As the process of creating for the web continues to evolve we see that methods continue to get better. Engineers find ways to take the best parts of the best technologies and merge them together to create a more efficient system.

When fetching data in traditional web platforms, the process is mostly handled by the fetch API, the Axios library, or using a query language like GraphQL. This data is mostly handled at runtime. However, we have seen that while handling data at runtime we may notice that this routine in the application if not handled properly might lead to a larger load time than needed. As a solution, we can take advantage of some abstractions that fetch in some of our data at runtime while optimizing with static content at build time and offers performance advantages.
As with static sites, most of the data is pulled in at build time. In this article, we will be looking at how Gatsby, which is a PWA generator, uses GraphQL to pull in data at build time and also its implications on performance.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Gatsby offers three main methods of creating routes in sites — adding components to a page folder, programmatically creating pages from gatsby-node.js file with the CreatPages API, and using a plugin that can create pages.
These methods can all be used at the same time or individually and if used correctly will give the best Gatsby experience. To understand the advantages of GraphQL in Gatsby you will look at an example of a creating pages programmatically without GraphQL.
Gatsby allows you to use the createPages API in gatsby-node.js to programmatically create pages as seen in the code block below:
exports.createPages = ({ actions: { createPage } }) => {
createPage({
path: "/page-with-no-graphql/",
component: require.resolve("./src/templates/page-with-no-graphql"),
context: {
title: "Getting data without GraphQL!",
content: "<p>This is page content.</p><p>No GraphQL required!</p>",
},
})
}
In the code block above, we destructure the createPage function from the actions object and pass a path into it. This path is what shows up as the route when the page is being displayed. We also resolve a component which is the template layout the pages are going to fill. Lastly, the context of the pages is what is made available in the template with the pageContext object.
From the code block below, we can see that in the /src/templates/page-with-no-graphql file we can access the context in gatsby.node.js via pageContext:
import React from "react"
const WithContext = ({ pageContext }) => (
<section>
<h1>{pageContext.title}</h1>
<div dangerouslySetInnerHTML={{ __html: pageContext.content }} />
</section>
)
export default WithContext
After running gatsby develop, you’ll see the website at http://localhost:8000/page-with-no-graphql/ .
The drawback of this method is that we have to continuously change and update the context for every page we want to create. This feels like a task that can never be completed.
gatsby-node.jsTo solve the drawback of having to manually update the routes for each page created in gatsby-node.js Gatsby ships with GraphQL which gives you the ability to use queries to get a more descriptive view of the data you are fetching.
To make this process easier, the queries can be generated from a tool called GraphiQL, which is available at http://localhost:8000/___graphql after running gatsby develop.
The queries are generated for you by clicking on the boxes on the left. You can also test the query to see what they return by hitting the play button on the top left. This would display the expected values of the query and give an idea of how to get the value needed. It goes a step further to allow you to visualize the query in a component setting using the code exporter:
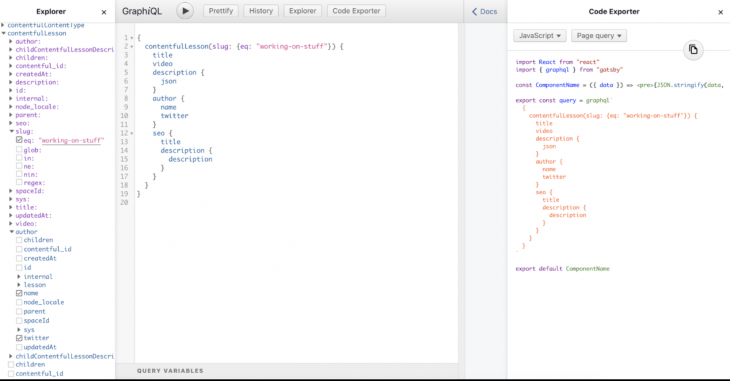
In gatsby-node.js, you can use the GraphQL query you just wrote to generate pages, like this:
exports.createPages = async ({ actions: { createPage }, graphql }) => {
const results = await graphql(`
{
allProductsJson {
edges {
node {
slug
}
}
}
}
`)
results.data.allProductsJson.edges.forEach(edge => {
const product = edge.node
createPage({
path: `/gql/${product.slug}/`,
component: require.resolve("./src/templates/product-graphql.js"),
context: {
slug: product.slug,
},
})
})
}
You need to use the graphql helper that’s available to the createPages Node API to execute the query. To make sure that the result of the query comes back before continuing, use async/await.
The results that come back are very similar to the contents of data/products.json, so you can loop through the results and create a page for each.
However, note that you’re only passing the slug in context — you’ll use this in the template component to load more product data.
As you’ve already seen, the context argument is made available to the template component in the pageContext prop. To make queries more powerful, Gatsby also exposes everything in context as a GraphQL variable, which means you can write a query that says, in plain English, ‘Load data for the product with the slug passed in context‘.
Here’s what that looks like in practice from the src/templates/product-graphql.js file:
import React from "react"
import { graphql } from "gatsby"
import Image from "gatsby-image"
export const query = graphql`
query($slug: String!) {
productsJson(slug: { eq: $slug }) {
title
description
price
image {
childImageSharp {
fluid {
...GatsbyImageSharpFluid
}
}
}
}
}
`
const Product = ({ data }) => {
const product = data.productsJson
return (
<div>
<h1>{product.title}</h1>
<Image
fluid={product.image.childImageSharp.fluid}
alt={product.title}
style={{ float: "left", marginRight: "1rem", width: 150 }}
/>
<p>{product.price}</p>
<div dangerouslySetInnerHTML={{ __html: product.description }} />
</div>
)
}
export default Product
gatsby-node.jsImagine a scenario where you could query for all the parameters your template would need in the gatsby-node.js. What would the implications be? In this section, we will look into this.
In the initial approach, you have seen how the gatsby-node.js file will have a query block like so:
const queryResults = await graphql(`
query AllProducts {
allProducts {
nodes {
id
}
}
}
`);
Using the id as an access point to query for other properties in the template is the default approach. However, suppose you had a list of products with properties you would like to query for. Handling the query entirely from gatsby-node.js would result in the query looking like this:
exports.createPages = async ({ graphql, actions }) => {
const { createPage } = actions;
const queryResults = await graphql(`
query AllProducts {
allProducts {
nodes {
id
name
price
description
}
}
}
`);
const productTemplate = path.resolve(`src/templates/product.js`);
queryResults.data.allProducts.nodes.forEach(node => {
createPage({
path: `/products/${node.id}`,
component: productTemplate,
context: {
// This time the entire product is passed down as context
product: node
}
});
});
};
};
You are now requesting all the data you need in a single query (this requires server-side support to fetch many products in a single database query).
As long as you can pass this data down to the template component viapageContext, there is no need for the template to make a GraphQL query at all.
Your template src/templates/product.js file will look something like this :
function Product({ pageContext }) {
return (
<div>
Name: {pageContext.name}
Price: {pageContext.price}
Description: {pageContext.description}
</div>
)
}
gatsby-node.jsUsing the pageContext props in the template component can come with its performance advantages of getting in all the data you need at build time — from the createPages API. This removes the need to have a GraphQL query in the template component. It does come with the advantage of querying your data from one place after declaring the context parameter.
However, it doesn’t give you the opportunity to know what exactly you are querying for in the template and if any changes occur in the component query structure in gatsby-node.js. Hot reload is taken off the table and the site needs to be rebuilt for changes to reflect.
Gatsby stores page metadata (including context) in a redux store (which also means that it stores the memory of the page). For larger sites (either number of pages and/or amount of data that is being passed via page context) this will cause problems. There might be “out of memory” crashes if it’s too much data or degraded performance:
If there is memory pressure, Node.js will try to garbage collect more often, which is a known performance issue.
Page query results are not stored in memory permanently and are being saved to disk immediately after running the query.
I recommend passing “ids” or “slugs” and making full queries in the page template query to avoid this.
Another disadvantage of querying all of your data in gatsby-node.js is that your site has to be rebuilt every time you make a change, so you will not be able to take advantage of incremental builds.
In this blog post, we have looked at how Gatsby uses GraphQL on its data layer to fetch static data at build time. We have also seen the performance implications of querying for all fields in the gatsby-node.js . I hope that this blog post has helped to unravel the “why” surrounding the relationship between these two technologies and how they help provide an amazing experience for Gatsby users. Happy coding and be sure to check out the Gatsby tutorials.
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Learn how next-browser gives AI agents runtime context for debugging Next.js apps, including React props, hydration, PPR, forms, and performance.

Build dynamic LLM routing in Next.js with OpenRouter, TanStack AI, task classification, model fallbacks, and cost-aware routing.

TSRX adds first-class control flow, conditional hooks, and scoped styles to React via a TypeScript compiler extension — no new framework required.

Learn how to build a full React Native auth system using Better Auth and Expo — with email/password login, Google OAuth, session persistence, and protected routes.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now