Understanding how JavaScript works is the key to writing efficient JavaScript. There are myriad ways to write more efficient code. For example, you could write compiler-friendly JavaScript to avoid a 7x slowdown of a simple one-liner.

In this article, we’ll focus on JavaScript optimization methods that minimize parse times. We’ll narrow our discussion to V8, the JS engine that powers Electron, Node.js, and Google Chrome. To understand parse-friendly optimizations, we must first discuss how JavaScript parsing works. This tutorial outlines three tips for writing faster JavaScript, each motivated by a deeper understanding of parsing.
As a refresher, let’s review the three stages of JavaScript execution.
The second and third stages involve JavaScript compilation. In this tutorial, we will discuss the first stage in detail and unravel its impact on writing efficient JavaScript. We will discuss the parsing pipeline in sequential order, left-to-right and top-to-bottom. The pipeline accepts source code and outputs a syntax tree.
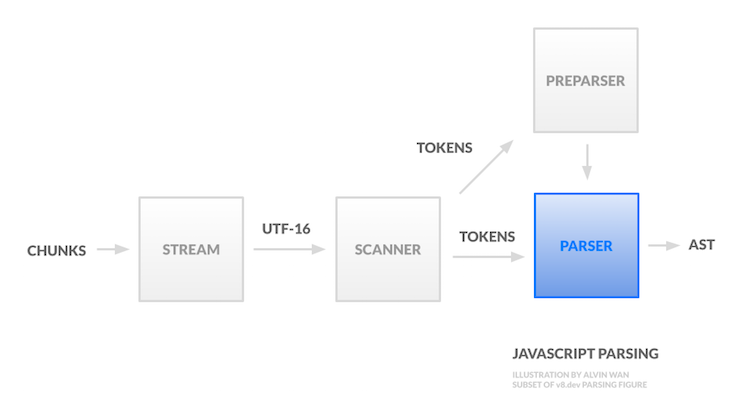
The source code is first broken up in chunks; each chunk may be associated with a different encoding. A stream then unifies all chunks under the UTF-16 encoding.
Prior to parsing, the scanner then breaks up the UTF-16 stream into tokens. A token is the smallest unit of a script that has semantic meaning. There are several categories of tokens, including whitespace (used for automatic semicolon insertion), identifiers, keywords, and surrogate pairs (combined to make identifiers only when the pair is not recognized as anything else). These tokens are then fed first to the preparser and then to the parser.
The preparser does the minimum amount of work, just enough to skip the passed-in source code, enabling lazy parsing (as opposed to eager parsing). The preparser ensures the input source code contains valid syntax and yields enough information to correctly compile the outer function. This preparsed function is later compiled on demand.
Given tokens generated by the scanner, the parser now needs to generate an intermediate representation to be used by the compiler.
We’ll need to first discuss parse trees. A parse tree, or concrete syntax tree (CST), represents the source syntax as a tree. Each leaf node is a token and each intermediate node represents a grammar rule. For English, a grammar rule would be a noun, subject, etc. For code, a grammar rule is an expression. However, parse trees grow quickly in size with respect to the program size.
On the other hand, an abstract syntax tree (AST) is much more compact. Each intermediate represents a construct, such as a minus operation (-), and not all details in the source code are represented in the tree. For example, groupings defined by parentheses are implied by the tree structure. Furthermore, punctuation, delimiters, and whitespace are omitted. You can find concrete examples of differences between ASTs and CSTs here.
Let’s turn our attention to ASTs in particular. Take the following Fibonacci program in JavaScript, for example.
function fib(n) {
if (n <= 1) return n;
return fib(n-1) + fib(n-2);
}
The corresponding abstract syntax is the following, represented as JSON, generated using AST Explorer (if you need a refresher, read this detailed walkthrough of how to read ASTs in JSON format).
{
"type": "Program",
"start": 0,
"end": 73,
"body": [
{
"type": "FunctionDeclaration",
"start": 0,
"end": 73,
"id": {
"type": "Identifier",
"start": 9,
"end": 12,
"name": "fib"
},
"expression": false,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 13,
"end": 14,
"name": "n"
}
],
"body": {
"type": "BlockStatement",
"start": 16,
"end": 73,
"body": [
{
"type": "IfStatement",
"start": 20,
"end": 41,
"test": {
"type": "BinaryExpression",
"start": 24,
"end": 30,
"left": {
"type": "Identifier",
"start": 24,
"end": 25,
"name": "n"
},
"operator": "<=",
"right": {
"type": "Literal",
"start": 29,
"end": 30,
"value": 1,
"raw": "1"
}
},
"consequent": {
"type": "ReturnStatement",
"start": 32,
"end": 41,
"argument": {
"type": "Identifier",
"start": 39,
"end": 40,
"name": "n"
}
},
"alternate": null
},
{
"type": "ReturnStatement",
"start": 44,
"end": 71,
"argument": {
"type": "BinaryExpression",
"start": 51,
"end": 70,
"left": {
"type": "CallExpression",
"start": 51,
"end": 59,
"callee": {
"type": "Identifier",
"start": 51,
"end": 54,
"name": "fib"
},
"arguments": [
{
"type": "BinaryExpression",
"start": 55,
"end": 58,
"left": {
"type": "Identifier",
"start": 55,
"end": 56,
"name": "n"
},
"operator": "-",
"right": {
"type": "Literal",
"start": 57,
"end": 58,
"value": 1,
"raw": "1"
}
}
]
},
"operator": "+",
"right": {
"type": "CallExpression",
"start": 62,
"end": 70,
"callee": {
"type": "Identifier",
"start": 62,
"end": 65,
"name": "fib"
},
"arguments": [
{
"type": "BinaryExpression",
"start": 66,
"end": 69,
"left": {
"type": "Identifier",
"start": 66,
"end": 67,
"name": "n"
},
"operator": "-",
"right": {
"type": "Literal",
"start": 68,
"end": 69,
"value": 2,
"raw": "2"
}
}
]
}
}
}
]
}
}
],
"sourceType": "module"
}
(Source: GitHub)
The takeaway above is that each node is an operator and leaves are operands. This AST is then fed as input to the next two stages of JavaScript execution.
In the list below, we’ll omit tips that are in widespread adoption, such as minifying your code to maximize information density, making the scanner more time-efficient. In addition, we’ll skip recommendations that are not as widely applicable, such as avoiding non-ASCII characters.
There are countless steps you can take to improve parsing performance. Let’s highlight a few of the most broadly applicable.
Blocking the main thread delays user interaction, so work should be offloaded from the main thread as much as possible. The key is to identify and avoid parser behaviors that could result in long-running tasks in the main thread.
This heuristic extends beyond optimizing for the parser. For example, user-controlled snippets of JavaScript can utilize web workers to the same effect. For more information, see these tutorials for real-time processing application and angular with web workers.
Inline scripts are processed on the main thread and, per the heuristic above, should be avoided. In fact, any JavaScript loading blocks the main thread, except asynchronous and deferred loads.
Lazy compilation occurs on the main thread as well. However, if done correctly, lazy parsing can speed up startup time. To force eager parsing, you can use tools like optimize.js (unmaintained) for deciding between eager and lazy parsing.
Break up large files into smaller ones to maximize parallelized script loading. The “Cost of JavaScript 2019” report compared file sizes between Facebook and Reddit. The former performs just 30 percent of parsing and compilation on the main thread by splitting ~6MB of JavaScript across nearly 300 requests. By contrast, 80 percent of parsing and compilation for Reddit JavaScript is performed on the main thread.
Parsing JSON is much more efficient than parsing object literals in JavaScript. This is true across all major JavaScript execution engines by up to 2x for an 8MB file, as demonstrated by this parsing benchmark.
There are two reasons for this JSON-parsing efficiency, as discussed at the Chrome Dev Summit 2019:
However, it’s worth noting that JSON.parse also blocks the main thread. For files larger than 1MB, FlatBuffers can improve parsing efficiency.
Finally, you can improve parse efficiency by sidestepping parsing entirely. One option for server-side compilation is WebAssembly (WASM). However, this isn’t a replacement for JavaScript. For all JS, another possibility is maximizing code caching.
It’s worth noting when caching takes effect. Any code compiled before the end of execution is cached — which means that handlers, listeners, etc. are not cached. To maximize code caching, you must maximize the amount of code compiled before the end of execution. One method is to exploit Invoked Immediately Function Expression (IIFE) heuristics: the parser uses heuristics to identify these IIFE functions, which are then compiled immediately. Thus, appealing to these heuristics ensures that a function is compiled before the end of script execution.
Furthermore, caching is performed on a per-script basis. This means updating the script will invalidate its cache. However, V8 developers identify contradicting reasons to either split or merge scripts to leverage code caching. For more on code caching, see “Code caching for JavaScript developers.”
Optimizing for parse times involves deferring parsing to worker threads and avoiding parsing entirely by maximizing the cache. With an understanding of the V8 parsing framework, we can deduce additional optimization methods not listed above.
Below are more resources for learning about the parsing framework, both as it applies to V8 and JavaScript parsing in general.
Tracking down the cause of a production JavaScript exception or error is time consuming and frustrating. If you’re interested in monitoring JavaScript errors and application performance to see how issues affect users, try LogRocket. https://logrocket.com/signup/
https://logrocket.com/signup/
LogRocket is like a DVR for web apps, recording literally everything that happens on your site.LogRocket enables you to aggregate and report on errors to see how frequent they occur and how much of your user base they affect. You can easily replay specific user sessions where an error took place to see what a user did that led to the bug.
LogRocket instruments your app to record requests/responses with headers + bodies along with contextual information about the user to get a full picture of an issue. It also records the HTML and CSS on the page, recreating pixel-perfect videos of even the most complex single-page apps.
Enhance your JavaScript error monitoring capabilities – Start monitoring for free.
Debugging code is always a tedious task. But the more you understand your errors, the easier it is to fix them.
LogRocket allows you to understand these errors in new and unique ways. Our frontend monitoring solution tracks user engagement with your JavaScript frontends to give you the ability to see exactly what the user did that led to an error.
LogRocket records console logs, page load times, stack traces, slow network requests/responses with headers + bodies, browser metadata, and custom logs. Understanding the impact of your JavaScript code will never be easier!
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now
Which AI frontend dev tool reigns supreme in July 2025? Check out our power rankings and use our interactive comparison tool to find out.

Learn how OpenAPI can automate API client generation to save time, reduce bugs, and streamline how your frontend app talks to backend APIs.

Discover how the Interface Segregation Principle (ISP) keeps your code lean, modular, and maintainable using real-world analogies and practical examples.

<selectedcontent> element improves dropdowns
