GraphQL has gained widespread adoption by API developers in recent years. GraphQL’s flexible query language, strongly typed schema, focus on client data needs, tooling, community, and ecosystem have made it a great choice for client-facing applications and API authors.

There has been a rapid proliferation of open source tools and libraries to support the growing GraphQL community, and at this stage, GraphQL is an important technology to understand for frontend and backend developers alike.
GraphQL is typically introduced in comparison to REST, but at this point, these comparisons are very common and cover many of the basics differences between GraphQL and REST. Instead of reiterating these points, this article will focus on a few more nuanced differences between GraphQL and REST.
The information here should be beneficial to any GraphQL beginners looking to understand more advanced topics or a team considering adopting or migrating to GraphQL. Overall, this article will address three main topics:
REST APIs for web services tend to be built on top of HTTP and take advantage of core HTTP features such as HTTP request methods, HTTP response status codes, and HTTP caching.
For instance, imagine a typical REST API endpoint /user. A well-designed REST API will have various operations like GET /user, POST /user, PUT /user, and DELETE /user, which correspond to getting, creating, updating, and deleting a user resource, respectively.
These semantics are standardized with HTTP and allow API users to get predictable and understandable behavior from the API. A good REST API will reuse these semantics for the various resources it supports, and it should be easy for a consumer to understand what API requests correspond to specific resource operations.
GraphQL, in contrast, provides three basic schema types: Query, Mutation, and Subscription. Fetching data is relegated to queries, and mutations describe operations which will create, change, or remove data.
However, the implementation of these operations is totally up to the GraphQL API author, and the specification makes no restriction on how resources are model. The focus with GraphQL is more on how data is queried and less on how resources are modeled.
A GraphQL server might provide a user query and associated mutations such as updateUser, deleteUser, and so on. But these names are very subjective. Maybe the user query is called getUser or fetchUser instead of just user. Maybe the update operation is called changeUser or even putUser. Nothing intrinsically links these related “user” operations together in a GraphQL API.
GraphQL provides great API documentation and discoverability built in, with tools such as schema introspection and the GraphQL interface, but you can imagine how it could be hard to understand how to update some resource in a GraphQL schema with dozens or hundreds of defined object types.
It’s less straightforward than being able to rely on HTTP verbs such as GET, PUT, and POST, which all operate on a single resource endpoint. Then again, it’s important to remember that, in practice, REST APIs can often deviate from strictly following HTTP, and it’s not always as simple as just using a specific HTTP verb for the particular operation you’re looking for.
REST APIs can also take full advantage of HTTP caching. Typically, a web application will return HTTP headers with response data, which provide information to clients about how to cache the returned data.
Modern browsers ship with HTTP cache implementations that automatically provide caching at the HTTP layer. This allows applications to cache commonly requested resources without including any specific logic in client code. An application can just query resources, and any cached resources should be returned immediately. This is important for performance, user experience, and network data usage.
In GraphQL applications, client requests are all HTTP POST requests and completely bypass the standard HTTP caching mechanism. Because of this, GraphQL client applications tend to use a GraphQL client library like Apollo or Relay. These libraries provide a caching mechanism for queried data, which relies on globally unique IDs for queried object types (more info on GraphQL caching here).
This is very powerful but requires more work from developers to get the full benefit of caching. It also introduces a new surface error for gotchas and bugs, which can be hard to track down and fix (one example). This additional complexity can be difficult to understand and can potentially increase the overheard of onboarding new engineers.
Just as HTTP requests use standardized HTTP verbs to describe different types of actions, HTTP provides specific failure codes to describe response error states. For instance, tell any developer a request failed with status code 401, 404, or 500, and they’ll immediately have an idea what that means and why the request failed (bonus points if they also know for a 418 status code!).
This error code is part of the response object and can be parsed and used to programmatically determine how an application responds to failed requests. For example, 404 means a resource couldn’t be found, and 401 means a user is not authorized to perform whatever action they requested.
Furthermore, each HTTP request unequivocally results in a success or failure state. It’s very clear for the application to “know” the result of an HTTP request.
In GraphQL, however, the story is totally different. To start with, a GraphQL query could map to many different resolving functions, any of which could fail. As a result, a response could be partially successful and partially failed at the same time. For instance, consider a GraphQL schema such as this:

And a query for some data:

Now, imagine that the query objects user, posts, and comments have different resolving functions and that the resolvers for posts and comments fail for some reason. You will receive some response data like this:
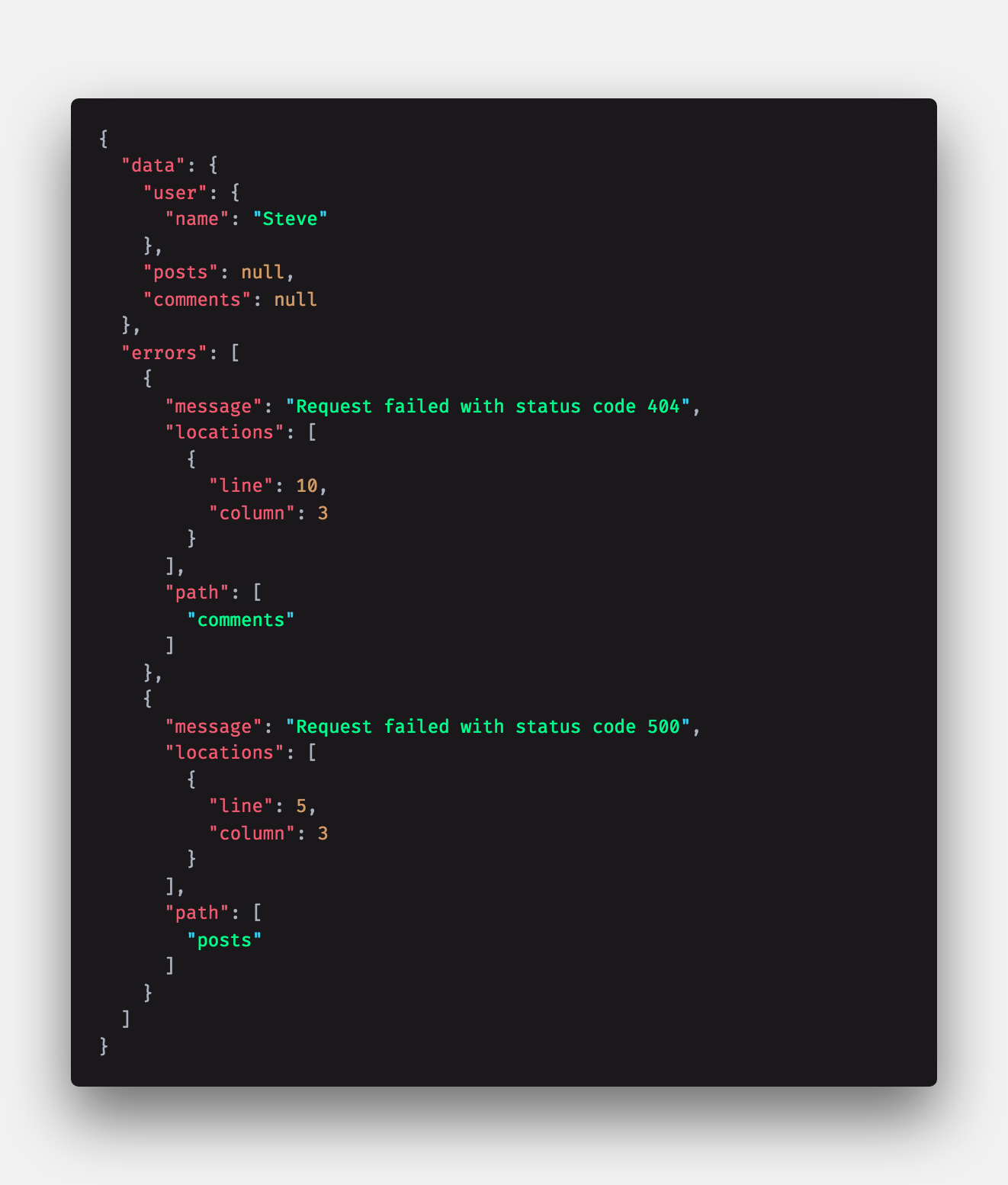
Let’s look at what happened! The entire query did not fail. In fact, even if the user query failed, you would get a similar failure response. This entire response comes back with HTTP status code 200; there is no sense of success or failure at the HTTP layer.
Furthermore, there is no sense of overall success or failure for a GraphQL request (unless the request doesn’t match the provided schema or there is a network error) since some objects could be fetched successfully while others could have resulted in errors.
To begin to understand error states for the request, you have to try to parse the response data directly. If you look closely, the errors response is an array of objects, where each object includes some information about the specific query path that failed.
You’ll see a serialized message containing a reason which is just a string. Determining if a specific query failed and why involves parsing this array of errors and also parsing each error object.
You will need to build some specific logic to extract the error information and try to determine the failure cause. It’s not very straightforward to extract a status code or any server-sent error message since GraphQL stringifies the entire error response into this message field.
Keeping track of these different failure modes and determining the correct result for your application is simply not as straightforward with GraphQL compared to a REST API where each request has a clear success or failure state and, in the case of failure, a clear cause of failure. Then again, GraphQL is still evolving, and it’s likely the error handling story will improve with time.
GraphQL presents a very different API surface to API consumers. For instance, most GraphQL server implementations provide schema introspection or informative error messages by default, such as:
"message": "Cannot query field \"login\" on type \"Mutation\". Did you mean \"loginUser\"?",
Obfuscating your GraphQL schema in production by disabling features like introspection will make it that much harder for any bad actor to understand how to make requests against your API (then again, they can always guess or observe network traffic from your application to understand what data your API accepts).
Another very cool pattern here is to use persisted queries to specifically whitelist the exact queries your application uses and map them to some hash or key. Then, your request actually provides that key, instead of the query name itself.
Furthermore, your GraphQL server can be designed to reject any queries that don’t match the whitelisted query patterns. This reduces network bandwidth usage and improves the security of your application by introducing a lot more friction for someone trying to misuse your API. For more information about persisted queries, you can take a look here or here.
Typically, applications rate-limit APIs on a per user, per request, or even per IP basis to control usage and mitigate DDoS attempts or other API misuse. This is fairly straightforward with a traditional REST API.
With GraphQL, however, you can make a single request for an entire GraphQL schema in one query. Or you could make several smaller requests for the same data. How can you effectively rate-limit these different usage patterns?
The emerging practice with GraphQL is to rate-limit on a per object or per field basis and/or to use query cost/complexity analysis to implement rate limiting. Query complexity is a method to statically analyze a query to determine how “complex” it will be for your server to process it.
For instance, requesting dozens of documents in a single query will be measured as more “complex” than just making a query for a single document. Cost/complexity could be measured by query depth, amount, limits (pagination offsets), and so on. The idea is to rate-limit requests based on how complex they are rather than on the number of requests within a specified time period.
There are already many open-source tools and libraries designed for this purpose — for instance, graphql-rate-limit, graphql-cost-analysis, graphql-validation-complexity, and graphql-query-complexity.
To learn more about this, take a look at GitHub’s description of resource limitations for their public v4 API, which relies on GraphQL. This is a very interesting, real-world example of how this problem is handled.
On top of the query complexity, a common security vulnerability modern web applications need to be cognizant of is a distributed denial-of-service (DDoS) attack, where a bad actor orchestrates a number of machines to make requests against an application in great enough volume to bring the system offline.
This vulnerability exists with other servers as well, but in the case of a GraphQL server, your API schema may expose potentially complex and expensive query patterns that could bring down your system easily. Imagine a query for some blog with a comment system that allows recursively replying to comments, such as this:
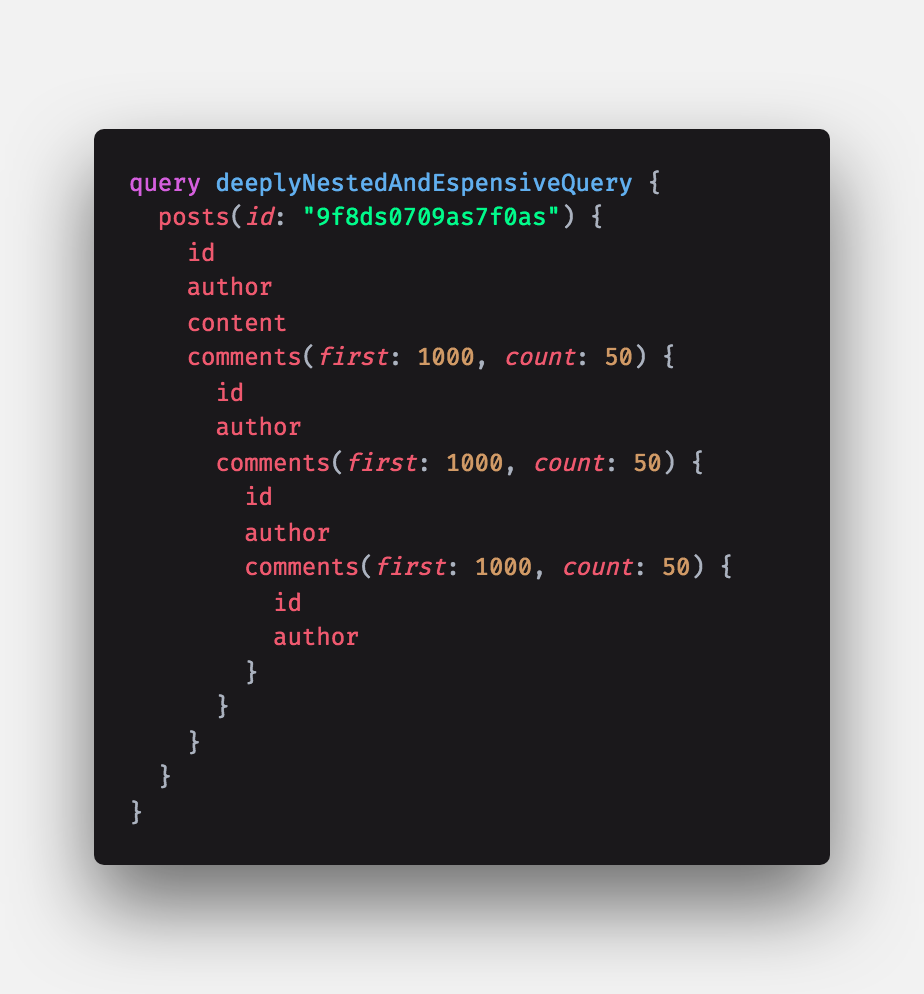
Not all GraphQL schemas would expose queries like this, but it’s possible such a query could be very expensive to calculate and return. A single bad actor with a single machine could make a few dozen requests like this and potentially bring down your system.
This would be a unique and rare situation, but it’s important to be aware of; attackers are definitely keen to find tricks like this. Approaches mentioned above such as rate-limiting by query cost or using persisted queries could be used to mitigate problems like this. This article talks in greater depth about securing a GraphQL application.
GraphQL takes a totally different approach to API design and brings with it many benefits and advantages, but also unique challenges and differences. Neither GraphQL, REST, nor any other approach is purely better or worse, but each has its own unique design considerations, constraints, and tradeoffs.
Here, we looked at some more advanced differences between GraphQL and REST. We covered HTTP semantics, error handling, and security implications that a REST developer might find unexpected or surprising when adopting GraphQL.
Hopefully this article has helped to illuminate some of the more subtle differences between GraphQL and REST and can help you better understand the tradeoffs and compromises when considering either alternative.
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Discover how React Fiber works under the hood. Learn how React builds the DOM, handles concurrent rendering, and works alongside React 19 features and the new React Compiler.

Learn how to use Skybridge, an open-source React framework, to build and deploy cross-platform AI apps and interactive UI widgets for ChatGPT, Claude, and MCP clients from a single codebase.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

