Nested mutations provide the ability to perform mutations on a type other than the root type in GraphQL. For instance, this standard mutation executed at the top level:

mutation {
updatePost(id: 5, title: "New title") {
title
}
}
Could also be executed through this nested mutation on type Post:
mutation {
post(id: 5) {
update(title: "New title") {
title
}
}
}
As I’ve argued in my article “Coding a GraphQL server in JavaScript vs. WordPress,” nested mutations won’t become part of the GraphQL spec (even though they’ve been requested) because graphql-js (the reference GraphQL server implementation) will not support it.
If nested mutations were to be supported, the spec would need to eliminate the ability to resolve fields in parallel, which is too valuable to remove. The trade-off is not worth it, which is unfortunate because nested mutations make the schema less bloated and easier to understand. I believe that this is a benefit worth having, making nested mutations a compelling feature.
Now, not every programming language naturally supports resolution of fields in parallel, as JavaScript can offer through promises. In such cases, supporting nested mutations wouldn’t require the same trade-off as for graphql-js, and it could become feasible to implement.
GraphQL servers that support nested mutations must not use this feature to replace the standard behavior, but offer it as an alternative option:
As such, nested mutations must be made an opt-in feature so as to ensure the developer is aware that this is not standard GraphQL behavior, and that a query that works in this GraphQL server most likely will not work somewhere else.
Being opt-in, there is no harm in supporting this feature; it’s either a win or there’s no change.
The GraphQL API for WordPress is implemented in PHP. Because it does not use an event-driven library to resolve fields in parallel, it can support nested mutations without any drawbacks. In this article, I’ll describe how this server manages to support both the standard behavior expected by the GraphQL spec and nested mutations as an opt-in feature, using a single source of code.
QueryRoot and MutationRoot, or just RootFor the standard behavior, queries and mutations are handled separately through two different root types: the QueryRoot and the MutationRoot (these are my preferred names; they could also be named Query and Mutation, or something else). This separation enables us to execute the mutation fields from MutationRoot serially, while all other fields (those from QueryRoot, and from every other entity) can be resolved in parallel.
In this arrangement, MutationRoot is the only type in the whole GraphQL schema that can contain mutation fields. For instance, in the schema below, the mutation fields (createPost and updatePost) can only appear under MutationRoot:
type Post {
id: ID!
title: String
content: String
}
type QueryRoot {
posts: [Post]
post(id: ID!): Post
}
type MutationRoot {
createPost(title: String, content: String): Post
updatePost(id: ID!, title: String, content: String): Post
}
schema {
query: QueryRoot
mutation: MutationRoot
}
And the only way to update a post is like this:
mutation {
updatePost(id: 5, title: "New title") {
title
}
}
But this situation changes when introducing nested mutations, since then every single type could execute a mutation (not just the root type) and at any level of the query (not just at the top).
For instance, if adding a mutation field update to the Post:
type Post {
# previous fields
# ...
update(title: String, content: String): Post
}
We can then update the post also like this:
mutation {
post(id: 5) {
title
update(title: "New title") {
newTitle: title
}
}
}
Note: Please notice how field
Root.updatePostwas adapted asPost.update, and it doesn’t need receive theIDparam anymore, making the schema simpler.
We can also execute a mutation on the result from another mutation, as in the query below, where mutation Post.update is applied on the object created by mutation Root.createPost:
mutation {
createPost(title: "First title") {
id
update(title: "Second title", content: "Some content") {
title
content
}
}
}
In this context, type Post now contains both query and mutation fields (such as title for the former and update for the latter). I believe there is no way around it, for reasons I explain below.
Let’s say we want to replicate the idea of keeping two separate types to handle queries and mutations, as done through QueryRoot and MutationRoot, for all other types, too. The aim would be for all queries and mutations to be executed through their own separate branches, as to resolve the query fields in parallel and mutation fields serially, like this:
QueryRoot => Post => Comment => etc. for queriesMutationRoot => MutationPost => MutationComment => etc. for mutationsThen, we split the Post type into entities Post (to handle only queries) and MutationPost (to handle mutations). However, field post from the query below should then return type MutationPost instead of Post, so as to apply field update to its result:
mutation {
post(id: 5) {
update(title: "New title") {
newTitle: title
}
}
}
Then, we would need to duplicate every single field that returns Post (such as Root.post) to return MutationPost for the mutation branch (such as MutationRoot.post):
type QueryRoot {
posts: [Post]
post(id: ID!): Post
}
type MutationRoot {
posts: [MutationPost]
post(id: ID!): MutationPost
}
As a consequence, the schema would become bloated and unmanageable, defeating the purpose of introducing nested mutations to simplify the schema.
However, it gets even worse: this solution would not even work because type MutationPost can resolve field update but cannot resolve field title:
mutation {
post(id: 5) {
title
update(title: "New title") {
newTitle: title
}
}
}
Then, type Post must necessarily contain both query and mutation fields.
Now, since both query and mutation fields live side by side under the same type, then the MutationRoot type doesn’t make sense anymore, and we can well merge QueryRoot and MutationRoot into a single type Root, handling both query and mutation fields:
type Post {
id: ID!
title: String
content: String
update(title: String, content: String): Post
}
type Root {
posts: [Post]
post(id: ID!): Post
createPost(title: String, content: String): Post
updatePost(id: ID!, title: String, content: String): Post
}
schema {
query: Root
mutation: Root
}
In this situation, the schema got simpler. And it can get even leaner because we can remove the duplicate fields from the root type: since we have Post.update, we don’t need Root.updatePost anymore, and it can be pulled out from the schema.
By now, you may have a complaint: since they are mixed with query fields, mutations could be added to the query at any level and be executed at any moment.
For instance, this query:
query {
post(id: 1459) {
title
}
}
Could become this query:
query {
post(id: 1459) {
title
addComment(comment: "Hi there") {
id
content
}
}
}
And then, we may be executing a mutation when we originally intended to execute a query.
However, we can still use the operation types query and mutation to validate our intention. Then, the query above would produce an error, indicating that mutation addComment cannot be executed because the query is using operation type query:
{
"errors": [
{
"message": "Use the operation type 'mutation' to execute mutations",
"extensions": {
"type": "Post",
"id": 1459,
"field": "addComment(comment:"Hi there")"
}
}
],
"data": {
"post": {
"title": "A lovely tango, not with leo"
}
}
}
This query will instead work well:
mutation {
post(id: 1459) {
title
addComment(comment: "Hi there") {
id
content
}
}
}
Please notice that we are using operation type mutation even though there is no mutation anymore at the top level (only the post query field). That’s OK — since we’ve removed MutationRoot (replaced with Root), the expectations from the default behavior no longer apply.
As already mentioned, the server must support two behaviors:
As a consequence, it will expose types QueryRoot and MutationRoot by default and switch to exposing a single Root type for nested mutations.
When providing the resolvers, we wouldn’t want to require developers to provide two resolvers, one for each solution. It’s better that the same resolver used to resolve fields for Root can also resolve fields from QueryRoot and MutationRoot. To deal with this, the server would rather follow the code-first approach, as it can dynamically adapt the schema for either solution.
In Gato GraphQL — a CMS-agnostic server in PHP, over which the GraphQL API for WordPress is based — we can customize this behavior in the endpoint through param ?mutation_scheme and values standard, nested, or lean_nested (in which the duplicate mutation fields from the root, such as Root.updatePost, are removed).
For instance, the standard endpoint looks like this:
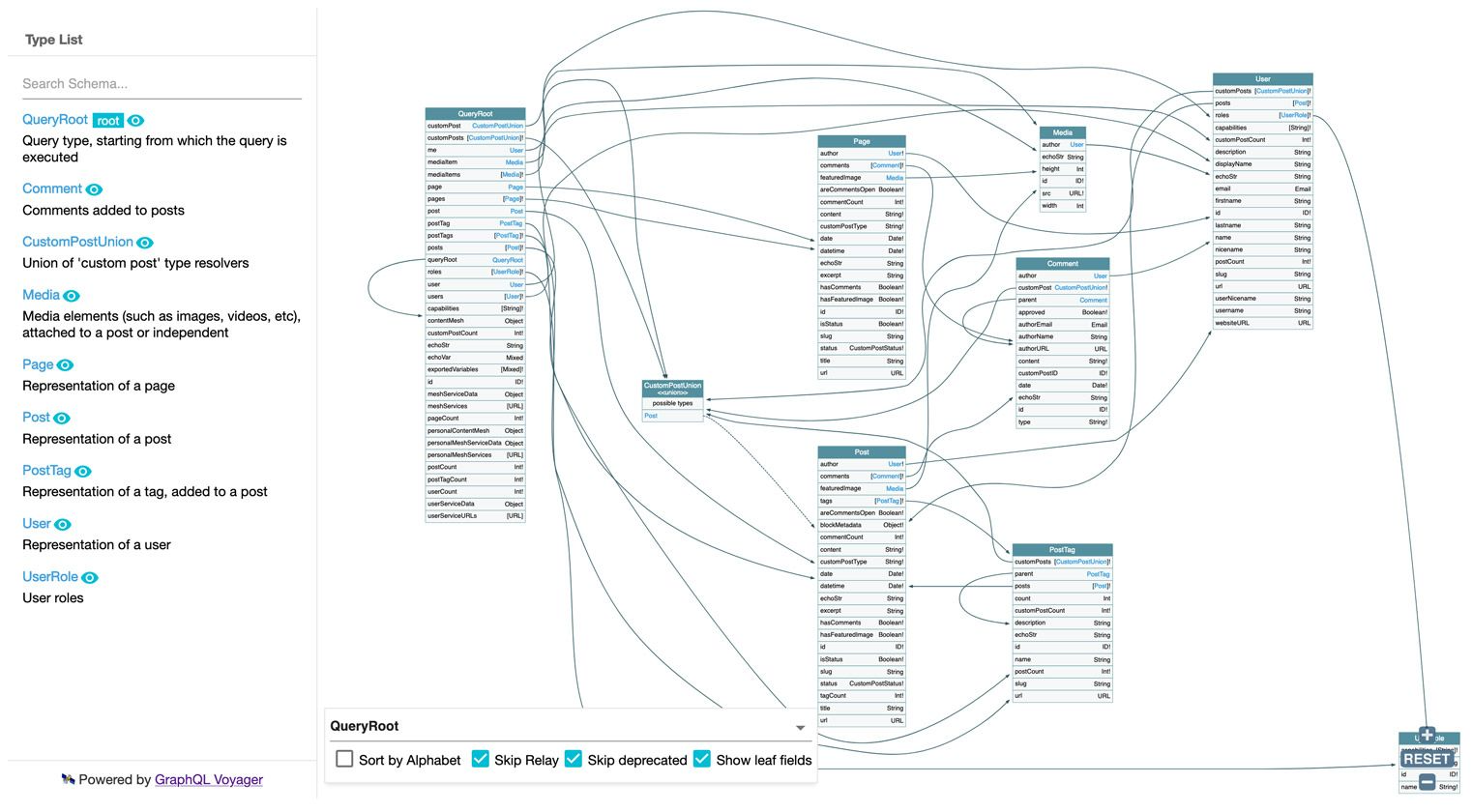
And the nested mutations endpoint looks like this:
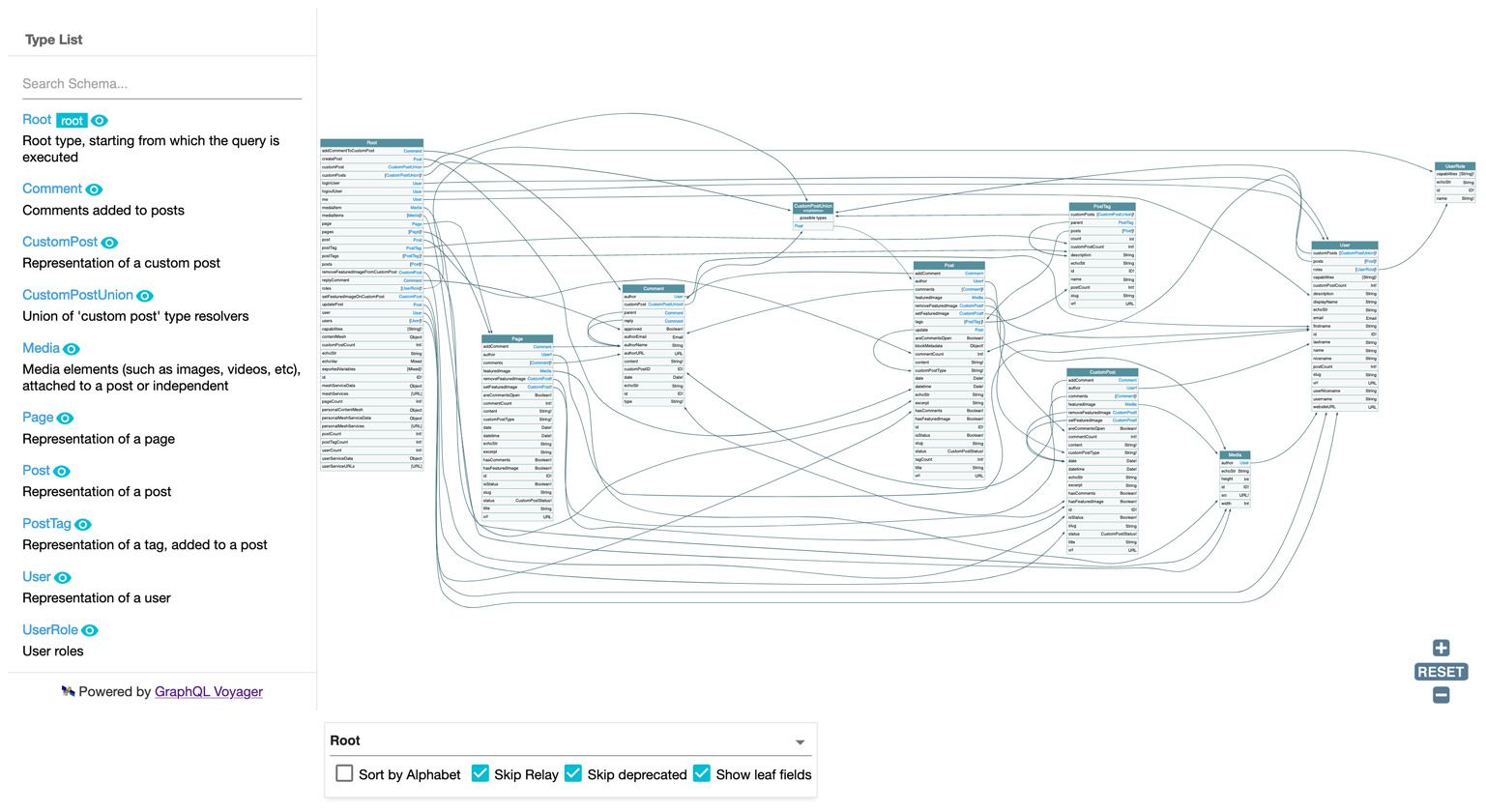
QueryRoot to Root and there are many more fields, belonging to mutations.The server uses an object called FieldResolver to resolve fields and an object called MutationResolver to execute the actual mutation. The same MutationResolver object can be referenced by different FieldResolvers implementing different fields, so the code is implemented only once and used in many places, following the SOLID approach.
We know whether a field is a mutation if the FieldResolver declares a MutationResolver object for that field, done through function resolveFieldMutationResolverClass.
For instance, field Root.replyComment provides object AddCommentToCustomPostMutationResolver. This same object is also used by field Comment.reply.
Furthermore, when coding the FieldResolver, the root fields are added to the Root type only. For the standard GraphQL behavior, the server can retrieve this configuration and automatically add these fields to either MutationRoot or QueryRoot depending on whether they are mutations or not.
As a result, since we are using a single source for the code powering both the standard behavior and nested mutations, we are able to execute queries with nested mutations at no extra effort.
In this query, we obtain the post entity through Root.post, then execute mutation Post.addComment on it and obtain the created comment object. Finally, we execute mutation Comment.reply on this latter object:
mutation {
post(id: 1459) {
title
addComment(comment: "Nice tango!") {
id
content
reply(comment: "Can you dance like that?") {
id
content
}
}
}
}
Producing this response:
{
"data": {
"post": {
"title": "A lovely tango, not with leo",
"addComment": {
"id": 117,
"content": "<p>Nice tango!</p>n",
"reply": {
"id": 118,
"content": "<p>Can you dance like that?</p>n"
}
}
}
}
}
If we want to execute a mutation on several objects, using the default behavior, we would need to duplicate the field so as to pass an ids param (to indicate the several objects on which to apply the mutation) instead of id.
For instance, if there is a field MutationRoot.likePost to “like” a post, then the field must be duplicated into MutationRoot.likePosts to “like” several posts at once:
type MutationRoot {
likePost(id: ID!): Post
likePosts(ids: [ID!]!): [Post]
}
Using nested mutations, though, mutating several fields at once can be done without any duplication. For instance, this query adds the same comment to several posts:
mutation {
posts(limit: 3) {
title
addComment(comment: "First comment on several posts") {
id
content
reply(comment: "Response to my own parent comment") {
id
content
}
}
}
}
Which produces this response:
{
"data": {
"posts": [
{
"title": "Scheduled by Leo",
"addComment": {
"id": 126,
"content": "<p>First comment on several posts</p>n",
"reply": {
"id": 129,
"content": "<p>Response to my own parent comment</p>n"
}
}
},
{
"title": "COPE with WordPress: Post demo containing plenty of blocks",
"addComment": {
"id": 127,
"content": "<p>First comment on several posts</p>n",
"reply": {
"id": 130,
"content": "<p>Response to my own parent comment</p>n"
}
}
},
{
"title": "A lovely tango, not with leo",
"addComment": {
"id": 128,
"content": "<p>First comment on several posts</p>n",
"reply": {
"id": 131,
"content": "<p>Response to my own parent comment</p>n"
}
}
}
]
}
}
Sweet!
Since a type now contains query and mutation fields, we may want to clearly visualize which is which — for instance, on the docs when using GraphiQL.
Unfortunately, because there is no isMutation flag available on type __Field when doing introspection, then the solution I’m using is a bit hacky and not completely satisfying. Here, we’re prepending label "[Mutation] " on the field’s description:
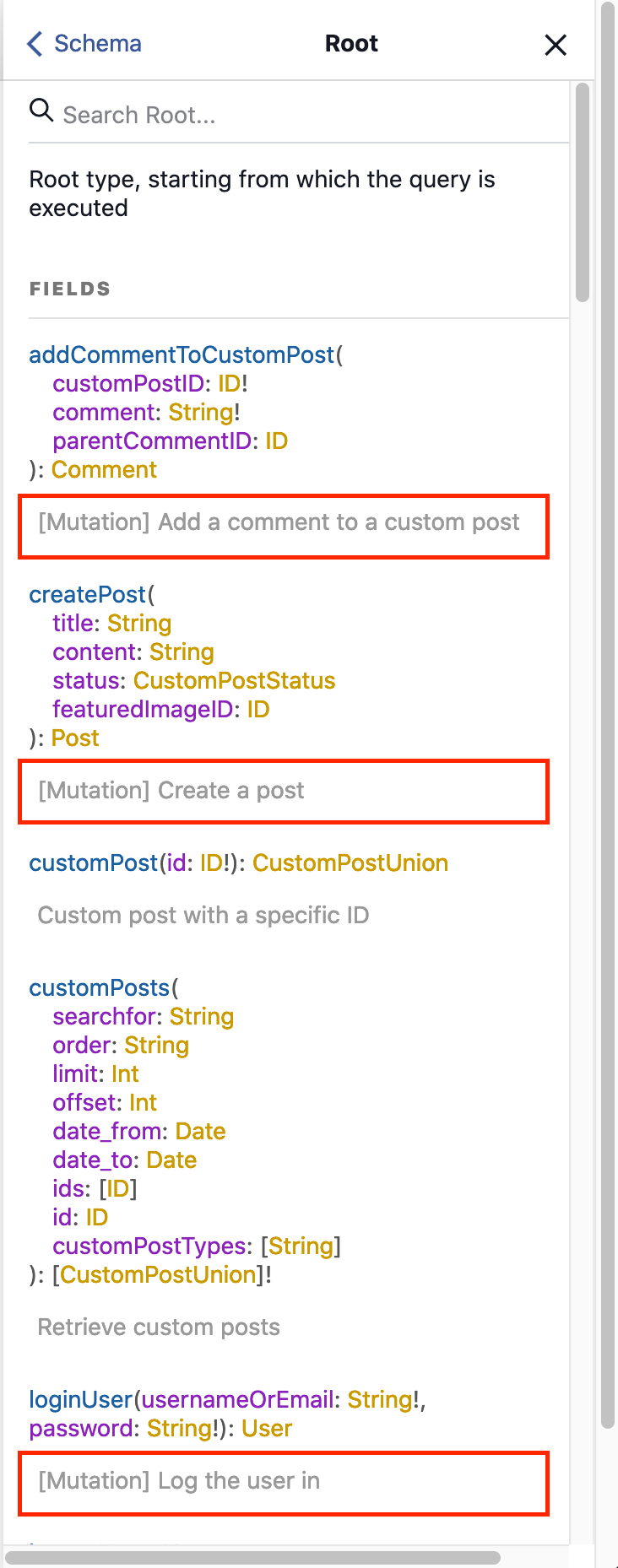
To make it a bit better, and to work with this data as if it were metadata (which it is), GraphQL API for WordPress has added an additional field extensions to type __Field (hidden from the schema) to retrieve the custom extension data, as done in this introspection query:
query {
__schema {
queryType {
fields {
name
# This field is not currently part of the spec
extensions
}
}
}
}
Which will produce these results (notice entries with isMutation: true):
{
"data": {
"__schema": {
"queryType": {
"fields": [
{
"name": "addCommentToCustomPost",
"extensions": {
"isMutation": true
}
},
{
"name": "createPost",
"extensions": {
"isMutation": true
}
},
{
"name": "customPost",
"extensions": []
},
{
"name": "customPosts",
"extensions": []
},
{
"name": "loginUser",
"extensions": {
"isMutation": true
}
}
]
}
}
}
}
Since supporting nested mutations in my GraphQL server, I find it difficult to go back to executing mutations from the top level.
The schema became slimmer and neater, without the MutationRoot packing fields that had nothing in common other than being mutations, and without duplicating fields for executing a mutation on several objects at once.
I can also execute nested operations as if I were browsing the relationships defined in the data model, as supported by GraphQL for querying.
Nested mutations are a wonderful feature. Unfortunately, since graphql-js can’t support them, they will (most likely) never be part of the spec. But that should not deter GraphQL servers from providing this feature as an opt-in, allowing developers to decide whether to enable it for their applications.
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Learn how to use Fallow to analyze AI-generated code, detect dead code, duplicate logic, and complexity issues, and integrate automated code quality checks into your AI-assisted development workflow.

Learn how to protect full-stack projects from NPM supply chain attacks with a practical security checklist.

Explore 15 essential MCP servers for web developers to enhance AI workflows with tools, data, and automation.

Learn how contrast-color() automatically picks accessible text colors using native CSS, without JavaScript.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

