Almost every app has data, and that data has to be visualized in some way. A common method for displaying a set of data is via a list, which can become quickly become long and overwhelming to read.

There are three major ways to display large data sets: using pagination, load more buttons, and infinite scroll. In this tutorial, I’ll cover all three methods and discuss the pros and cons of using each one.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
These methods display large data sets on dynamic web pages while also providing faster initial page load. For example, Google Web uses pagination for its search answers.
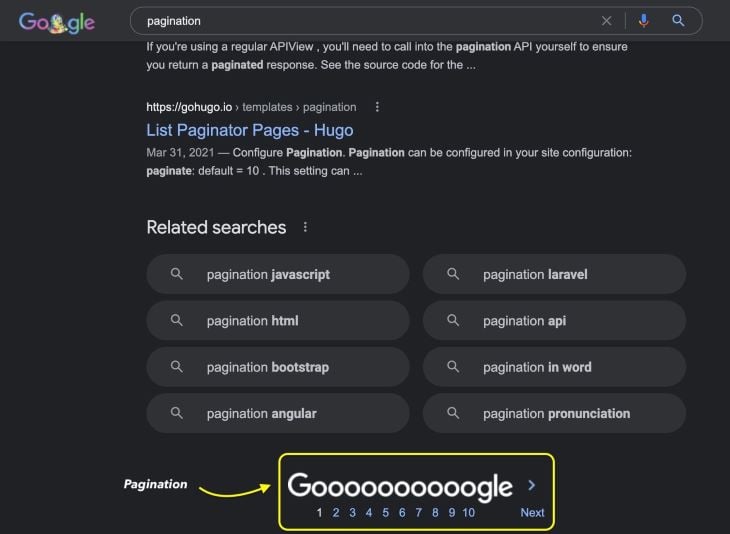
Twitter and Facebook use infinite scroll, where users keep scrolling to keep seeing new posts. Infinite scroll has become especially popular on social media channels.
On mobile, instead of using pagination, Google and Google Images use a load more button to display search results and images.
This article will compare each of these methods and guide you through implementing them into your apps.

If you are building a catalog or e-commerce website for the web, use pagination. However, if you are building any mobile website or an app, you’ll want to consider implementing a load more button instead.
Opinion: If you are displaying data in lists on mobile, then always avoid using this method. This method works well with grids.
If you are building any list visuals on mobile that do not have infinite scroll, use the load more method. You should also use this method if you’re app isn’t a social media app (where infinite scroll would be better to implement) and if you want the data load to be intuitive than pagination.
Keep in mind that in many apps (including social media), users refresh their feeds by swiping up, and, specifically in Instagram, by clicking New Posts. These are forms of load more mechanisms you can take inspiration from.
Also, you should consider using load more if you have tons of content but want users to reach a footer or hide content behind a paywall, or, in this case, a load more button.
 Of course, it’s unlikely that it’ll pass, but this sheds some light on how influential infinite scroll is when it comes to keeping users hooked on your platform
Of course, it’s unlikely that it’ll pass, but this sheds some light on how influential infinite scroll is when it comes to keeping users hooked on your platformYou can read more about why you shouldn’t use infinite scroll here.
If you are building a mobile app or social media app, or simply want users to continuously scroll through tons of content (i.e., blogs), you should use infinite scroll.
When the user reaches the end of the viewport, you load more results. In plain vanilla JavaScript, it works like this:
window.onscroll = function(ev) {
if ((window.innerHeight + window.scrollY) >= document.body.offsetHeight) {
// you're at the bottom of the page, load more content here.
}
};
// from stackoverflow (stackoverflow.com/questions/9439725/javascript-how-to-detect-if-browser-window-is-scrolled-to-bottom)
I have drawn a diagram to help explain how data is traversed through and how cursors work:
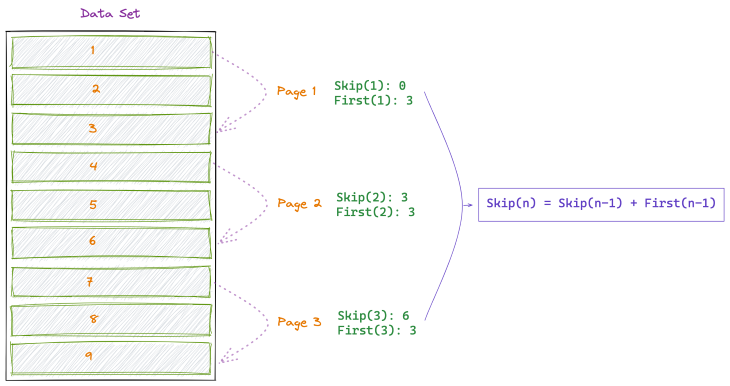
So, imagine you query the backend API and there are 900,000 total entries in the database. You wouldn’t want to fetch all of the entries because it would slow app performance.
For simplification, let’s use the number 9 instead of 900k.
To display this data, you’d have to divide it into multiple parts. It doesn’t have to be displayed in equal intervals, but it usually is. Here is a list of all the entries in the database.
{
"data": [
{ id: 1 },
{ id: 2 },
{ id: 3 },
{ id: 4 },
{ id: 5 },
{ id: 6 },
{ id: 7 },
{ id: 8 },
{ id: 9 }
]
}
Now, because it isn’t feasible to fetch them all at once, you can fetch the data in chunks from the database in the backend.
For the first result, you only want to fetch the first three entries.
To fetch the first page, query the database for “First 3 entries, After 0 entries”. For fetching the second page, query for “Fetch First 3 entries, After 3 entries,” and so on.
You may also use terms limit/offset instead of first/skip.
For pagination data fetching, another method often used is called cursors. When using cursors, the “after” value is used to fetch nodes after a specific point.
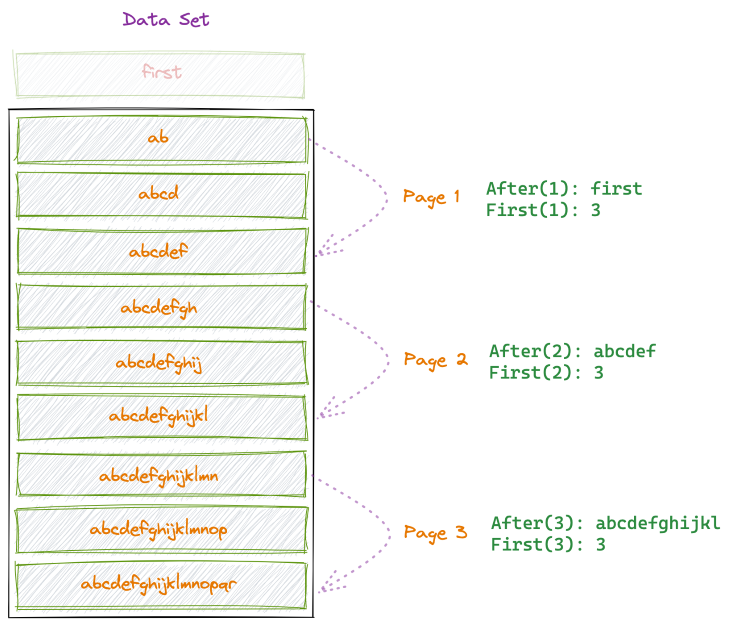
Here’s a comprehensive article explaining why you may want to use cursors instead of the limit/offset method.
When the backend fetches the selective data from the database, it sends a response that usually looks like this:
{
"data": [
{ id: 4 },
{ id: 5 },
{ id: 6 }
],
"totalCount": 9,
"fetchedCount": 3,
"pageInfo": {
"prevCursor": "prev_4", // <- this is usually converted to base64
"nextCursor": "after_6", // <- this is usually converted to base64
"hasNextPage": true // <- are there more pages remaining to fetch?
}
}
The front end then iterates over these cursors to fetch the pages of the paginated data.
This method remains similar for pagination, load more, and infinite scroll, so you could implement all of these by fetching data using the method described above.
For normal pagination, you would have to use both next and previous cursors. For load more and infinite scroll, you only need the next cursor, as you have to iterate through them to keep fetching more data.
Displaying large data sets in the most optimal manner is possible by using one — or a mixture of — some of these pagination methods. Happy coding.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

A step-by-step guide to building your first MCP server using Node.js, covering core concepts, tool design, and upgrading from file storage to MySQL.

Using security headers in your Next.js apps is a highly effective way to secure websites from common security threats.

A deep dive into April 2026’s AI model and tool rankings. We break down performance, usability, pricing, and real-world capabilities across 50+ features to help you pick the right tools for your development workflow.

A practical guide to Agent Browser CLI. Learn how AI agents navigate, snapshot, and interact with web pages using stable references, enabling efficient automation and exploratory testing.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

