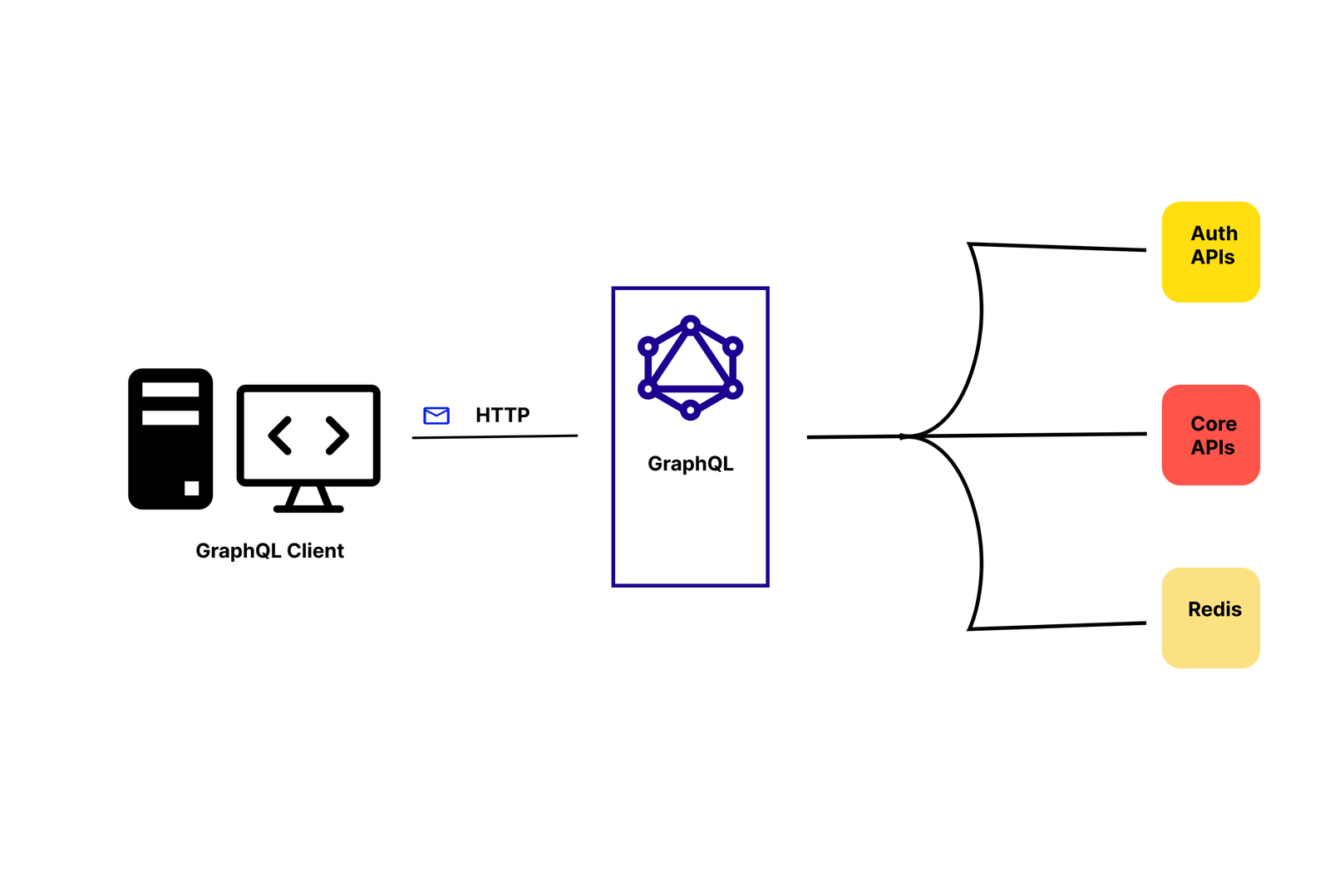
GraphQL is a query language developed by Meta. It provides a schema of the data in the API and gives clients the power to ask for exactly what they need.
GraphQL sits between the clients and the backend services. One cool thing about GraphQL is that it can aggregate multiple resource requests into a single query. It also supports mutations, which are GraphQL’s way of applying data modifications, and subscriptions, which are GraphQL’s way of notifying clients about data modifications during real-time communications:
REST centers around resources, each identified by a unique URL. For example, to fetch a single book resource, you might do:
GET /api/books/123
The response might look like this:
{
"title": "Understanding REST APIs",
"authors": [
{
"name": "John Doe"
},
{
"name": "Anonymous"
}
]
}
Some APIs can split related data into separate endpoints. For example, a different request might fetch the authors instead of including them in the main book response. The exact design depends on how the API is structured.
GraphQL, on the other hand, uses a single endpoint (e.g., /graphql) and lets clients query exactly the data they need in one request. You start by defining types, and then the client sends a query describing which fields to fetch. For example, after defining your Book and Author types, a query for the same book data could look like this:
query {
book(id: "123") {
title
authors {
name
}
}
}
The response contains only the requested fields:
{
"data": {
"book": {
"title": "Understanding GraphQL APIs",
"authors": [
{
"name": "John Doe"
},
{
"name": "Anonymous"
}
]
}
}
}
This approach reduces over-fetching and under-fetching since the client decides exactly which fields to request.
REST uses HTTP status codes for error handling and relies on standard HTTP methods (GET, POST, PUT, DELETE). It provides a variety of API authentication and encryption mechanisms, such as TLS, JWTs, OAuth 2.0, and API keys.
GraphQL uses a single endpoint and requires safeguards like query depth limiting, introspection control, and authentication to prevent abuse. While simpler in some ways, it can introduce complexity. As a developer, you’ll need to come up with some authentication and authorization methods to prevent performance issues and denial-of-service (DoS) caused by introspection.
REST has a rigid structure, as it can return unwanted data when over-fetched and insufficient data when under-fetched. This means you might need to make multiple calls, which increases the time required to retrieve the necessary information.
GraphQL, on the other hand, allows clients a lot of flexibility by giving the client exactly what is requested with a single API call. The client specifies the structure of the requested information and the server returns just that. This eliminates over-fetching and under-fetching issues and makes data fetching more efficient.
RESTful APIs adopt versioning to manage modifications on data structures and deprecations in order to avoid system failures and service disruptions for end users. This means you need to build versions for every change or update that you make, and if the number of versions grows, maintenance can become difficult.
GraphQL, on the other hand, reduces the need for versioning as it has a single versioned endpoint. It allows you to define your data requirements in the query. GraphQL manages updates and deprecations by updating and extending the schema without explicitly versioning the API.
REST is widely used across several industries. For example, platforms like Spotify and Netflix use RESTful APIs to access media from remote servers. Companies like Stripe and PayPal use REST to securely process transactions and manage payments. Other companies that use REST include Amazon, Google, and Twilio.
GraphQL’s popularity has grown in recent years and is now being used by companies and organizations. For example, GraphQL is using Meta, its creator, to solve the inefficiencies of RESTful APIs. Samsung also uses it for its customer engagement platform. Other companies that use GraphQL include Netflix, Shopify, Twitter, etc.
Because REST APIs are poorly typed, you need to implement error handling. This means using HTTP status codes to indicate the status or success of a request. For example, if a resource is not found, the server returns 404, and if there’s a server error, it returns a 500 Error.
GraphQL, on the other hand, always returns a 200 ok status for all requests regardless of whether they resulted in an error. The system communicates errors in the response body alongside the data, which requires you to parse the data payload to determine whether the request was successful.
REST doesn’t inherently provide type definitions, making it prone to runtime errors in client-side applications.
GraphQL ships with built-in type safety in its schema. Each field in the schema is typed, ensuring that clients know the exact structure and type of the data they will receive. This reduces runtime errors in client-side applications.
API technologies like REST would require multiple HTTP calls to access data from multiple sources.
On the other hand, GraphQL simplifies aggregating data from multiple sources or APIs and then resolving the data to the client in a single API call.
Below is a detailed comparison table summarizing their main differences:
| Feature | REST | GraphQL |
|---|---|---|
| Data fetching | May over-fetch or under-fetch data due to fixed endpoints | Fetches only the requested fields, reducing data transfer overhead |
| API schema | No strict schema enforcement by default | Uses Schema Definition Language (SDL) to enforce a strongly typed schema |
| Number of endpoints | Multiple endpoints for different resources | Single endpoint handling all queries and mutations |
| Caching | Built-in support with HTTP caching (CDN, browser, and proxy caching) | More complex; requires custom caching strategies |
| Error handling | Uses HTTP status codes (e.g., 404, 500) for clear error responses | Returns 200 OK even for errors; requires parsing the error object |
| Real-time updates | Requires WebSockets, polling, or SSE for real-time communication | Supports real-time subscriptions natively |
| Complex queries | Clients must make multiple requests to retrieve related data | Clients can request multiple related entities in a single query |
| Security | Easier to enforce role-based access and rate-limiting | Requires additional security measures, such as query complexity limits |
| Industry adoption | Still the dominant API standard in enterprise, finance, and healthcare | Gaining popularity in startups, ecommerce, and social media apps |
Each has its advantages and disadvantages, so the choice ultimately depends on your project’s needs. Do you want your project to be built based on performance, security, or flexibility? Once you’ve answered that, you can choose the one that best suits your project.
REST provides you with a scalable API architecture that powers millions of applications worldwide. It excels in simplicity, caching, and security, which makes it the go-to choice for public APIs, financial services, and enterprise applications.
Choose REST when:
GraphQL on the other hand, would give you full control over data fetching. It’s perfect for flexible, frontend-driven applications that require real-time updates and efficient API queries.
Choose GraphQL when:
Both GraphQL and REST offer distinct advantages. REST is used for most applications due to its simplicity and dependability, but GraphQL is best suited for modern, frontend-driven apps that require flexibility and efficiency. Knowing all of this will help you choose the right architecture for your project.
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Learn how to build smooth staggered animations in CSS using modern features like sibling-index(), complete with practical examples, fallbacks, and accessibility tips.

Compare the top AI development tools and models of July 2026. View updated rankings, feature breakdowns, and find the best fit for you.

Learn how to detect unused and ghost dependencies in JavaScript projects using Knip, a project-level linter that keeps your dependency graph accurate.

Learn how Storybook MCP enables AI agents to understand your component library, generate accurate UI, and validate code using documentation, stories, and automated tests.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

