
In my last blog post, Redux Logging in Production, I discussed one of the most important benefits of using Redux — debuggability. By using front end logging tools like LogRocket, developers can easily understand and fix tricky bugs in production by reviewing the actions and state changes leading up to a bug.
While this information is immediately useful in any Redux app, there is a lot more we can achieve by architecting an app with logging in mind. In this post I’m going to look at a few libraries and abstractions that make Redux logs even more useful by putting as much application data through Redux as possible.
Fetching/sending data over the network is one of the most bug-prone parts of any app. Issues can arise from connectivity, unexpected data or incorrect logic. And things get extra complicated with polling, retry logic, optimistic mutations, etc.
Libraries like apollo-client for GraphQL, and redux-query for REST both facilitate fetching data from the network via Redux. They use Redux as a persistence layer, meaning that when debugging issues, you can inspect your Redux logs to see what data these clients have fetched and what the status is of in-flight requests.
Lets take a look at the Redux logs generated by redux-query:
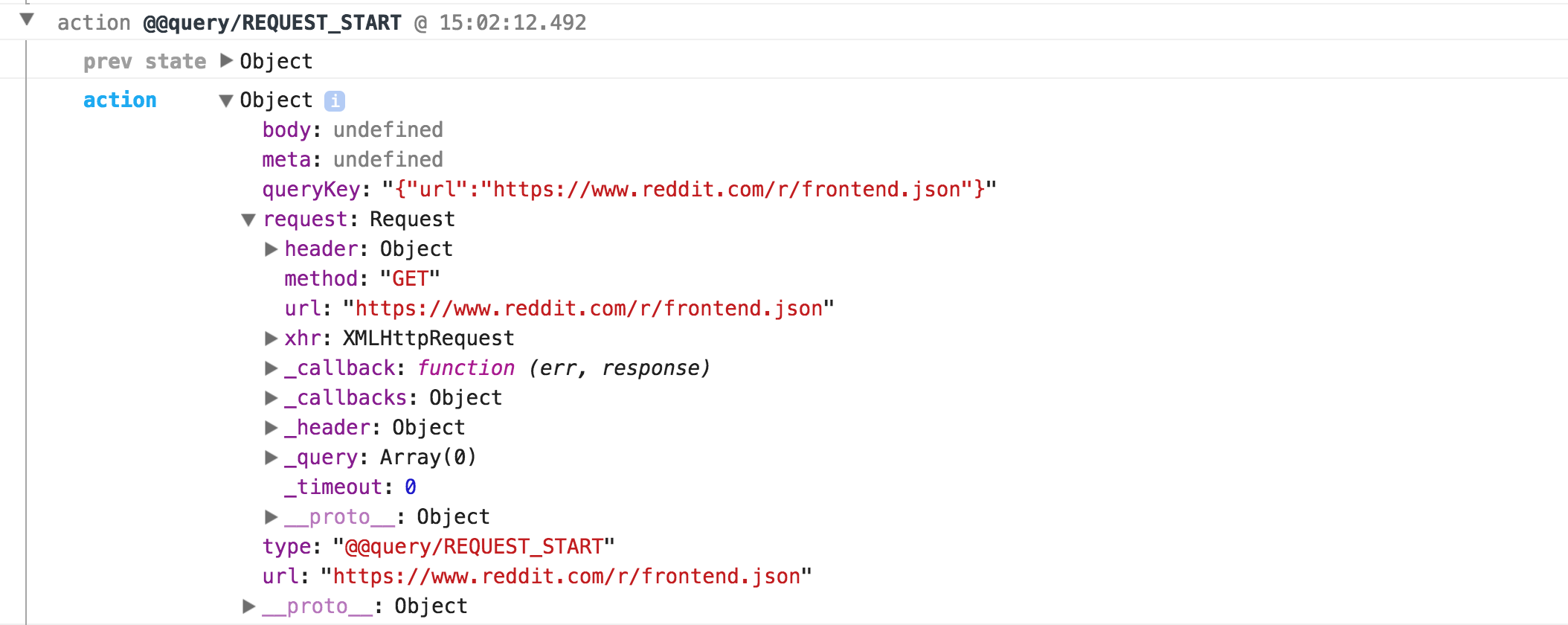
Here we see the REQUEST_START action, which corresponds with a query being initialized. Looking at the action payload, we see all the information in the request, making it easy to debug. Once a response is received, redux-query emits a REQUEST_SUCCESS action with all the information about the response.
Logging requests and responses is only part of the magic of redux-query. Digging into the store we see a key queries which is where redux-query persists its internal state.
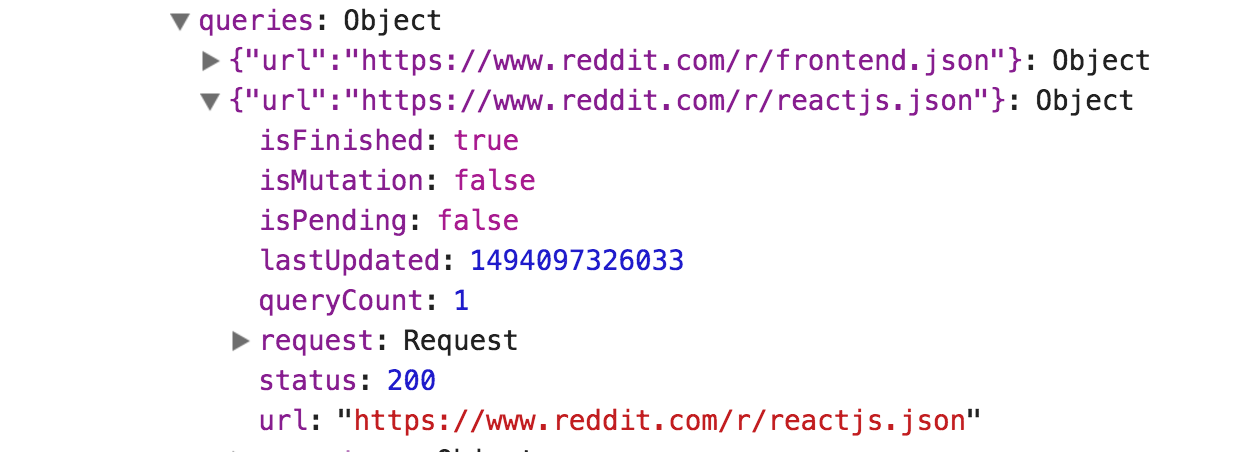
Above, we see objects for each of the queries the app carried out (one to reddit.com/r/frontend.json and one to reddit.com/r/reactjs.json). When debugging issues, we can dig into this state object to see information on in-flight requests, queryCount (if we’re polling on a query), and timings.
Storing this information in Redux is critical, since it puts full context on all network activity in the Redux logs.
If you’d prefer a simpler approach, you can roll your own data fetching “framework” by simply dispatching explicit actions when querying and receiving data from the network.
For example, lets say we’re building a blogging app. When querying for posts, we would dispatch POSTS_QUERY_INIT. The reducer could then update the state appropriately to indicate that the posts query is in progress.
postsQuery: {
url: 'api.blog.com/posts',
isPending: true,
...
}
In a thunk or saga, we would call fetch and when the promise resolves, we’d dispatch an action like POSTS_QUERY_SUCCESS or POSTS_QUERY_FAILURE. This would then update state appropriately to:
postsQuery: {
url: 'api.blog.com/posts',
isPending: true,
data: [...],
}
This example is far from thorough, but the idea is that by being explicit with Redux actions for each part of the request lifecycle, it becomes easy to debug any potential race condition or network error.
Using libraries and patterns that put data through Redux helps build more debuggable applications by leaving a rich audit trail.
When architecting a new feature, ask yourself if it might be error-prone, and whether being able to view its state in the Redux logs would help solve a future bug.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now
Discover how the Interface Segregation Principle (ISP) keeps your code lean, modular, and maintainable using real-world analogies and practical examples.

<selectedcontent> element improves dropdowns

Learn how to implement an advanced caching layer in a Node.js app using Valkey, a high-performance, Redis-compatible in-memory datastore.

Learn how to properly handle rejected promises in TypeScript using Angular, with tips for retry logic, typed results, and avoiding unhandled exceptions.

