Editor’s Note: This post was updated in September 2021 with relevant information and edited code blocks.

Let’s talk about how we handle errors. JavaScript provides us with a built-in language feature for handling exceptions. We wrap potentially problematic code in try...catch statements. This lets us write the “happy path” in the try section and then deal with any exceptions in the catch section.
This is not a bad thing. It allows us to focus on the task at hand, without having to think about every possible error that might occur. It’s definitely better than littering our code with endless if statements.
Without try...catch, it gets tedious checking the result of every function call for unexpected values. Exceptions and try...catch blocks serve a purpose, but they have some issues, and they are not the only way to handle errors. In this article, we’ll take a look at using the Either monad as an alternative to try...catch.
A few things before we continue. In this article, we’ll assume you already know about function composition and currying. If you need a minute to brush up on those, that’s totally OK. And a word of warning, if you haven’t come across things like monads before, they might seem really… different. Working with tools like these takes a mind shift.
Don’t worry if you get confused at first. Everyone does. I’ve listed some other references at the end that may help. But don’t give up. This stuff is intoxicating once you get into it.
try...catch blocks in JavaScriptBefore we go into what’s wrong with exceptions, let’s talk about why they exist. There’s a reason we have things like exceptions and try…catch blocks. They’re not all bad all of the time.
To explore the topic, we’ll attempt to solve an example problem. I’ve tried to make it at least semi-realistic. Imagine we’re writing a function to display a list of notifications. We’ve already managed (somehow) to get the data back from the server. But, for whatever reason, the backend engineers decided to send it in CSV format rather than JSON. The raw data might look something like this:
timestamp,content,viewed,href 2018-10-27T05:33:34+00:00,@madhatter invited you to tea,unread,https://example.com/invite/tea/3801 2018-10-26T13:47:12+00:00,@queenofhearts mentioned you in 'Croquet Tournament' discussion,viewed,https://example.com/discussions/croquet/1168 2018-10-25T03:50:08+00:00,@cheshirecat sent you a grin,unread,https://example.com/interactions/grin/88
Now, eventually, we want to render this code as HTML. It might look something like this:
<ul class="MessageList">
<li class="Message Message--viewed">
<a href="https://example.com/invite/tea/3801" class="Message-link">@madhatter invited you to tea</a>
<time datetime="2018-10-27T05:33:34+00:00">27 October 2018</time>
<li>
<li class="Message Message--viewed">
<a href="https://example.com/discussions/croquet/1168" class="Message-link">@queenofhearts mentioned you in 'Croquet Tournament' discussion</a>
<time datetime="2018-10-26T13:47:12+00:00">26 October 2018</time>
</li>
<li class="Message Message--viewed">
<a href="https://example.com/interactions/grin/88" class="Message-link">@cheshirecat sent you a grin</a>
<time datetime="2018-10-25T03:50:08+00:00">25 October 2018</time>
</li>
</ul>
To keep the problem simple, for now, we’ll just focus on processing each line of the CSV data. We start with a few simple functions to process the row. The first one we’ll use to split the fields:
function splitFields(row) {
return row.split(',');
}
Now, this function is oversimplified because this is a tutorial about error handling, not CSV parsing. If there’s ever a comma in one of the messages, this will go horribly wrong. Please do not ever use code like this to parse real CSV data. If you ever do need to parse CSV data, please use a well-tested CSV parsing library, such as Papa Parse.
Once we’ve split the data, we want to create an object where the field names match the CSV headers. We’ll assume we’ve already parsed the header row. Note that we throw an error if the length of the row doesn’t match the header row (_.zipObject is a lodash function):
function zipRow(headerFields, fieldData) {
if (headerFields.length !== fieldData.length) {
throw new Error("Row has an unexpected number of fields");
}
return _.zipObject(headerFields, fieldData);
}
After that, we’ll use the Internationalization API to add a human-readable date to the object, so that we can print it out in our template. Note that it throws an error for an invalid date:
function addDateStr(messageObj) {
const errMsg = 'Unable to parse date stamp in message object';
const d = new Date(messageObj.datestamp);
if (isNaN(d)) {
throw new Error(errMsg);
}
const datestr = Intl.DateTimeFormat('en-US', {year: 'numeric', month: 'long', day: 'numeric'}).format(d);
return {datestr, ...messageObj};
}
Finally, we take our object and pass it through a template function to get an HTML string:
const rowToMessage = _.template(`<li class="Message Message--<%= viewed %>"> <a href="<%= href %>" class="Message-link"><%= content %></a> <time datetime="<%= datestamp %>"><%= datestr %></time> <li>`);
If we end up with an error, it would also be nice to have a way to print that too:
const showError = _.template(`<li class="Error"><%= message %></li>`);
And once we have all of those in place, we can put them together to create our function that will process each row:
function processRow(headerFieldNames, row) {
try {
fields = splitFields(row);
rowObj = zipRow(headerFieldNames, fields);
rowObjWithDate = addDateStr(rowObj);
return rowToMessage(rowObj);
} catch(e) {
return showError(e);
}
}
So, we have our example function. It’s not too bad, as far as JavaScript code goes. But let’s take a closer look at how we’re managing exceptions here.
try...catch in JavaScriptSo, what’s good about try...catch? The thing to note is that in the above example, any of the steps in the try block might throw an error. In zipRow() and addDateStr(), we intentionally throw errors. And if a problem happens, then we simply catch the error and show whatever message the error happens to have on the page.
Without this mechanism, the code gets really ugly. Here’s what it might look like without exceptions. Instead of throwing exceptions, we’ll assume that our functions will return null:
function processRowWithoutExceptions(headerFieldNames, row) {
fields = splitFields(row);
rowObj = zipRow(headerFieldNames, fields);
if (rowObj === null) {
return showError(new Error('Encountered a row with an unexpected number of items'));
}
rowObjWithDate = addDateStr(rowObj);
if (rowObjWithDate === null) {
return showError(new Error('Unable to parse date in row object'));
}
return rowToMessage(rowObj);
}
As you can see, we end up with a lot of if statements. The code is more verbose, and it’s difficult to follow the main logic. Also, we don’t have a way for each step to tell us what the error message should be, or why they failed (unless we do some trickery with global variables.) So, we have to guess, and explicitly call showError() if the function returns null. Without exceptions, the code is messier and harder to follow.
But look again at the version with exception handling. It gives us a nice clear separation of the “happy path” and the exception handling code. The try part is the happy path, and the catch part is the sad path (so to speak). All of the exception handling happens in one spot. And we can let the individual functions tell us why they failed.
All in all, it seems pretty nice. In fact, I think most of us would consider the first example a neat piece of code. Why would we need another approach?
try...catch exception handlingThe good thing about exceptions is they let you ignore those pesky error conditions. But unfortunately, they do that job a little too well. You just throw an exception and move on. We can work out where to catch it later. And we all intend to put that try…catch block in place. Really, we do. But it’s not always obvious where it should go. And it’s all too easy to forget one. And before you know it, your application crashes.
Another thing to think about is that exceptions make our code impure. Why functional purity is a good thing is a whole other discussion. But let’s consider one small aspect of functional purity: referential transparency.
A referentially transparent function will always give the same result for a given input. But we can’t say this about functions that throw exceptions. At any moment, they might throw an exception instead of returning a value. This makes it more complicated to think about what a piece of code is actually doing.
But what if we could have it both ways? What if we could come up with a pure way to handle errors?
If we are going to write our own pure error handling code, then we need to always return a value. So, as a first attempt, what if we returned an Error object on failure? That is, wherever we were throwing an error, we just return it instead. That might look something like this:
function processRowReturningErrors(headerFieldNames, row) {
fields = splitFields(row);
rowObj = zipRow(headerFieldNames, fields);
if (rowObj instanceof Error) {
return showError(rowObj);
}
rowObjWithDate = addDateStr(rowObj);
if (rowObjWithDate instanceof Error) {
return showError(rowObjWithDate);
}
return rowToMessage(rowObj);
}
This is only a very slight improvement on the version without exceptions. But it is better. We’ve moved responsibility for the error messages back into the individual functions. But that’s about it. We’ve still got all of those if statements. It would be really nice if there was some way we could encapsulate the pattern. In other words, if we know we’ve got an error, don’t bother running the rest of the code.
So, how do we do that? It’s a tricky problem. But it’s achievable with the magic of polymorphism. If you haven’t come across polymorphism before, don’t worry. All it means is “providing a single interface to entities of different types.”¹ In JavaScript, we do this by creating objects that have methods with the same name and signature, but we give them different behaviors.
A classic example of polymorphism is application logging. We might want to send our logs to different places depending on what environment we’re in. So, we define two logger objects:
const consoleLogger = {
log: function log(msg) {
console.log('This is the console logger, logging:', msg);
}
};
const ajaxLogger = {
log: function log(msg) {
return fetch('https://example.com/logger', {method: 'POST', body: msg});
}
};
Both objects define a log function that expects a single string parameter. But they behave differently. The beauty of this is that we can write code that calls .log(), but doesn’t care which object it’s using. It might be a consoleLogger or an ajaxLogger. It works either way. For example, the code below would work equally well with either object:
function log(logger, message) {
logger.log(message);
}
Another example is the .toString() method on all JS objects. We can write a .toString() method on any class that we make. So, perhaps we could create two classes that implement .toString() differently. We’ll call them Left and Right (I’ll explain why in a moment):
class Left {
constructor(val) {
this._val = val;
}
toString() {
const str = this._val.toString();
return `Left(${str})`;
}
}
class Right {
constructor(val) {
this._val = val;
}
toString() {
const str = this._val.toString();
return `Right(${str})`;
}
}
Now, let’s create a function that will call .toString() on those two objects:
function trace(val) {
console.log(val.toString());
return val;
}
trace(new Left('Hello world'));
// ⦘ Left(Hello world)
trace(new Right('Hello world'));
// ⦘ Right(Hello world);
Not exactly mind-blowing, I know. But the point is that we have two different kinds of behavior using the same interface — that’s polymorphism. But notice something interesting. How many if statements have we used? Zero. None. We’ve created two different kinds of behavior without a single if statement in sight. Perhaps we could use something like this to handle our errors…
Left and RightGetting back to our problem, we want to define a happy path and a sad path for our code. On the happy path, we just keep happily running our code until an error happens or we finish. If we end up on the sad path though, we don’t bother with trying to run the code anymore.
Now, we could call our two classes Happy and Sad to represent two paths. But we’re going to follow the naming conventions that other programming languages and libraries use. That way, if you do any further reading it will be less confusing. So, we’ll call our sad path Left and our happy path Right just to stick with convention.
Let’s create a method that will take a function and run it if we’re on the happy path, but ignore it if we’re on the sad path:
/**
*Left represents the sad path.
*/
class Left {
constructor(val) {
this._val = val;
}
runFunctionOnlyOnHappyPath(fn) {
// Left is the sad path. Do nothing with fn
}
toString() {
const str = this._val.toString();
return `Left(${str})`;
}
}
/**
*Right represents the happy path.
*/
class Right {
constructor(val) {
this._val = val;
}
runFunctionOnlyOnHappyPath(fn) {
return fn(this._val);
}
toString() {
const str = this._val.toString();
return `Right(${str})`;
}
}
Then we could do something like this:
const leftHello = new Left('Hello world');
const rightHello = new Right('Hello world');
leftHello.runFunctionOnlyOnHappyPath(trace);
// does nothing
rightHello.runFunctionOnlyOnHappyPath(trace);
// ⦘ Hello world
// ← "Hello world"
.map()We’re getting closer to something useful, but we’re not quite there yet. Our .runFunctionOnlyOnHappyPath() method returns the _value property. That’s fine, but it makes things inconvenient if we want to run more than one function.
Why? Because we no longer know if we’re on the happy path or the sad path. That information is gone as soon as we take the value outside of Left or Right. So, what we can do instead is return a Left or Right with a new _value inside. And we’ll shorten the name while we’re at it.
What we’re doing is mapping a function from the world of plain values to the world of Left and Right. So we call the method .map():
/**
*Left represents the sad path.
*/
class Left {
constructor(val) {
this._val = val;
}
map() {
// Left is the sad path
// so we do nothing
return this;
}
toString() {
const str = this._val.toString();
return `Left(${str})`;
}
}
/**
*Right represents the happy path
*/
class Right {
constructor(val) {
this._val = val;
}
map(fn) {
return new Right(
fn(this._val)
);
}
toString() {
const str = this._val.toString();
return `Right(${str})`;
}
}
With that in place, we can use Left or Right with a fluent-style syntax:
const leftHello = new Left('Hello world');
const rightHello = new Right('Hello world');
const worldToLogRocket = str => str.replace(/world/, 'LogRocket');
leftHello.map(worldToLogRocket).map(trace);
// Doesn't print anything to the console
// ← Left(Hello world)
rightHello.map(worldToLogRocket).map(trace);
// ⦘ Hello LogRocket
// ← Right(Hello LogRocket)
We’ve effectively created two tracks. We can put a piece of data on the right track by calling new Right() and put a piece of data on the left track by calling new Left().
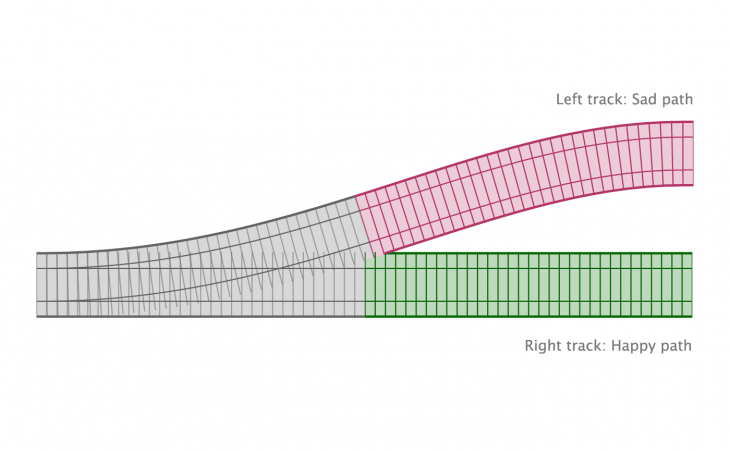
If we map along the right track, we follow the happy path and process the data. If we end up on the left path though, nothing happens. We just keep passing the value down the line. If, say, we were to put an Error in that left track, then we have something very similar to try…catch.
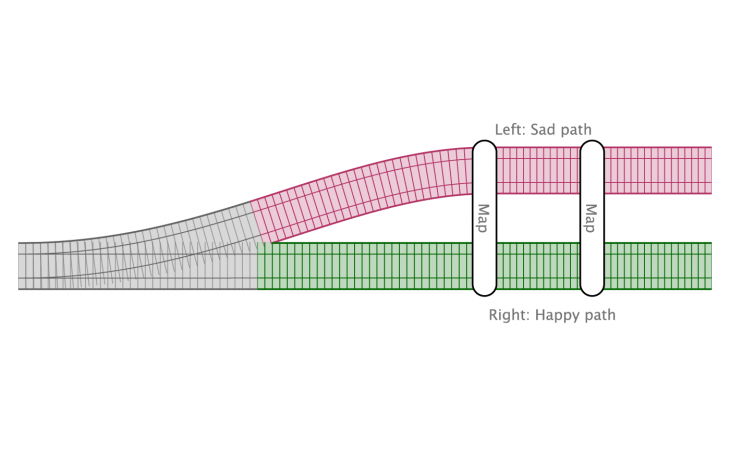
As we go on, it gets to be a bit of a pain writing “a left or a right” all the time. So we’ll refer to the left and right combo together as “Either.” It’s either a left or a right.
So, the next step would be to rewrite our example functions so that they return an Either. A left for an Error, or a right for a value. But, before we do that, let’s take some of the tedium out of it. We’ll write a couple of little shortcuts.
The first is a static method called .of(). All it does is return a new Left or new Right. The code might look like this:
Left.of = function of(x) {
return new Left(x);
};
Right.of = function of(x) {
return new Right(x);
};
To be honest, I find even Left.of() and Right.of() tedious to write. So I tend to create even shorter shortcuts called left() and right():
function left(x) {
return Left.of(x);
}
function right(x) {
return Right.of(x);
}
With those in place, we can start rewriting our application functions:
function zipRow(headerFields, fieldData) {
const lengthMatch = (headerFields.length == fieldData.length);
return (!lengthMatch)
? left(new Error("Row has an unexpected number of fields"))
: right(_.zipObject(headerFields, fieldData));
}
function addDateStr(messageObj) {
const errMsg = 'Unable to parse date stamp in message object';
const d = new Date(messageObj.datestamp);
if (isNaN(d)) { return left(new Error(errMsg)); }
const datestr = Intl.DateTimeFormat('en-US', {year: 'numeric', month: 'long', day: 'numeric'}).format(d);
return right({datestr, ...messageObj});
}
The modified functions aren’t so different from the old ones. We just wrap the return value in either left or right, depending on whether we found an error.
With that done, we can start reworking our main function that processes a single row. We’ll start by putting the row string into an Either with right(), and then map splitFields() to split it:
function processRow(headerFields, row) {
const fieldsEither = right(row).map(splitFields);
// …
}
This works just fine, but we get into trouble when we try the same thing with zipRow():
function processRow(headerFields, row) {
const fieldsEither = right(row).map(splitFields);
const rowObj = fieldsEither.map(zipRow /* wait. this isn't right */);
// ...
}
This is because zipRow() expects two parameters. But functions we pass into .map() only get a single value from the ._value property. One way to fix this is to create a curried version of zipRow(). Function currying is simply dividing a function’s parameters across multiple calls, leveraging closures to pass around functions that have been partially applied. It might look something like this:
function zipRow(headerFields) {
return function zipRowWithHeaderFields(fieldData) {
const lengthMatch = (headerFields.length == fieldData.length);
return (!lengthMatch)
? left(new Error("Row has an unexpected number of fields"))
: right(_.zipObject(headerFields, fieldData));
};
}
This slight change makes it easier to transform zipRow() so it will work nicely with .map():
function processRow(headerFields, row) {
const fieldsEither = right(row).map(splitFields);
const rowObj = fieldsEither.map(zipRow(headerFields));
// ... But now we have another problem ...
}
.join()Using .map() to run splitFields() is fine, as splitFields() doesn’t return an Either. But when we get to running zipRow(), we have a problem. Calling zipRow() returns an Either. So, if we use .map(), we end up sticking an Either inside an Either. If we go any further, we’ll be stuck unless we run .map() inside .map().
This isn’t going to work so well. We need some way to join those nested Eithers together into one. So, we’ll write a new method called .join():
/**
*Left represents the sad path.
*/
class Left {
constructor(val) {
this._val = val;
}
map() {
// Left is the sad path
// so we do nothing
return this;
}
join() {
// On the sad path, we don't
// do anything with join
return this;
}
toString() {
const str = this._val.toString();
return `Left(${str})`;
}
}
/**
*Right represents the happy path
*/
class Right {
constructor(val) {
this._val = val;
}
map(fn) {
return new Right(
fn(this._val)
);
}
join() {
if ((this._val instanceof Left)
|| (this._val instanceof Right))
{
return this._val;
}
return this;
}
toString() {
const str = this._val.toString();
return `Right(${str})`;
}
}
Now we’re free to un-nest our values:
function processRow(headerFields, row) {
const fieldsEither = right(row).map(splitFields);
const rowObj = fieldsEither.map(zipRow(headerFields)).join();
const rowObjWithDate = rowObj.map(addDateStr).join();
// Slowly getting better... but what do we return?
}
.chain()We’ve made it a lot further. But remembering to call .join() every time is annoying. This pattern of calling .map() and .join() together is so common that we’ll create a shortcut method for it. We’ll call it .chain() because it allows us to chain together functions that return Left or Right:
/**
*Left represents the sad path.
*/
class Left {
constructor(val) {
this._val = val;
}
map() {
// Left is the sad path
// so we do nothing
return this;
}
join() {
// On the sad path, we don't
// do anything with join
return this;
}
chain() {
// Boring sad path,
// do nothing.
return this;
}
toString() {
const str = this._val.toString();
return `Left(${str})`;
}
}
/**
*Right represents the happy path
*/
class Right {
constructor(val) {
this._val = val;
}
map(fn) {
return new Right(
fn(this._val)
);
}
join() {
if ((this._val instanceof Left)
|| (this._val instanceof Right)) {
return this._val;
}
return this;
}
chain(fn) {
return fn(this._val);
}
toString() {
const str = this._val.toString();
return `Right(${str})`;
}
}
Going back to our railway track analogy, .chain() allows us to switch rails if we come across an error. It’s easier to show with a diagram, though.
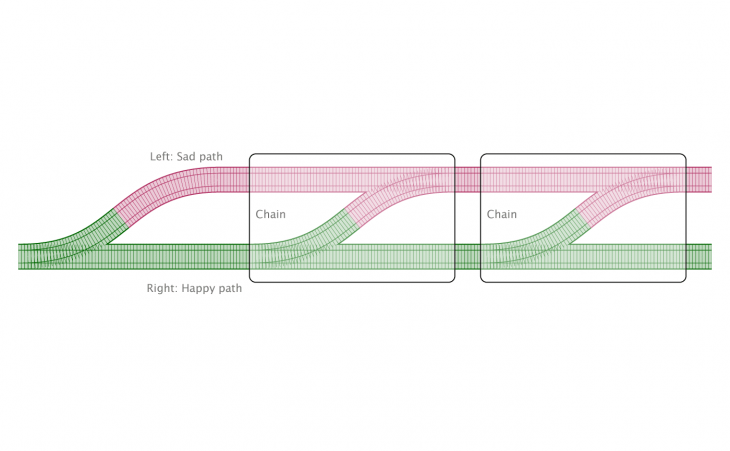
With that in place, our code is a little clearer:
function processRow(headerFields, row) {
const fieldsEither = right(row).map(splitFields);
const rowObj = fieldsEither.chain(zipRow(headerFields));
const rowObjWithDate = rowObj.chain(addDateStr);
// Slowly getting better... but what do we return?
}
get() methodWe’re nearly done reworking our processRow() function. But what happens when we return the value? Eventually, we want to take a different action depending on whether we have a Left or Right. So we’ll write a function that will take a different action accordingly:
function either(leftFunc, rightFunc, e) {
return (e instanceof Left) ? leftFunc(e.get()) : rightFunc(e.get());
}
We need to implement that get() method on Left and Right that will allow us to unwrap the underlying value now that we are ready to use it:
/**
*Left represents the sad path.
*/
class Left {
constructor(val) {
this._val = val;
}
map() {
// Left is the sad path
// so we do nothing
return this;
}
join() {
// On the sad path, we don't
// do anything with join
return this;
}
chain() {
// Boring sad path,
// do nothing.
return this;
}
get() {
return this._val;
}
toString() {
const str = this._val.toString();
return `Left(${str})`;
}
}
/**
*Right represents the happy path
*/
class Right {
constructor(val) {
this._val = val;
}
map(fn) {
return new Right(
fn(this._val)
);
}
join() {
if ((this._val instanceof Left)
|| (this._val instanceof Right)) {
return this._val;
}
return this;
}
chain(fn) {
return fn(this._val);
}
get() {
return this._val;
}
toString() {
const str = this._val.toString();
return `Right(${str})`;
}
}
We’re now able to finish our processRow function:
function processRow(headerFields, row) {
const fieldsEither = right(row).map(splitFields);
const rowObj = fieldsEither.chain(zipRow(headerFields));
const rowObjWithDate = rowObj.chain(addDateStr);
return either(showError, rowToMessage, rowObjWithDate);
}
And, if we’re feeling particularly clever, we could write it using a fluent syntax:
function processRow(headerFields, row) {
const rowObjWithDate = right(row)
.map(splitFields)
.chain(zipRow(headerFields))
.chain(addDateStr);
return either(showError, rowToMessage, rowObjWithDate);
}
Both versions are pretty neat. Not a try…catch in sight. And no if statements in our top-level function. If there’s a problem with any particular function, we just show an error message at the end. And note that in processRow(), the only time we mention left or right is at the very start when we call right(). For the rest, we just use the .map() and .chain() methods to apply the next function.
.ap() and liftThis is looking good, but there’s one final scenario that we need to consider. Sticking with the example, let’s take a look at how we might process the whole CSV data, rather than just each row. We’ll need a helper function or three:
function splitCSVToRows(csvData) {
// There should always be a header row... so if there's no
// newline character, something is wrong.
return (csvData.indexOf('\n') < 0)
? left('No header row found in CSV data')
: right(csvData.split('\n'));
}
function processRows(headerFields, dataRows) {
// Note this is Array map, not Either map.
return dataRows.map(row => processRow(headerFields, row));
}
function showMessages(messages) {
return `<ul class="Messages">${messages.join('\n')}</ul>`;
}
So, we have a helper function that splits the CSV data into rows. And we get an Either back. Now, we can use .map() and some lodash functions to split out the header row from data rows. But we end up in an interesting situation…
function csvToMessages(csvData) {
const csvRows = splitCSVToRows(csvData);
const headerFields = csvRows.map(_.head).map(splitFields);
const dataRows = csvRows.map(_.tail);
// What’s next?
}
We have our header fields and data rows all ready to map over with processRows(). But headerFields and dataRows are both wrapped up inside an Either. We need some way to convert processRows() to a function that works with Eithers. As a first step, we will curry processRows:
function processRows(headerFields) {
return function processRowsWithHeaderFields(dataRows) {
// Note this is Array map, not Either map.
return dataRows.map(row => processRow(headerFields, row));
};
}
Now, with this in place, we can run an experiment. We have headerFields, which is an Either wrapped around an array. What would happen if we were to take headerFields and call .map() on it with processRows()?
function csvToMessages(csvData) {
const csvRows = splitCSVToRows(csvData);
const headerFields = csvRows.map(_.head).map(splitFields);
const dataRows = csvRows.map(_.tail);
// How will we pass headerFields and dataRows to
// processRows() ?
const funcInEither = headerFields.map(processRows);
}
Using .map() here calls the outer function of processRows(), but not the inner one. In other words, processRows() returns a function that we still need to execute. And because it’s .map(), we still get an Either back.
So we end up with a function inside an Either. I gave it away a little with the variable name. funcInEither is an Either. It contains a function that takes an array of strings and returns an array of different strings. We need some way to take that function and call it with the value inside dataRows.
To do that, we need to add one more method to our Left and Right classes. We’ll call it .ap() because the standard tells us to. The way to remember it is to recall that ap is short for “apply.” It helps us apply values to functions.
The method for the Left does nothing, as usual:
/* Rest of Left class is hidden to save space */
// Ap In Left (the sad path)
ap() {
return this;
}
And for the Right class, the variable name spells out that we expect the other Either to contain a function:
// In Right (the happy path)
ap(otherEither) {
const functionToRun = otherEither.get();
return this.map(functionToRun);
}
So, with that in place, we can finish off our main function:
function csvToMessages(csvData) {
const csvRows = splitCSVToRows(csvData);
const headerFields = csvRows.map(_.head).map(splitFields);
const dataRows = csvRows.map(_.tail);
const funcInEither = headerFields.map(processRows);
const messagesArr = dataRows.ap(funcInEither);
return either(showError, showMessages, messagesArr);
}
Now, I’ve mentioned this before, but I find .ap() a little confusing to work with.² Another way to think about it is to say: “I have a function that would normally take two plain values. I want to turn it into a function that takes two Eithers.” Now that we have .ap(), we can write a function that will do exactly that.
We’ll call it liftA2(), again because it’s a standard name. It takes a plain function expecting two arguments, and “lifts” it to work with applicatives. (Applicatives are things that have an .ap() method and an .of() method.) So, liftA2() is short for “lift applicative, two parameters.”
So, liftA2() might look something like this:
function liftA2(func) {
return function runApplicativeFunc(a, b) {
return b.ap(a.map(func));
};
}
So, our top-level function would use it like this:
function csvToMessages(csvData) {
const csvRows = splitCSVToRows(csvData);
const headerFields = csvRows.map(_.head).map(splitFields);
const dataRows = csvRows.map(_.tail);
const processRowsA = liftA2(processRows);
const messagesArr = processRowsA(headerFields, dataRows);
return either(showError, showMessages, messagesArr);
}
Why is this any better than just throwing exceptions? Well, let’s think about why we like exceptions in the first place.
If we didn’t have exceptions, we would have to write a lot of if statements all over the place. We would be forever writing code along the lines of, “If the last thing worked, keep going; otherwise, handle the error.” And we would have to keep handling these errors all through our code. That makes it hard to follow what’s going on. Throwing exceptions allows us to jump out of the program flow when something goes wrong. So we don’t have to write all those if statements; we can focus on the happy path.
But there’s a catch. Exceptions hide a little too much. When you throw an exception, you make handling the error some other function’s problem. But it’s all too easy to ignore the exception, and let it bubble all the way to the top of the program.
The nice thing about Either is that it lets you jump out of the main program flow like you would with an exception. But it’s honest about it. You get either a Right or a Left. You can’t pretend that Lefts aren’t a possibility; eventually, you have to pull the value out with something like an either() call.
Now, I know that sounds like a pain. But take a look at the code we’ve written (not the Either classes, the functions that use them). There’s not a lot of exception handling code there. In fact, there’s almost none, except for the either() call at the end of csvToMessages() and processRow(). And that’s the point — with Either, you get pure error handling that you can’t accidentally forget, but without it stomping through your code and adding indentation everywhere.
This is not to say that you should never, ever use try…catch. Sometimes that’s the right tool for the job, and that’s OK. But it’s not the only tool. Using Either gives us some advantages that try…catch can’t match.
So, perhaps give Either a go sometime. Even if it’s tricky at first, I think you’ll get to like it. If you do give it a go though, please don’t use the implementation from this tutorial. Try one of the well-established libraries like Crocks, Sanctuary, Folktale, or Monet. They’re better maintained, and I’ve papered over some things for the sake of simplicity here.
.ap() in a confusing way. It uses the reverse order from the way most other languages define it.
Debugging code is always a tedious task. But the more you understand your errors, the easier it is to fix them.
LogRocket allows you to understand these errors in new and unique ways. Our frontend monitoring solution tracks user engagement with your JavaScript frontends to give you the ability to see exactly what the user did that led to an error.
LogRocket records console logs, page load times, stack traces, slow network requests/responses with headers + bodies, browser metadata, and custom logs. Understanding the impact of your JavaScript code will never be easier!

A guide for using JWT authentication to prevent basic security issues while understanding the shortcomings of JWTs.

Discover how to build, render, and automate product demo videos with Remotion, replacing traditional screen recordings with reusable React code.

Chrome’s Modern Web Guidance embeds modern web platform skills into AI coding agents, helping them choose native HTML, CSS, and browser APIs over legacy patterns.

Learn how to use Fallow to analyze AI-generated code, detect dead code, duplicate logic, and complexity issues, and integrate automated code quality checks into your AI-assisted development workflow.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

