GraphQLConf 2021 took place a few weeks ago, delivering talks by many great speakers on several hot topics being discussed within the GraphQL ecosystem, including:

The videos were recently uploaded, so I took the time to watch them all; selected a few talks on schema stitching, federation, architectural design, and ecommerce; and made a summary of them, which I present in this article. Enjoy!
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
In this video, Roy Derks walks us through an example of using schema stitching via @graphql-tools/stitch, and makes available a GitHub repo with the demo code.
Schema stitching is the art of combining the GraphQL schemas from different services into a single, unified GraphQL schema. The goal is to produce a gateway service from which we can access all services in our company.
Schema stitching was first introduced by Apollo, but they decided to discontinue it in favor of Apollo Federation. Most recently, The Guild has taken over the concept, re-implementing it and improving on the previous design, producing a solution that offers comparable benefits to federation while providing a simpler way of thinking about the problem.
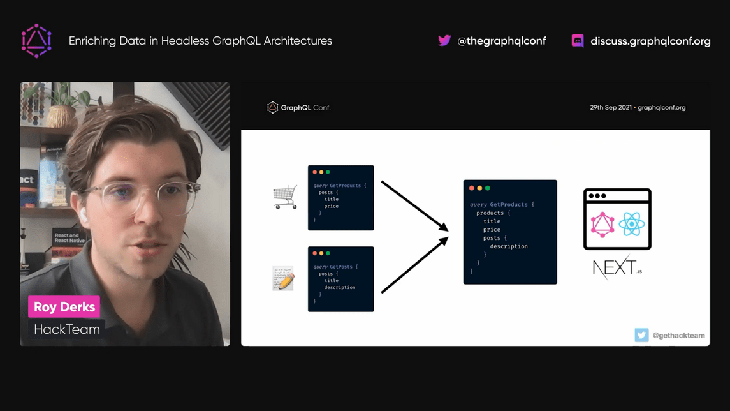
Roy uses schema stitching to demonstrate how to combine the data from two external services:
localhost:3001localhost:3002These two data sources are also combined with the schema from the local GraphQL server, available under localhost:3000.
The employed stack is based on:
@graphql-tools/stitchjson-graphql-server for quickly mocking up the external services@graphql-tools/schema to create the local GraphQL schemaAn API route from Next.js is created under api/graphql.js, which exposes the GraphQL endpoint under localhost:3000/api/graphql. We can interact with it via the GraphQL Playground, by opening the endpoint’s URL in the browser:
The relevant code in the API route to merge the schemas, in its simplest form, is the following:
let localSchema = makeExecutableSchema({
// Code here to create the local GraphQL schema
});
export default async function grapqhl(req, res) {
// Setup subschema configurations
const localSubschema = { schema: localSchema };
const cmsSubschema = await createRemoteSchema({
url: 'http://localhost:3001/graphql/'
});
const productsSubschema = await createRemoteSchema({
url: 'http://localhost:3002/graphql/',
});
// Build the combined schema and set up the extended schema and resolver
const schema = stitchSchemas({
subschemas: [localSubschema, productsSubschema, cmsSubschema]
});
}
This code sets up the local GraphQL schema using makeExecutableSchema, loading the remote GraphQL schemas from localhost:3001/graphql and localhost:3002/graphql using createRemoteSchema, and finally merging them all together using stitchSchemas.
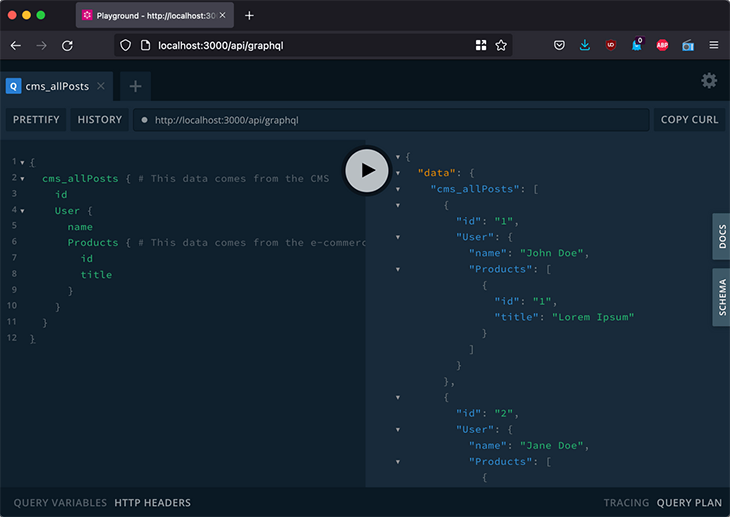
Next, we need to relate the schemas with each other, so that we can retrieve the products (provided by the ecommerce API) by the posts’ user IDs (provided by the external CMS):
{
cms_allPosts { # This data comes from the CMS
id
User {
name
Products { # This data comes from the e-commerce API
id
title
}
}
}
}
Combining the schemas is configured in stitchSchemas:
// Build the combined schema and set up the extended schema and resolver
const schema = stitchSchemas({
subschemas: [localSubschema, productsSubschema, cmsSubschema],
typeDefs: `
extend type Product {
cmsMetaData: [Cms_Product]!
}
`,
resolvers: {
Product: {
cmsMetaData: {
selectionSet: `{ id }`,
resolve(product, args, context, info) {
// Get the data for the extended type from the subschema for the CMS
return delegateToSchema({
schema: cmsSubschema,
operation: 'query',
fieldName: 'cms_allProducts',
args: { filter: { id: product.id } },
context,
info,
});
},
},
},
},
});
Finally, we must check if the different schemas expose their data under the same type or field name. For instance, the ecommerce API could also have a type called Post, and/or exposed under field allPosts, thus producing a conflict.
Avoiding these conflicts is accomplished via createRemoteSchema‘s transforms parameter, which allows us to rename the types and fields from one schema into something else. In this case, we have the subschema from the CMS rename its type Post into Cms_Post and field allPosts into cms_allPosts:
const cmsSubschema = await createRemoteSchema({
url: 'http://localhost:3001/graphql/',
transforms: [
new RenameRootFields(
(operationName, fieldName, fieldConfig) => `cms_${fieldName}`,
),
new RenameTypes((name) => `Cms_${name}`),
],
});
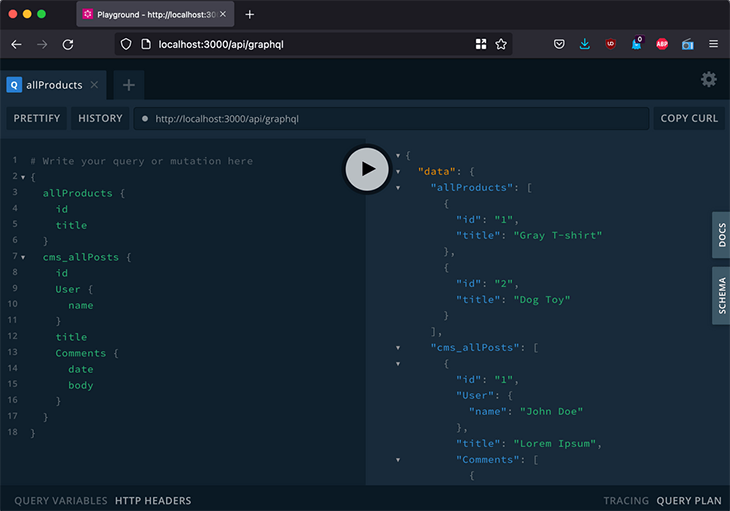
We can finally execute a query that fetches data from all separate services, accessed through a single, unified schema:
As previously mentioned, here are links if you’d like to look at the repo with the code or watch the full GraphQLConf video.
Tanmai Gopal is the co-founder and CEO of Hasura, a service providing realtime GraphQL APIs over Postgres.
Hasura is currently building their own version of federation, which is based on a different architecture than the one from Apollo Federation. In his talk, Tanmai walks us through all the challenges that Hasura’s federation solution is attempting to solve, and why Apollo Federation’s approach fails at addressing them.
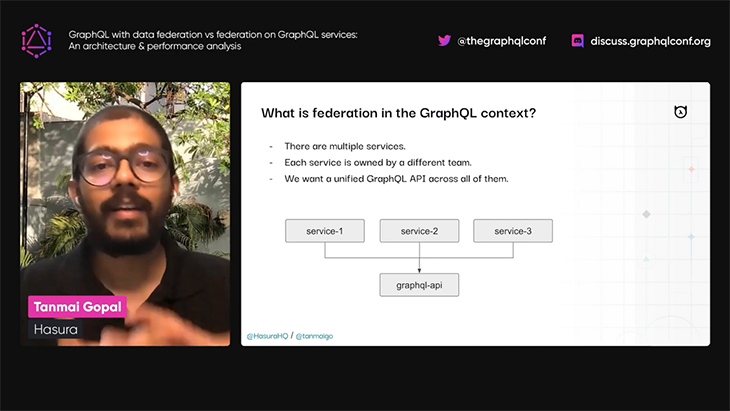
Tanmai first describes what federation is, and when and why its use is justified:
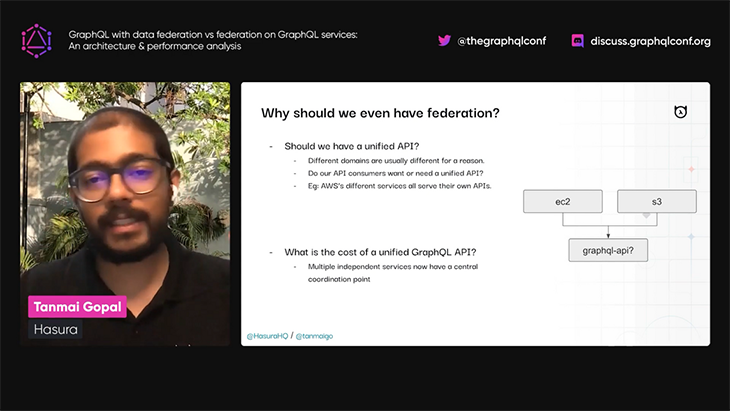
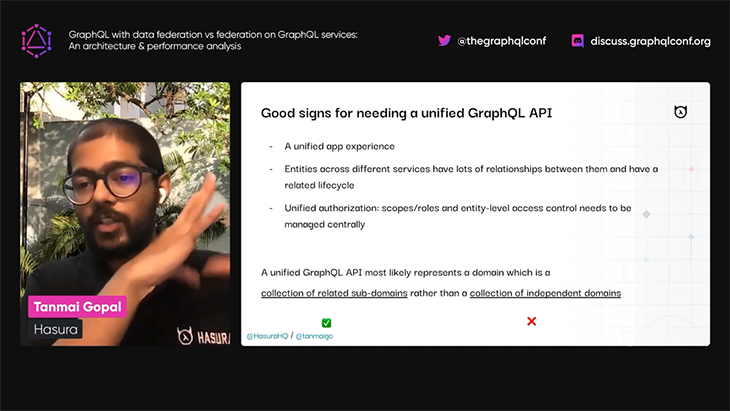
Tanmai then dives deep into two different ways of thinking about federation:
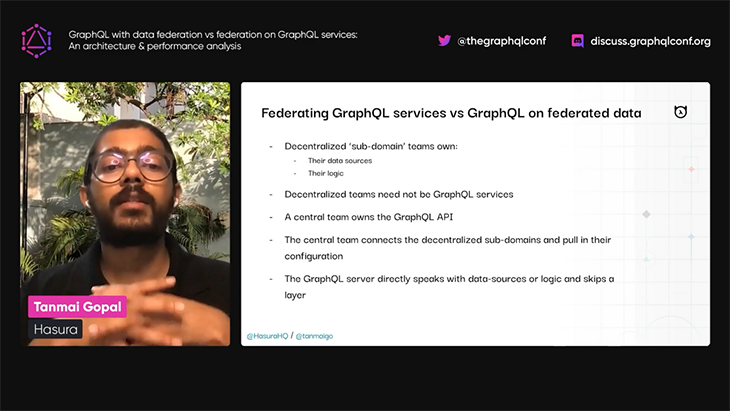
Tanmai then explains that while these two different approaches produce the same results, there is a sizable gain in performance when using the GraphQL on federated data approach:
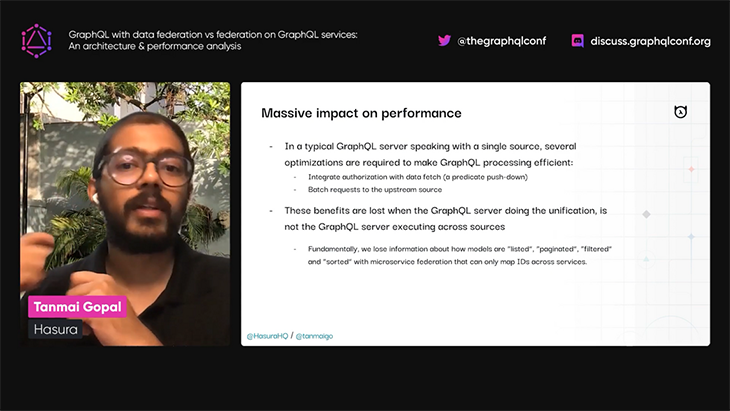
Tanmai provides a few example queries to describe why federating GraphQL services doesn’t scale well. He stresses that aggregating data across different services cannot be done efficiently, because, when resolving complex queries that contain cross-database joins across services, the gateway does not have a unified context for all entities across the involved subdomains.
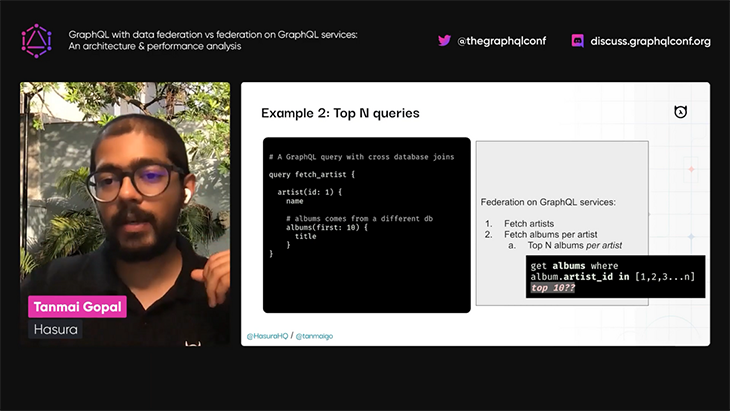
Finally, Tanmai explains that Hasura is working on a solution based on using GraphQL with federated data, which is able to fetch all relevant data from the different services and resolve the query from a centralized location, instead of having each service resolve its part of the query, thus providing better performance for complex queries.
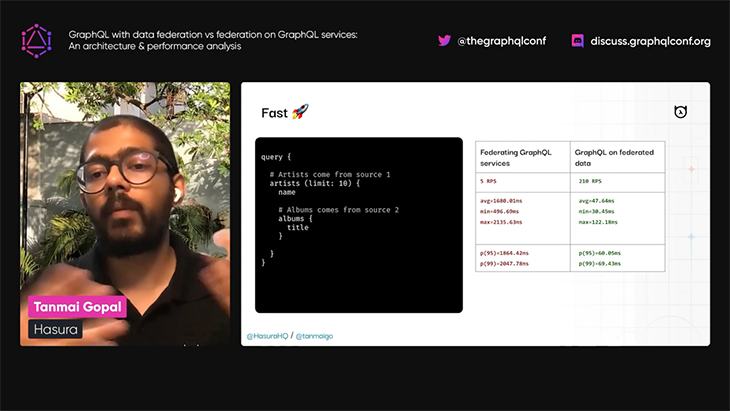
In order to compare Apollo’s and Hasura’s federation approaches, we will need to wait a bit more: Tanmai promises this new feature will be available soon, but doesn’t mention exactly when. The Hasura website doesn’t talk about it either, and there are no docs available yet. Currently, we only have the talk from this conference.
However, I imagine that Hasura’s approach is more restrictive than Apollo’s, since it will most likely depend on Hasura’s infrastructure to function, and its appeal will largely depend on Hasura’s price tag for the service. Apollo Federation, on the other hand, was designed as a methodology to split the graph based on directives, so it works without the need for any external tool or infrastructure (even though Apollo also offers managed federation), using preexisting syntax in GraphQL.
Finally, Hasura’s federation approach should be contrasted with GraphQL Tools’ schema stitching, which, as we saw from the previous talk, can deliver the same results in a simpler way.
Andrew Hoglund works as a senior software engineer for GitHub’s API team. In his talk, Andrew shares how his team is currently migrating the global identifier for all entities in GitHub’s GraphQL API to a different format, why they are doing it, and the challenges they’ve come across.
We can visualize the format for the global ID by querying for field id on any object. For instance, fetching the ID for the leoloso/PoP repository object can be done through this GraphQL query:
{
user(login: "leoloso") {
repository(name: "PoP") {
id
}
}
}
Executing the query, we obtain this response:
{
"data": {
"user": {
"repository": {
"id": "MDEwOlJlcG9zaXRvcnk2NjcyMTIyNw=="
}
}
}
}
The ID for the repository object is MDEwOlJlcG9zaXRvcnk2NjcyMTIyNw==. This format has the following properties:
Decoding the ID, for instance via a Bash command, will reveal the stored information:
$ echo `echo MDEwOlJlcG9zaXRvcnk2NjcyMTIyNw== | base64 --decode` 010:Repository66721227
The underlying data, 010:Repository66721227, is comprised of:
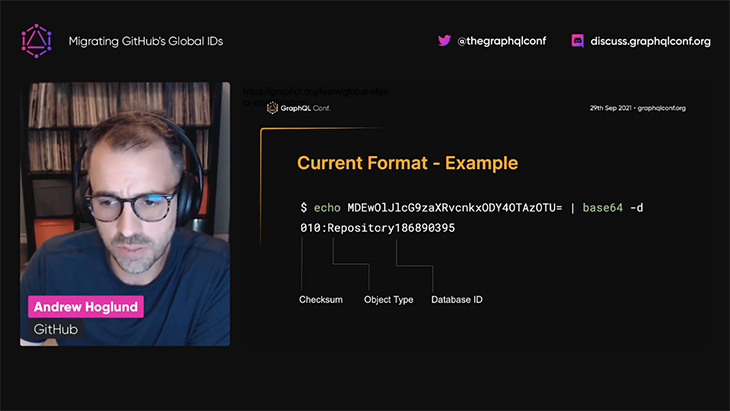
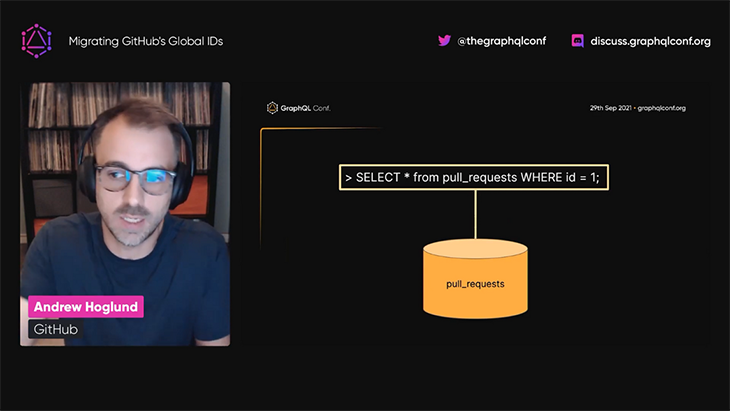
This simple format initially served GitHub well because GitHub had stored its data on a single database. The entity’s global ID already provided all the information required to locate the entity in the database and retrieve its data:
Some time later, GitHub used Vitess to migrate to a sharded database, which is a horizontal partition of the data within a database. Database shards can improve performance because, by spreading all data across multiple databases, each database table will have a reduced number of rows — thereby reducing the index size and making search faster — and different shards can be placed on different machines, which allows you to optimize the hardware for different pieces of data.
When querying the sharded database, the global ID format became unsuitable, even though it could still be used to retrieve the data, because the data for the entity would exist on only one database and not in all shards, and the global ID would not indicate which database the data was located in.
To locate the data, GitHub’s GraphQL API had to execute a query against all of the databases, from which just one of them would produce a match, making the query execution very ineffective:
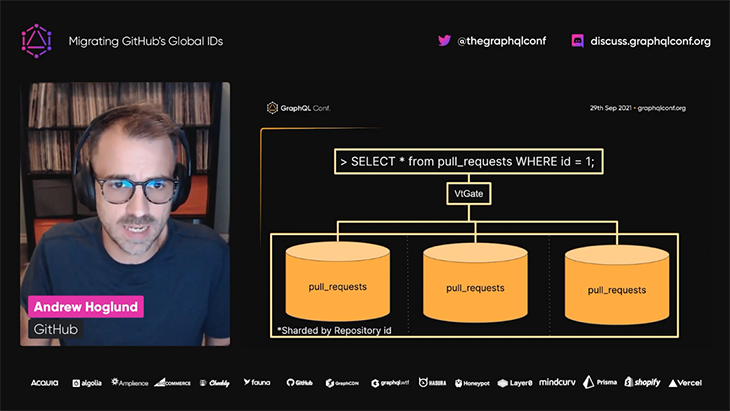
As a result, the GitHub API team decided to migrate the global ID to a new format, which would also provide the name of the database containing the entity data, so it could be retrieved efficiently once again:
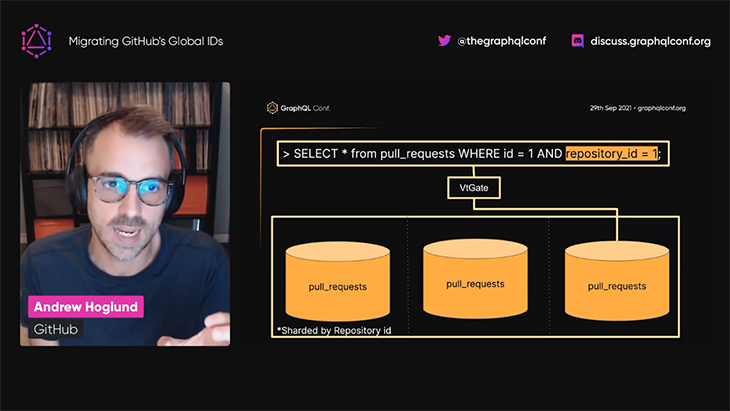
This new format is more complex than the previous one. It is composed of two elements:
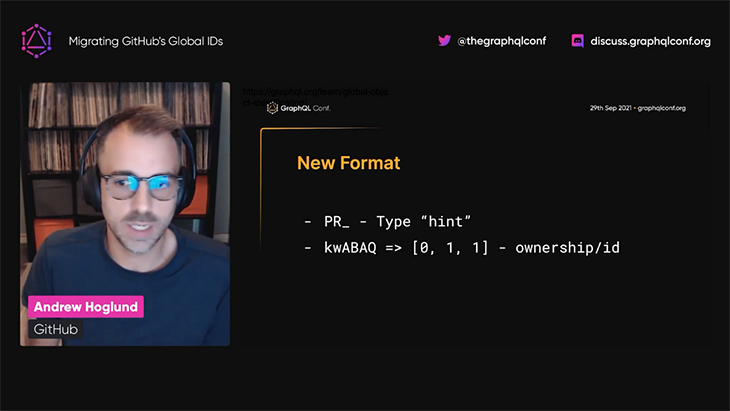
The ownership scheme is customized per entity, since different entities require different pieces of data to be identified. For instance, a workflow run requires the ID of the pull request that triggered it.
This new format works well, allowing GitHub to solve the current issues and anticipate some in the future. In particular, GitHub may eventually store its data in a multi-region setup, and the new format could also indicate the name of the region where the data is stored.
Because this new ID format is incompatible with the previous one, GitHub will need to implement a slow, progressive rollout to make sure it doesn’t break services. For this task, GitHub has put in place a deprecation period during which the two ID formats will coexist, and created tools to help services migrate from the old to the new format:
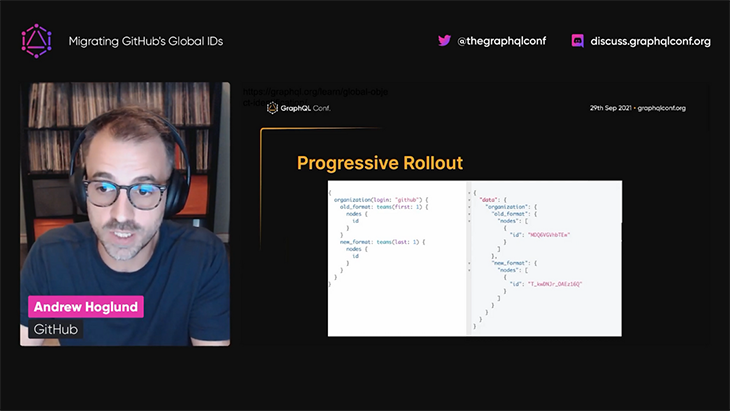
You can watch the video to learn more.
Stuart Guest-Smith is the principal architect lead at BigCommerce. In his talk, Stuart explores how merchants are able to build performant, scalable, and personalized ecommerce experiences with GraphQL.
Stuart opens the talk by declaring that:
Ecommerce requires companies to be fast, flexible, and personalized. GraphQL makes this possible, in a big way.
An ecommerce service will normally span multiple pieces of software, including, among others:
GraphQL enables us to access and relate the data from all these backend systems, achieving one of the latest trends of ecommerce, “composable commerce”:
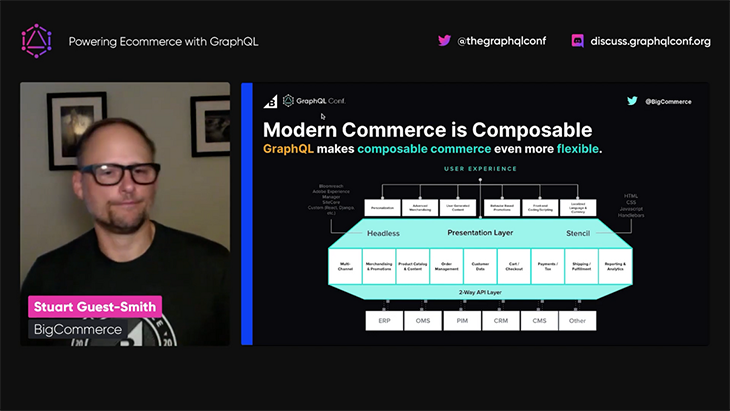
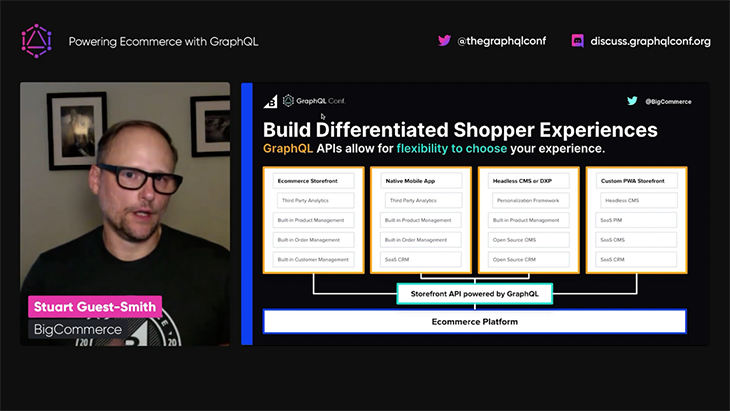
The data from these multiple backend systems can be made accessible via a GraphQL API to different frontends, such as:
This flexibility allows us to create a personalized and enhanced experience for our users.
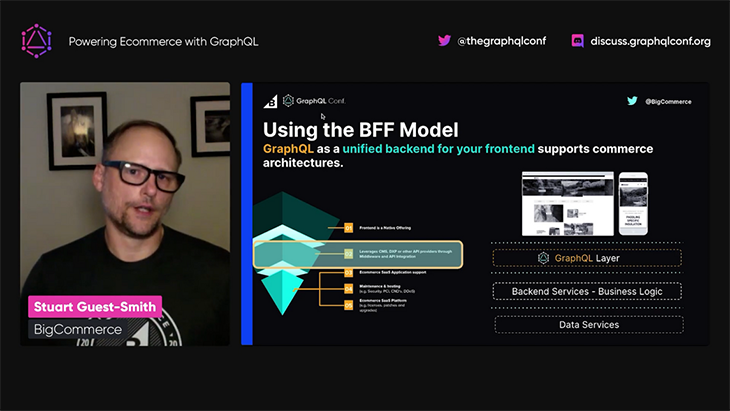
Stuart then explains that GraphQL can act as the interface between the multiple ecommerce backends and the multiple frontends by using the BfF architecture pattern, which aims to provide a customized backend per-user experience.
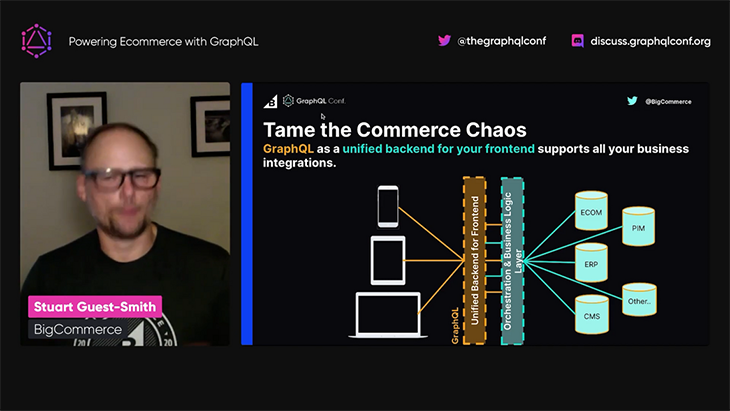
GraphQL can help performance since it can retrieve only the required data, without under- or over-fetching. But in addition, we must add a caching layer and manage the query complexity (or risk having malicious actors execute expensive queries that could slow down the system):
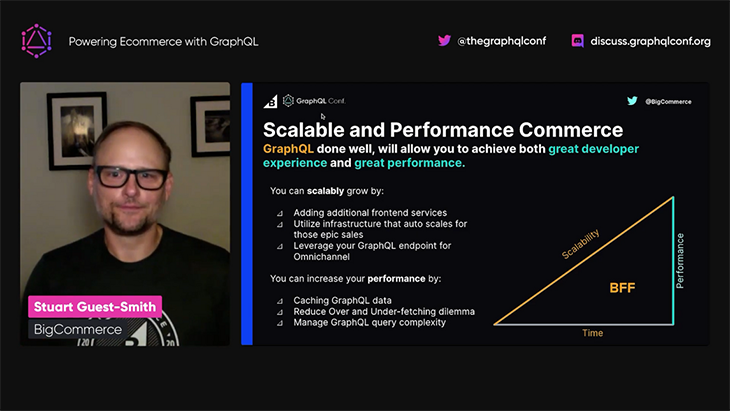
In conclusion, Stuart explains that one of the most important benefits that GraphQL delivers for ecommerce is the personalization of the customer experience:
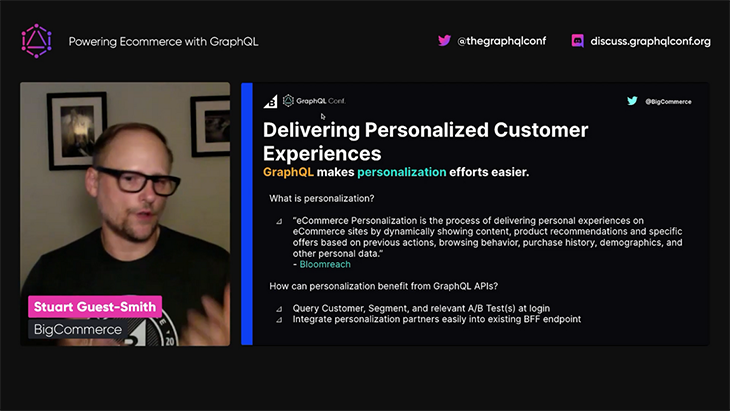
You can watch the full video here.
GraphQLConf 2021 brought us a glimpse of what’s being discussed in the GraphQL ecosystem right now, demonstrating that five years after GraphQL’s introduction there are still plenty of developments happening, with new methodologies being created to address the ongoing needs from the community.
This article summarizes talks on four different new developments:
@graphql-tools/stitch library for schema stitchingEven though GraphQL is mature, it is very exciting to see that new developments are happening! To find out what else is taking place, check out all videos from GraphQLConf 2021.
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

AI-generated tests can speed up React testing, but they also create hidden risks. Here’s what broke in a real app.re

Why the future of DX might come from the web platform itself, not more tools or frameworks.

A hands-on test of Claude Code Review across real PRs, breaking down what it flagged, what slipped through, and how the pipeline actually performs in practice.

CSS art once made frontend feel playful and accessible. Here’s why it faded as the web became more practical and prestige-driven.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

