If you’ve been online in the past year, you’ve most likely come across an AI model in the wild. And for good reason, too: these models are quickly becoming very powerful, with the best ones capable of producing some truly amazing results.

However, AI models are a bit like gourmet chefs. They can create wonders, but they need good quality ingredients. AI models do alright with most input, but they truly shine if they receive input in the format they’re most tuned to. This is the whole point of vector databases.
Over the course of this article, we’ll dive deep into what vector databases are, why they’re becoming increasingly important in the AI world, and then we’ll look at a step-by-step guide to implementing a vector database.
Before we start exploring vector databases, it’s important to understand what vectors are in the context of programming and machine learning.
In programming, a vector is essentially a one-dimensional array of numbers. If you’ve ever written code that involves 3D graphics or machine learning algorithms, chances are you’ve used vectors.
const vector4_example = [0.5, 1.5, 6.0, 3.4]
They’re just arrays of numbers, typically floating point numbers, that we refer to by their dimensions. For example, a vector3 is a three-element array of floating point numbers, and a vector4 is a four-element array of floating point numbers. It’s as simple as that!
But vectors are more than just arrays of numbers. In the context of machine learning, vectors play a critical role in representing and manipulating data in high-dimensional spaces. This enables us to perform complex operations and computations that drive AI models.
Now that we’ve got a grip on vectors, let’s turn our attention to vector databases.
At first glance, you might think, “Hey, since vectors are just arrays of numbers, can’t we use our regular databases to store them?” Well, technically, you can. But here’s where things get interesting.
A vector database is a specialized type of database that is optimized for storing and performing operations on large amounts of vector data. So while your regular database can indeed store arrays, a vector database goes a step further by providing specialized tools and operations to handle vectors.
In the next section, we’ll talk about why vector databases are necessary and the advantages they bring to the table. So stick around, because things are about to get even more interesting!
Now that we have a solid understanding of what a vector database is, let’s dive into why they are so necessary in the realm of AI and machine learning.
The key word here is performance. Vector databases often processing hundreds of millions of vectors per query, and this kind of performance is significantly faster than what traditional databases are able to achieve when handling vectors.
So, what makes vector databases so speedy and efficient? Let’s take a look at some of the key features that set them apart.
Vector databases are designed to perform complex mathematical operations on vectors, such as filtering and locating “nearby” vectors. These operations are crucial in machine learning contexts, where models often need to find vectors that are close to each other in a high-dimensional space.
For example, a common data analysis technique, Cosine Similarity, is often used to measure how similar two vectors are. Vector databases excel at these kinds of computations.
Like a well-organized library, a database needs a good indexing system to quickly retrieve the data requested. Vector databases provide specialized vector indexes that make retrieving data significantly faster and more deterministic (as opposed to stochastic) than traditional databases.
With these indexes, vector databases can rapidly locate the vectors that your AI model needs and produce results quickly.
In the world of big data, storage space is a precious commodity. Vector databases shine here as well, storing vectors in a way that makes them more compact. Techniques like compressing and quantizing vectors are used to keep as much data in memory as possible, which further reduces load and query latency.
When dealing with massive amounts of data, it can be beneficial to distribute the data across multiple machines, a process known as sharding. Many databases can do this, but SQL databases in particular take more effort to scale out. Vector databases, on the other hand, often have sharding built into their architecture, allowing them to easily handle large amounts of data.
In short, while traditional databases can store and perform operations on vectors, they aren’t optimized for the task. Vector databases, on the other hand, are built for exactly this purpose. They provide the speed, efficiency, and specialized tools necessary to handle large amounts of vector data, making them an essential tool in the world of AI and machine learning.
In the next section we’ll compare vector databases with other types of databases and explain how they fit into the larger database ecosystem. We’re just getting started!
For the purposes of this guide, we will be using Weaviate, a popular vector database service, to implement a simple vector database that you can build on for any use case.
You can clone a starter template here and run npm install to set it up.
After creating an account, you’ll need to set up a project through the Weaviate dashboard. Go to the WCS Console and click Create cluster:

Select the Free sandbox tier and provide a Cluster name. When it asks you to enable authentication, select Yes:
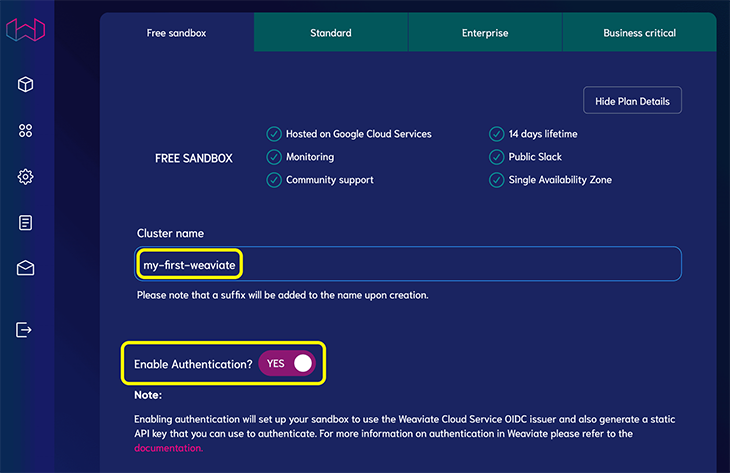
Click Create. After a few minutes, you should see a checkmark when it’s finished.
Click Details to see your cluster details, as we’ll need them in the next section. These include:
With the prerequisites out of the way, we can create the vector database and query it. To follow along, you’ll need a new Node project; you can clone the template on GitHub here, which includes everything you’ll need to get started.
Or you can create one by running the following commands:
mkdir weaviate-vector-database && cd weaviate-vector-database npm init -y && npm install dotenv openai weaviate-ts-client mkdir src
Edit your package.json file and add a start script, like so:
// ...rest of package.json
"scripts": {
"start": "node src/index.js"
},
// ...rest of package.json
Create a .env file to store sensitive information like API keys. Write the touch .env command and open the newly created .env file in your code editor, then paste in the following and ensure to replace the placeholders with the actual values:
// .env OPENAI_KEY="<OPENAI_API_KEY>" WEAVIATE_API_KEY="<WEAVIATE_API_KEY>" WEAVIATE_URL="<WEAVIATE_URL>" DATA_CLASSNAME="Document"
With the project setup complete, we can add some code to setup and work with our vector database. Let’s quickly summarize what we’re going to implement:
With that said, let’s create our first file to store our database connection and helper functions. Create a new file by running touch src/database.js and let’s start filling it out:
// src/database.js
import weaviate, { ApiKey } from "weaviate-ts-client";
import { config } from "dotenv";
config();
async function setupClient() {
let client;
try {
client = weaviate.client({
scheme: "https",
host: process.env.WEAVIATE_URL,
apiKey: new ApiKey(process.env.WEAVIATE_API_KEY),
headers: { "X-OpenAI-Api-Key": process.env.OPENAI_API_KEY },
});
} catch (err) {
console.error("error >>>", err.message);
}
return client;
}
// ... code continues below
Let’s break down what’s happening here. First, we import the necessary packages, the Weaviate client and the dotenv configuration. dotenv is a package that loads environment variables from a .env file into process.env. The Weaviate and OpenAI keys and URLs are typically stored in environment variables to keep them secret and out of your codebase.
Here’s what happened in the setupClient() function:
clienttry … catch block where we set up the connection to the Weaviate server. If any errors occur during this process, we print the error message to the console
try block, we create a new Weaviate client using the weaviate.client() method. The scheme, host, and apiKey parameters are taken from the environment variables that we’ve setWith the client set up, let’s run a migration with some dummy data, a collection of fictional beings, places, and events. Later on, we’ll query GPT-3 on this data.
If you did not clone the starter template, follow the steps below:
touch src/data.jsTake some time to explore the data in src/data.js. Then, add a new import at the top of the src/database.js file:
// ...other imports
import { FAKE_XORDIA_HISTORY } from "./data";
Below the setupClient function, add a new function like below:
async function migrate(shouldDeleteAllDocuments = false) {
try {
const classObj = {
class: process.env.DATA_CLASSNAME,
vectorizer: "text2vec-openai",
moduleConfig: {
"text2vec-openai": {
model: "ada",
modelVersion: "002",
type: "text",
},
},
};
const client = await setupClient();
try {
const schema = await client.schema
.classCreator()
.withClass(classObj)
.do();
console.info("created schema >>>", schema);
} catch (err) {
console.error("schema already exists");
}
if (!FAKE_XORDIA_HISTORY.length) {
console.error(`Data is empty`);
process.exit(1);
}
if (shouldDeleteAllDocuments) {
console.info(`Deleting all documents`);
await deleteAllDocuments();
}
console.info(`Inserting documents`);
await addDocuments(FAKE_XORDIA_HISTORY);
} catch (err) {
console.error("error >>>", err.message);
}
}
Once again, let’s break down what’s happening here.
The migrate function takes in a single argument, shouldDeleteAllDocuments, which determines whether to clear the database when migrating data.
Within our try…catch block, we create a class object named classObj. This object represents a schema for a class in Weaviate (ensure that you add a CLASS_NAME in the .env file), which uses the text2vec-openai vectorizer. This determines how text documents will be configured and represented in the database, and tells Weaviate to vectorize our data using OpenAI’s “ada” model.
We then create the schema using the client.schema.classCreator().withClass(classObj).do() method chain. This sends a request to the Weaviate server to create the document class as defined in the classObj. Once the schema is successfully created, we log the schema object to the console with the message created schema >>>. Errors are now handled with a simple message logged to the console.
We can check the length of the dummy data being migrated. If empty, the code ends here. We can clear the database using a deleteAllDocuments function (which we’ll add later) if shouldDeleteAllDocuments is true.
Finally, using an addDocuments function (which we’ll add next), we upload all the entries to be vectorized and stored in Weaviate.
We can move on to vectorizing and uploading our text documents. This is actually a two-step process where:
Thankfully, these are handled automatically by the Weaviate SDK we’re using. Let’s go ahead and create the function to do this. Open the same src/database.js file and paste in the following:
// code continues from above
const addDocuments = async (data = []) => {
const client = await setupClient();
let batcher = client.batch.objectsBatcher();
let counter = 0;
const batchSize = 100;
for (const document of data) {
const obj = {
class: process.env.DATA_CLASSNAME,
properties: { ...document },
};
batcher = batcher.withObject(obj);
if (counter++ == batchSize) {
await batcher.do();
counter = 0;
batcher = client.batch.objectsBatcher();
}
}
const res = await batcher.do();
return res;
};
// ... code continues below
As before, let’s break down what is happening here.
setupClient() function to set up and get a Weaviate client instanceclient.batch.objectsBatcher(), which is used to collect documents and upload them to Weaviate all at once, making the process more efficientbatchSize variable, and set it to 100. The counter keeps track of how many documents have been added to the current batch, and the batchSize defines how many documents should be in each batchbatcher.withObject(obj)batcher.do(), reset the counter to 0, and create a new batcher for the next batch of documentsOnce all the documents have been processed and added to batches, if there’s a batch left that hasn’t been uploaded yet (because it didn’t reach the batchSize), you can upload that remaining batch with batcher.do().
The final step here occurs when the function returns the response from the last batcher.do() call. This response will contain details about the upload, such as if it was successful and any errors that occurred.
In essence, the addDocuments() function helps us efficiently upload a large number of documents to our Weaviate instance by grouping them into manageable batches.
Let’s add the code for deleteAllDocuments which was used in the migrate function. Below the addDocuments function, add the code below:
// code continues from above
async function deleteAllDocuments() {
const client = await setupClient();
const documents = await client.graphql
.get()
.withClassName(process.env.DATA_CLASSNAME)
.withFields("_additional { id }")
.do();
for (const document of documents.data.Get[process.env.DATA_CLASSNAME]) {
await client.data
.deleter()
.withClassName(process.env.DATA_CLASSNAME)
.withId(document._additional.id)
.do();
}
}
// ... code continues below
This function is relatively simple.
setupClient and retrieve the ids of all documents with the class name of Documentfor ... of loop, we delete each document using its idThis approach works because we have a small amount of data. For larger databases, a batching technique would be required to delete all the documents, as the limit for each request is only 200 entries at a time.
Now that we have a way to upload data to our database, let’s add a function to query the database. In this case, we’ll be doing a “nearest neighbor search” to find documents that are similar to our query.
In the same src/database.js file, add in the following:
// code continues from above
async function nearTextQuery({
concepts = [""],
fields = "text category",
limit = 1,
}) {
const client = await setupClient();
const res = await client.graphql
.get()
.withClassName("Document")
.withFields(fields)
.withNearText({ concepts })
.withLimit(limit)
.do();
return res.data.Get[process.env.DATA_CLASSNAME];
}
export { migrate, addDocuments, deleteAllDocuments, nearTextQuery };
Again, let’s do a breakdown of what’s going on here:
nearTextQuery() is an asynchronous function that accepts an object as an argument. This object can contain three properties:
concepts: An array of string(s) that represents the term(s) we’re searching forfields: A string that represents the fields we want to get back in your search results. In this case, we are requesting from the text and category fieldslimit: The maximum number of results we want to get back from our search querysetupClient() function to get a Weaviate client instanceclient.graphql.get(): Initializes a GraphQL query.withClassName("Document"): We specify that we want to search within “Document” objects.withFields(fields): We specify which fields we want to be returned in the results.withNearText({ concepts }): This is where the magic happens! We specify the concepts that Weaviate will use to search for semantically similar documents.withLimit(limit): We specify the maximum number of results to return.do() executes the queryres variable, which is then returned on the next lineIn short, the nearTextQuery() function helps us search for semantically similar documents in our Weaviate instance based on the provided terms.
Let’s migrate our data so we can query it in the next section. Open your terminal and run npm run start "migrate".
Large language models like GPT-3 and ChatGPT are designed to process input and generate useful output, a task that requires understanding the intricate meanings and relationships between words and phrases.
They do this by representing words, sentences, or even entire documents as high-dimensional vectors. By analyzing the similarities and differences between these vectors, the AI model can understand the context, semantics, and even subtle nuances in our language.
So, where do vector databases come in? Let’s think of vector databases as librarians for the AI model. In a vast library of books (or, in our case, vectors), the AI model needs to quickly find the books that are most relevant to a specific query. Vector databases enable this by efficiently storing these “books” and providing quick and precise retrieval when needed.
This is crucial for many AI applications. For example, in a chatbot application, the AI model needs to find the most relevant responses to a user’s question. It does this by turning the user’s question and potential responses into vectors, and then using the vector database to find the response that’s most similar to the user’s question.
With that in mind, we’ll be using our database above to provide an AI model, GPT-3.5, with context on our own data. This will allow the model to answer questions on data it wasn’t trained on.
Create a new file by running touch src/data.js and paste in the following:
import { Configuration, OpenAIApi } from "openai";
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
async function getChatCompletion({ prompt, context }) {
const chatCompletion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{
role: "system",
content: `
You are a knowledgebase oracle. You are given a question and a context. You answer the question based on the context.
Analyse the information from the context and draw fundamental insights to accurately answer the question to the best of your ability.
Context: ${context}
`,
},
{ role: "user", content: prompt },
],
});
return chatCompletion.data.choices[0].message;
}
export { getChatCompletion };
As usual, let’s break down the file:
openai package and initialize an openai instancegetChatCompletion function that takes in a prompt, some context, and configures the GPT-3.5 model to respond as a knowledge base oracleWith our vector database and AI model set up, we can finally query our data by combining both systems. Using the powerful effects of embeddings and the impressive natural language capabilities of GPT-3.5, we’ll be able to interact with our data in a more expressive and customisable manner.
Start by creating a new file and running touch src/index.js. Then paste in the following:
import { config } from "dotenv";
import { nearTextQuery } from "./database.js";
import { getChatCompletion } from "./model.js";
config();
const queryDatabase = async (prompt) => {
console.info(`Querying database`);
const questionContext = await nearTextQuery({
concepts: [prompt],
fields: "title text date",
limit: 50,
});
const context = questionContext
.map((context, index) => {
const { title, text, date } = context;
return `
Document ${index + 1}
Date: ${date}
Title: ${title}
${text}
`;
})
.join("\n\n");
const aiResponse = await getChatCompletion({ prompt, context });
return aiResponse.content;
};
const main = async () => {
const command = process.argv[2];
const params = process.argv[3];
switch (command) {
case "migrate":
return await migrate(params === "--delete-all");
case "query":
return console.log(await queryDatabase(params));
default:
// do nothing
break;
}
};
main();
In this file, we’re bringing together all the work we’ve done so far to allow us query our data through the command line. As usual, let’s explore what’s going on here:
dotenv packagequeryDatabase function that takes in a text prompt, which we use to perform a “near text” query on our vector database. We limit our results to 50, and we’re specifically asking for the ‘title’, ‘text’, and ‘date’ fields of the matched conceptsmain function. Here, we use command-line arguments to perform various tasks. If we pass migrate, we get to migrate our data (with an optional --delete-all flag, just in case we want to clean our slate and start afresh), and with query, we can test our query functionCongratulations. If you got this far you deserve a pat on the back — and you can finally test your code.
Open the terminal and run this command:
npm run start "query" "what are the 3 most impressive achievements of humanity in the story?"
The query is sent to your Weaviate vector database where it is vectorized, compared to other similar vectors, and returns the 50 most similar ones based on their text. This context data is then formatted and sent along with your query to OpenAI’s GPT-3.5 model where it is processed and a response is generated.
If all goes well, you should get a similar response to the one below:

Feel free to explore this fictional world with more queries, or better yet, bring your own data and witness the power of vectors and embeddings firsthand.
If you run into any errors at this point, compare your code with the final version here and ensure you have a .env file created and filled in.
Throughout this tutorial, we’ve lightly explored the powerful capabilities of vectors and vector databases. Using tools like Weaviate and GPT-3, we’ve seen firsthand the potential these technologies have to shape AI applications, from improving personalized chatbots to enhancing machine learning algorithms. Make sure you take a look at our GitHub too!
However, this is just the beginning. If you’d like to learn more about working with vector databases, consider:
Thanks for sticking to the very end and hopefully, this was a productive use of your time.
There’s no doubt that frontends are getting more complex. As you add new JavaScript libraries and other dependencies to your app, you’ll need more visibility to ensure your users don’t run into unknown issues.
LogRocket is a frontend application monitoring solution that lets you replay JavaScript errors as if they happened in your own browser so you can react to bugs more effectively.
LogRocket works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and @ngrx/store. Instead of guessing why problems happen, you can aggregate and report on what state your application was in when an issue occurred. LogRocket also monitors your app’s performance, reporting metrics like client CPU load, client memory usage, and more.
Build confidently — start monitoring for free.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.

I migrated 20 production-style components from Tailwind to StyleX. Here’s what the data showed about LOC, CSS bundle size, build time, and type safety.

A guide for using JWT authentication to prevent basic security issues while understanding the shortcomings of JWTs.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

