The pressure is on. Every conference, every tech blog, every corner of the internet is buzzing with AI agents, autonomous workflows, and the promise of a revolution powered by large language models (LLMs). As a developer, it’s easy to feel like you need to integrate AI into every feature and deploy agents for every task.

But what if the smartest move isn’t to use AI, but to know when not to?
This isn’t a contrarian take for the sake of it; it’s a call for a return to engineering pragmatism. The current hype cycle often encourages us to reach for the most complex, exciting tool in the box, even when a simple screwdriver would do the job better. Just as you wouldn’t spin up a Kubernetes cluster to host a static landing page, you shouldn’t use a powerful, probabilistic LLM for a task that is, and should be, deterministic.
This post is a guide to cutting through the noise. We’ll explore why using AI indiscriminately is an anti-pattern, and lay out a practical framework for deciding when and how to use AI and agents effectively. All of this will help ensure you’re building solutions that are robust, efficient, and cost-effective.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Would you use a cloud-based AI service to solve 1 + 1? Of course not. It sounds absurd. Yet, many of the AI implementations I see today are the developer equivalent of that very question. We’re so mesmerized by what AI can do that we forget to ask if it should do it.
Using an LLM for a simple, well-defined task is a classic case of over-engineering. It introduces three significant penalties that deterministic, traditional code avoids.
API calls to powerful models like GPT-5 or Claude 4.5 are not free. Let’s say you need to validate if a user’s input is a valid email address. You could send this string to an LLM with a prompt like, “Is the following a valid email address? Answer with only ‘true’ or ‘false’.”
A simple regex in JavaScript, however, is free and executes locally in microseconds.
function isValidEmail(email) {
const regex = /^[^\s@]+@[^\s@]+\.[^\s@]+$/;
return regex.test(email);
}
Now, imagine this check runs on every keystroke in a form for thousands of users. The cost of the LLM approach quickly spirals from negligible to substantial. The regex remains free, forever.
Every API call to an LLM is a network round-trip. It involves sending your prompt, waiting for the model to process it, and receiving the response. For the user, this translates to noticeable lag.
Consider a simple data transformation: converting a string from snake_case to camelCase. A local function is instantaneous. An LLM call could take anywhere from 300 milliseconds to several seconds. In a world where user experience is paramount, introducing such a bottleneck for a trivial task is a step backward.
This is the most critical issue for developers. LLMs are probabilistic; your code should be deterministic. When you run a function, you expect the same input to produce the same output, every single time. This is the bedrock of reliable software.
LLMs don’t offer that guarantee. They can hallucinate or misinterpret context. If your AI-powered email validator suddenly decides a valid email is invalid, you have a bug that is maddeningly difficult to reproduce and debug. For core application logic, you need 100% reliability:
So, if we shouldn’t use AI for simple, deterministic tasks, what is it actually good for?
The answer is simple: use AI for problems that are difficult or impossible to solve with traditional code. LLMs excel where logic is fuzzy, data is unstructured, and the goal is generation or interpretation, not calculation.
The guiding principle should be: Use deterministic code for deterministic problems. Use probabilistic models for probabilistic problems.
This applies to both in-application logic and our own development processes.
Here are a few areas where integrating an LLM into your application is the right tool for the job:
Beyond integrating AI into your applications, remember its immense utility as a personal productivity tool. Using AI for these auxiliary tasks boosts your efficiency without introducing its probabilistic nature into your core application logic. You can use LLMs to:
The hype around AI gets even more intense when we talk about AI agents. An agent is often presented as a magical entity that can autonomously use tools, browse the web, and solve complex problems with a single prompt.
This autonomy is both a great strength and a significant risk. Letting an LLM decide which tool to use or determine next steps introduces another layer of non-determinism. What if it chooses the wrong tool? What if it gets stuck in a loop, burning through your budget?
Before jumping to a fully autonomous agent, we should look at a spectrum of patterns that offer more structure and reliability. In their excellent article, “Building effective agents,” the team at Anthropic draws a crucial architectural distinction:
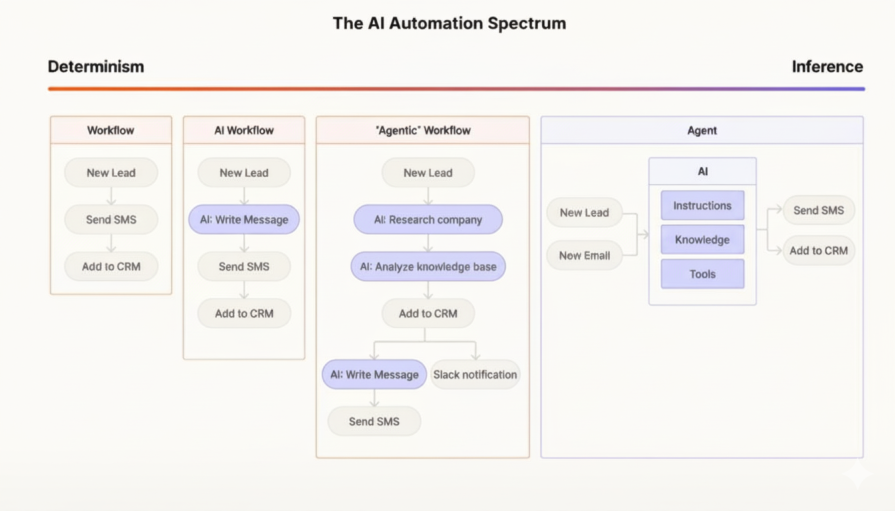
The key takeaway is to start with the simplest solution and only add complexity when necessary. The image below visualizes this spectrum, moving from predictable workflows to inference-driven agents:
Before building complex workflows, we need to understand the fundamental unit: what Anthropic calls the Augmented LLM. This isn’t just a base model; it’s an LLM enhanced with external capabilities. The two most important augmentations are:
These two building blocks—Tool Use and RAG—are the foundation upon which more sophisticated and reliable systems are built.
Now, let’s see how these building blocks can be assembled into the structured, predictable workflows that Anthropic recommends as alternatives to fully autonomous agents.
The simplest multi-step pattern. A task is broken down into a fixed sequence of steps, where the output of one LLM call becomes the input for the next. A step within this chain could absolutely involve the LLM using a tool or performing a RAG query.
In this pattern, an initial LLM call classifies an input and directs it to one of several specialized, downstream workflows. This is perfect for customer support, where you might route a query to a “refund process” (which uses a tool to access an orders database) or a “technical support” handler (which uses RAG to search documentation).
This workflow involves running multiple LLM calls simultaneously and aggregating their outputs. For instance, you could have one LLM call use RAG to find relevant policy documents while another call uses a tool to check the user’s account status.
A central “orchestrator” LLM breaks down a complex task and delegates sub-tasks to specialized “worker” LLMs, which in turn use the tools and retrieval capabilities necessary to complete their specific job.
This creates an iterative refinement loop. One LLM call generates a response, while a second “evaluator” LLM provides feedback. The first LLM then uses this feedback to improve its response. The evaluator’s criteria could be informed by information retrieved via RAG.
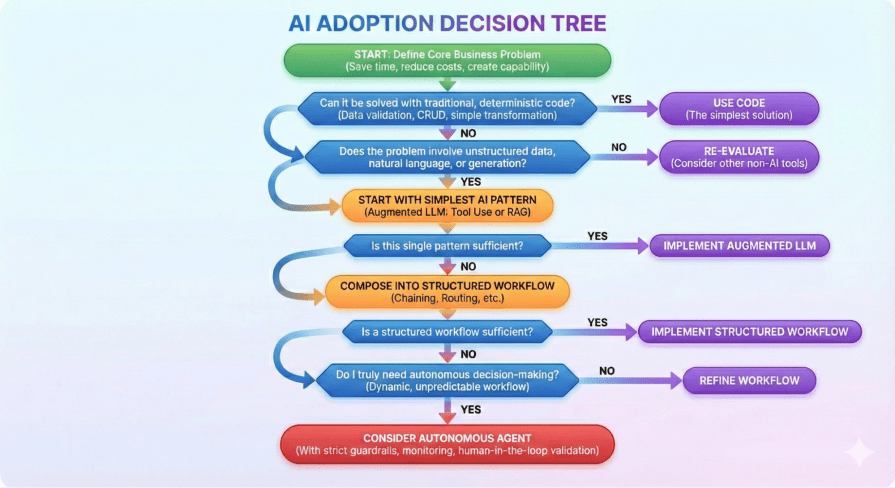 Before you write
Before you write import openai, pause and ask yourself a few questions. The goal is not to use AI; the goal is to solve a problem efficiently.
Being a great developer isn’t about chasing every new trend. It’s about building robust, efficient, and valuable software. AI and agents are incredibly powerful tools, but they are just that: tools. True innovation comes from knowing your toolbox inside and out and picking the right tool for the job.
Focus on the customer’s pain points. Solve them in the most efficient and reliable way possible. Sometimes that will involve a cutting-edge LLM, but often, it will be a simple, elegant piece of deterministic code. That is the path to building things that last.

A step-by-step guide to building your first MCP server using Node.js, covering core concepts, tool design, and upgrading from file storage to MySQL.

Using security headers in your Next.js apps is a highly effective way to secure websites from common security threats.

A deep dive into April 2026’s AI model and tool rankings. We break down performance, usability, pricing, and real-world capabilities across 50+ features to help you pick the right tools for your development workflow.

A practical guide to Agent Browser CLI. Learn how AI agents navigate, snapshot, and interact with web pages using stable references, enabling efficient automation and exploratory testing.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

