Oh, no — not another article comparing REST with GraphQL. I feel you!

In the last couple years, we’ve been flooded with blog posts, Twitter threads, and conference talks comparing REST with GraphQL. And while it’s true that we’ll make some comparisons in this article, I’m going to try to focus on a different aspect of this topic, something that is often overlooked when we build our services: the human-friendliness of GraphQL.
Say what?!
One of the biggest hidden benefits of GraphQL is its attractiveness to less technical people. It can open a whole new world of possibilities by making data more accessible to everyone around us. So in this article, we’re going to see which characteristics of GraphQL can make our services more human, and how that compares with the more traditional REST approach.
You might be thinking, “What’s the problem with REST? I can understand it perfectly!” And I agree with that to some extent, but bear with me for the next five minutes and let’s see if we can identify some of these “problems” with some more specific examples.
The weather is getting warmer for many of us in the northern hemisphere, so what could we enjoy more than some refreshing ice cream? (To be honest, I think ice cream is great at any time in the year, but that might just be me!)
One of my biggest problems is that I never know which flavor should I get… Sometimes I want something more decadent, other times something more healthy, sometimes I fancy fruity ice cream, others a more chocolatey one, not to mention that I often have friends around with allergies so I need to look out for stuff like nuts or gluten.
So many things to consider! How can we build something together to help with the decision?
Fortunately, my favorite brand of ice cream has a public API (I wish!) that we can use to help make these decisions. But before we start thinking about this new application, let’s pause for a second and have a quick refresher about what an API is.
In this amazing visual explanation from Maggie Appleton, she describes an API as tiny robot-waiters that serve the data between different systems. Go ahead and take a minute to go through that so we’re all on the same page.
One thing we can already see is that for non-technical people, an API immediately feels distant and cold like a robot, not warm and welcoming like humans (at least most of us). We’ll talk about this later in the article, but for now, let’s get back to our tasty ice cream API.
The objective is to get a list of ice cream flavors with information about the allergens in each one. To start with our little tool, we need to know which flavors are available, so we’ll begin by querying the /api/flavors/ endpoint.
When we do that, it returns a list of all the flavors made by the brand, something like this:
[
{
id: 1,
name: "Peanut Butter Cup",
code: "BNJ-5345",
description: "Peanut Butter Ice Cream with Peanut Butter Cups",
isAvailable: true,
},
{
id: 2,
name: "Cookie Dough",
code: "BNJ-6537",
description: "Vanilla ice cream with chunks of chocolate chip cookie dough and chocolatey chunks",
isAvailable: false,
},
...
]
For the purposes of this article, let’s just focus on the first two flavors, although you can hope assume there will be many more of them in the response.
There are a couple things that stand out (besides wanting to stuff my mouth with every single option): some relevant information is missing (like the list of ingredients), and at the same time, there’s other information that we don’t really care about (like the internal code).
💾 Let’s save both of those points to a list so we can expand on them later.
Next, we want to find more details about each of the flavors, which we can do by hitting the /api/flavors/:id endpoint. Using the /api/flavors/1 call, we get the details about the first flavor:
{
id: 1,
name: "Peanut Butter Cup",
code: "BNJ-5345",
description: "Peanut Butter Ice Cream with Peanut Butter Cups",
marketingText: "We kid you not. This is no peanut-buttery illusion… It is a tub of Peanut Butter Cup. Yep, this wonderful flavour has made its way across the pond from our U.S. creation station… & it’s thanks to you! You've been asking us to bring peanut butter over here, so here you have it, and with peanut butter ice cream & a whole host of peanut butter cup chunks for you to uncover, this certainly packs a peanut-buttery punch!",
isAvailable: true,
ingredients: [2, 5, 10, 23],
sizes: ["mini", "regular"],
sources: [4, 10, 42]
}
We get back a lot more information from the API, which is great, but there seem to be some identifiers for other resources — like the ingredients — that we don’t know how to get at this point.
After searching for the documentation on the web, we learn that to get more details about each ingredient, we need to use a different endpoint at /api/ingredients/:id.
This means that we now have to keep track of two different endpoints to get the information we want, and that number may even increase if we need some information about the sources later.
💾 Let’s save these two “problems” in our list as well.
We need to get the details about the list of ingredients, and we now know that we need to use a new endpoint, so for each one of them, we make a separate call to /api/ingredients/:id.
This is what we get back from the /api/ingredients/2 request, for example:
{
id: 2,
name: "Cream",
code: "BNJ-9875",
amount: 21,
isFairtrade: false,
allergens: [4],
}
With this information, we know that the ingredient with ID 2 is “cream,” and that it makes up 21 percent of the final product. One thing we still don’t know yet is which allergen it contains, so we need to make another call to a new API endpoint at /api/allergens/4 to find out that it contains milk.
This seems to not only require many different API calls, as we’ve previously seen, but also exposes the complexity of the API relationships between the different resources. This might be fine when APIs are used by machines, but it makes it really hard for any human to get the information they actually need (what’s the ingredient with ID 10?).
💾 A couple more “problems” added to our list!
And we’re done! We know how to get all the information we need to build our little tool, and here’s the code we used:
const getFlavorsWithAllergens = async () => {
const baseUrl = "http://some.api.endpoint/api";
const getFlavors = () => fetch(`${baseUrl}flavors`).then(res => res.json());
const getFlavor = id =>
fetch(`${baseUrl}flavors/${id}`).then(res => res.json());
const getIngredient = id =>
fetch(`${baseUrl}ingredients/${id}`).then(res => res.json());
const getAllergen = id =>
fetch(`${baseUrl}allergens/${id}`).then(res => res.json());
const flavors = await getFlavors();
const flavorsWithDetails = await Promise.all(
flavors.map(flavor => getFlavor(flavor.id))
);
const flavorsWithIngredients = await Promise.all(
flavorsWithDetails.map(async flavor => {
return {
...flavor,
ingredients: await Promise.all(
flavor.ingredients.map(ingredient => getIngredient(ingredient))
)
};
})
);
return await Promise.all(
flavorsWithIngredients.map(async flavor => {
return {
...flavor,
ingredients: await Promise.all(
flavor.ingredients.map(async ingredient => ({
...ingredient,
allergens: await Promise.all(
ingredient.allergens.map(allergen => getAllergen(allergen))
)
}))
)
};
})
);
};
We need to do all of this work (does that feel approachable to non-technical people?) just to get to this information (which has much more data than we wanted):
[
{
id: 1,
name: "Peanut Butter Cup",
code: "BNJ-5345",
description: "Peanut Butter Ice Cream with Peanut Butter Cups",
marketingText: "We kid you not. This is no peanut-buttery illusion… It is a tub of Peanut Butter Cup. Yep, this wonderful flavour has made its way across the pond from our U.S. creation station… & it’s thanks to you! You've been asking us to bring peanut butter over here, so here you have it, and with peanut butter ice cream & a whole host of peanut butter cup chunks for you to uncover, this certainly packs a peanut-buttery punch!",
isAvailable: true,
ingredients: [
{
id: 2,
name: "Cream",
code: "BNJ-9875",
amount: 21,
isFairtrade: false,
allergens: [
{
id: 4,
name: "Milk",
group: "Dairy",
code: "BNJ-1223"
}
],
},
{
id: 5,
name: "Cocoa",
code: "BNJ-9867",
amount: 5,
isFairtrade: true,
allergens: [],
},
{
id: 10,
name: "Sugar",
code: "BNJ-9854",
amount: 15,
isFairtrade: true,
allergens: [],
},
{
id: 23,
name: "Peanuts",
code: "BNJ-9844",
amount: 9,
isFairtrade: false,
allergens: [
{
id: 16,
name: "Peanuts",
group: "Nuts",
code: "BNJ-1212"
}
],
}
],
sizes: ["mini", "regular"],
sources: [4, 10, 42]
},
...
]
📔 To recap, let’s see what we’ve saved in the list of “problems” we detected:
Of course, this is a very contrived example, and we could have a much better-structured REST API. But I’m sure you’ve all experienced something similar at least a few times in the past, so it isn’t that uncommon to bump into these issues every now and then.
What is especially relevant is that these are all issues that put barriers in front of the people trying to use the services, making it very challenging for anyone without a considerable amount to technical knowledge.
Before we move any further, I’ve created a dummy GraphQL playground that we can all use as we go through this section:
This is mostly to show the capabilities of GraphQL, and it won’t return any relevant data (only the first flavor, as shown above). If you’re new to GraphQL (or in need of a quick refresher), make sure you also check Maggie’s illustrated intro to GraphQL.
One of the unique features of GraphQL is that it promotes the use of a single endpoint for the entire API. This has the immediate benefit of reducing the cognitive load for anyone using the API since they only need to be aware of one endpoint to get all the data they need.
Not a big problem, but we’ve got to start somewhere, right?
📔 One down, five to go!
This time we’re going to solve three problems in one go!
Two very common problems with REST APIs are the relevant information missing from the response (usually referred to as under-fetching) and the irrelevant information present in the response (referred to as over-fetching).
GraphQL solves this by being a declarative language, which means we need to explicitly describe what information we want. This can be very annoying at times, but it’s a small sacrifice for knowing precisely what the API will return at any point.
This makes GraphQL a much better contract between clients and servers, as each side knows exactly what data the other expects and can optimize for that.
Let’s say we just wanted to get the names of the different flavors. In GraphQL, we could do this:
{
flavors {
name
}
}
Which will return this data:
{
"data": {
"flavors": [
{
"name": "Peanut Butter Cup"
}
]
}
}
Simple, right? You can go ahead and try it yourself in the playground, and maybe request the description as well!
This also significantly reduces the cognitive load and that overwhelming feeling most of us would get if we received a huge amount of data when requesting for a simple thing.
On the other hand, we also experience some under-fetching: we don’t get all the information we need from the initial request and have to make additional calls to get the details about each flavor, and then each ingredient, and then each allergen.
With GraphQL, we can combine all the different requests into the same schema, making it seamless to the user and abstracting the complexity of the system away from the people who want to use it.
Take this example:
{
flavors {
name
ingredients {
name
amount
}
}
}
Which returns this data:
{
"data": {
"flavors": [
{
"name": "Peanut Butter Cup",
"ingredients": [
{
"name": "Cream",
"amount": 21
},
{
"name": "Cocoa",
"amount": 5
},
{
"name": "Sugar",
"amount": 15
},
{
"name": "Peanuts",
"amount": 9
}
]
}
]
}
}
We know that this is using three separate API endpoints and making at least six calls in the background, but all of those details are hidden from the user, removing more barriers for those with no technical background.
As a side note, just like REST, GraphQL can also be a victim of the “n+1 problem” in which there are lots of chained requests in the same query. If we think we could get a list of 10 different flavors, we could end up with over 100 requests just for a single query, although there are some known strategies in GraphQL to minimize the impact of this type of query.
📔 We’re down to two problems!
Another huge benefit of using GraphQL is its self-documenting capabilities. This is possible because GraphQL is a strongly typed language, so we can navigate through all the possible relationships between resources before we even know what we’re going to need.
It also gives us some useful helpers like auto-completing/suggesting fields as we type our queries:
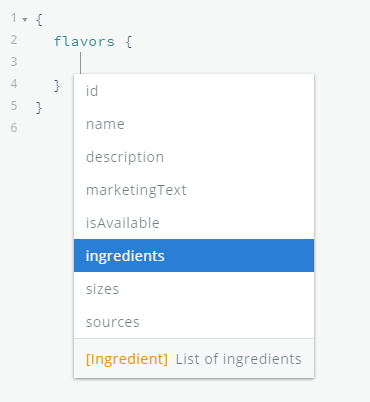
This is extremely important to make a service like this usable by all kinds of people. GraphQL editors will be able to guide users through the data structure and get the information they need even when they don’t have a clear idea of what’s actually possible in the API.
Remember our initial objective? We wanted to get a list of ice cream flavors with the information about the allergens in each one, so let’s see what the GraphQL version looks like:
{
flavors {
name
ingredients {
name
amount
allergens {
name
group
}
}
}
}
Wait — is that it?
Yup, not only it is substantially more readable and intuitive for humans, but it also doesn’t require any technical knowledge to be able to understand what’s going on. You can try that in the playground and see what comes back!
Oh, and we’re just getting the information we actually need, not everything that the REST API developers thought would be good to store on each resource.
📔 And GraphQL saves the day!
Phew, that was intense! To make it easier to digest all of this information, I’m going to leave you a few concrete action points to make your systems more human-friendly with GraphQL.
Even in more complex architectures, consider using schema stitching or federated schema to keep it to a single graph.
Why? This reduces the cognitive load of having to know many different endpoints and their specific uses. It also enhances the discoverability, as people will always be pointed to the same place regardless of what they are looking for.
Those tiny robot machines can handle the REST APIs just fine, but use GraphQL as an opportunity to rethink the way your data is connected. See how people are using the existing services and find behaviors and patterns that you can improve with a different data structure.
Why? Hiding the complexity of a system lowers the entry barrier for everyone and makes it more understandable to the people using it. Having a data structure that better fits users’ needs makes the system more approachable and relevant to them.
On a similar note, you can think of a GraphQL service as an extension of the existing services. In many cases, GraphQL APIs are built on top of existing REST APIs, providing a different way to access the same data. You can think of GraphQL as the smart human waiter who uses tiny robots to get the data people need in an optimized way.
Why? This approach makes it easier to start using a GraphQL service without affecting any of the existing APIs. This means you can start with a small schema and continue to build on top of that as people use it.
Finally, don’t forget that the language and the ecosystem around GraphQL already gives you lots of tools to make your GraphQL service more human-friendly, like adding proper descriptions to each field. Consider a public playground, generating documentation automatically, or even showing a more visual way to navigate through the data.
Why? Different people have different ways of understanding a system — some are more visual, others more practical. By providing different tools to navigate through the data, you’re expanding the reach of your service and empowering those using it.
Want a very real example of these principles in action?
Head to figma-graphql.com to see how I built a human-first GraphQL service on top of the amazing Figma REST API. You can see most of these points in action as I combined the multiple endpoints and spent a lot of time finding real use cases for the existing API, for example.
One of the main differences with the REST API is that the data structure better suits the mind of a non-technical person, and there are a bunch of shortcuts and helpers that improve the experience of getting information from a Figma file.
And that’s it! Thanks for reading and if you have any feedback you can always find me on Twitter.
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

I migrated 20 production-style components from Tailwind to StyleX. Here’s what the data showed about LOC, CSS bundle size, build time, and type safety.

A guide for using JWT authentication to prevent basic security issues while understanding the shortcomings of JWTs.

Discover how to build, render, and automate product demo videos with Remotion, replacing traditional screen recordings with reusable React code.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

