A graph in its simplest form is a collection of nodes and relationships. A graph database is a database management system that uses the graph data model (nodes and relationships) to perform create, read, update, and delete (CRUD) operations. Graph databases are designed to treat the relationship between nodes as first-class citizens. This means connections between data would not need to be inferred using foreign keys.

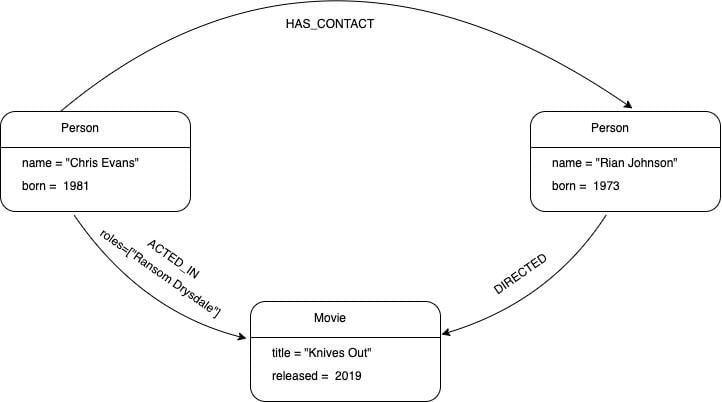
A node is an entity (such as a person, place, object, or relevant piece of data) in a graph. The simplest possible graph is a single node.

Labels are used to group nodes into sets such that all nodes that are tagged with a certain label belonging to the same set. Node labels may also be used to attach metadata (such as index or constraint) to certain nodes. In our example graph above, all nodes representing persons are labeled with :Person.
A relationship is a connection between two nodes. A relationship always has a direction, a type, a start node, and an end node.
Our example graph has ACTED_IN, HAS_CONTACT, and DIRECTED as relationship types. The Chris Evans node has an outgoing relationship, while the “Knives Out” node has an incoming relationship.
Properties are key-value pairs that are used to add attributes to nodes and relationships.
In our example graph, we used the properties name and born on Person nodes, title and released on Movie nodes, and the property roles on the :ACTED_IN relationship.
Property values can be any of the following data types:
IntegerFloatStringBooleanPointDateTimeLocalTimeDateTimeLocalDateTime, andDurationWe live in a world that is highly connected. Today, companies manage large, interconnected data sets. The best way to leverage data relationships is to use a technology that places great importance on relationships. This is exactly what a graph database does. A graph database stores relationship information as a first-class entity.
Because graph databases do not follow rigid schemas, they are best suited for today’s agile teams where business requirements change rapidly. With a graph database, you have the flexibility to expand your database to conform to changing business needs.
Graph databases have been designed to support efficient data retrieval, allowing you to traverse millions of connections in real time.
There are so many graph databases. The table below shows the top graph databases (source: DB-Engines).
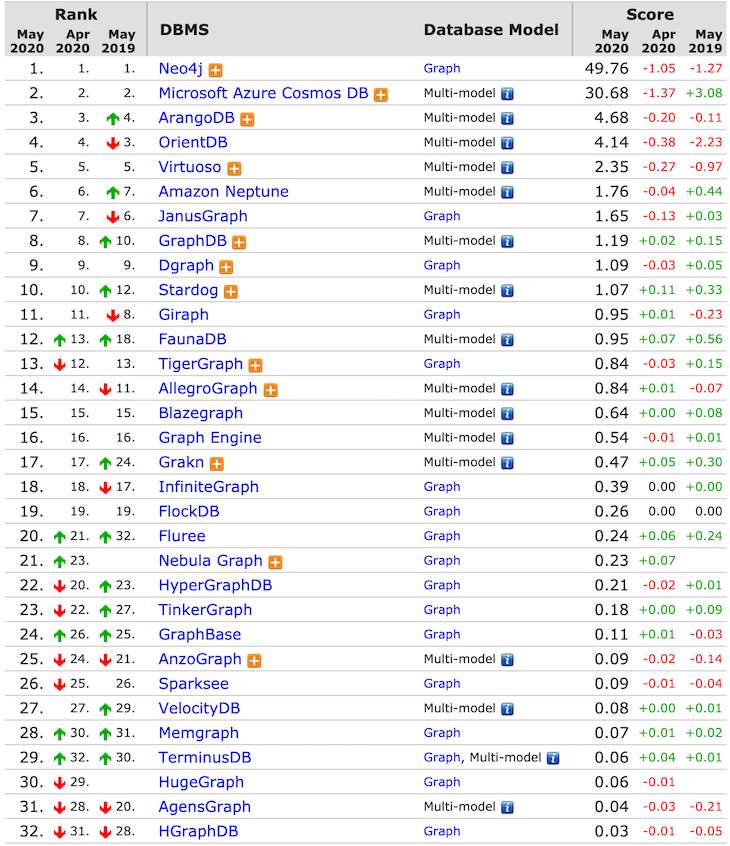
As you can see, Neo4j is the most popular graph database system. In this tutorial, we’ll walk you through how to use Neo4j database.
Neo4j is an open-source, NoSQL, native graph database that provides an ACID-compliant transactional backend for your applications.
Neo4j is said to be a native graph database because it efficiently implements the property graph model down to the storage level. It also provides full database characteristics, such as ACID transaction compliance, cluster support, and runtime failover. Neo4j supports its own query language called Cypher.
There is a variety of ways to interact with and use graph data in Neo4j. For the purpose of this tutorial, we’ll use Neo4j Desktop.
Neo4j Desktop has support for Cypher by default and does not require a separate driver installation. Download Neo4j Desktop for your operating system and then follow the installation instructions.
Cypher is Neo4j’s graph query language. It allows users to store and retrieve data from the graph database.
Neo4j’s Cypher querying language is easy for anyone to learn, understand, and use. Cypher incorporates the power and functionality of other standard data access languages.
Before we explore how to query a Neo4j graph database, let’s create a new database and populate it with data.
Open your installed Neo4j desktop app and create a new database called learn-neo4j. Open the new database in the Neo4j browser and run the query below to populate the database with initial data.
// post data
CREATE (johnnyMnemonic:Movie {title:"Johnny Mnemonic",tagline:"The hottest data on earth. In the coolest head in town",released:1995} )
CREATE (sleepless:Movie {title:"Sleepless in Seattle",tagline:"What if someone you never met, someone you never saw, someone you never knew was the only someone for you?",released:1993})
CREATE (dreams:Movie {title:"What Dreams May Come", tagline:"After life there is more. The end is just the beginning.",released:1998} )
CREATE (dina:Person {name:"Dina Meyer", born:1968} )
CREATE(ice:Person {name:"Ice-T", born:1958})
CREATE(keenu:Person {name:"Keanu Reeves", born:1964})
CREATE(takeshi:Person {name:"Takeshi Kitano", born:1947})
CREATE (robert:Person {name:"Robert Longo", born:1953})
CREATE (meg:Person {name:"Meg Ryan", born:1961} )
CREATE (cuba:Person {name:"Cuba Gooding Jr.", born:1968} )
CREATE (vin:Person {name: "Vincent Ward", born:1956})
CREATE (dina)-[:ACTED_IN { roles: ["Jane"]}]->(johnnyMnemonic)
CREATE (ice)-[:ACTED_IN { roles: ["J-Bone"]}]->(johnnyMnemonic)
CREATE (keenu)-[:ACTED_IN { roles: ["Johnny Mnemonic"]}]->(johnnyMnemonic)
CREATE (takeshi)-[:ACTED_IN { roles: ["Takahashi"]}]->(johnnyMnemonic)
CREATE (meg)-[:ACTED_IN {roles:["Annie Reed"]} ]->(sleepless)
CREATE (robert)-[:DIRECTED]->(johnnyMnemonic)
CREATE (cuba)-[:ACTED_IN]->(dreams)
CREATE (cuba)-[:HAS_CONTACT]->(vin)
CREATE (vin)-[:DIRECTED]->(dreams)
CREATE (cuba)-[:HAS_CONTACT]->(meg)
CREATE (meg)-[:HAS_CONTACT]->(dina)
CREATE (robert)-[:HAS_CONTACT]->(meg)
CREATE (robert)-[:HAS_CONTACT]->(vin)
CREATE (robert)-[:HAS_CONTACT]->(cuba)
To retrieve a node in a Neo4j graph, we use the MATCH statement. A MATCH statement will search for the patterns we specify and return one row per pattern successfully matched.
You can find all nodes that exist in a graph.
MATCH (n) RETURN n
n is a variable that represents all matched nodes. In this case, it’s all nodes in our graph. Here’s the result:

We can limit our query to search for specific nodes by adding the label of the node.
MATCH (n:Person)
RETURN n
╒═══════════════════════════════════════╕
│"n" │
╞═══════════════════════════════════════╡
│{"name":"Dina Meyer","born":1968} │
├───────────────────────────────────────┤
│{"name":"Robert Longo","born":1953} │
├───────────────────────────────────────┤
│{"name":"Meg Ryan","born":1961} │
├───────────────────────────────────────┤
│{"name":"Cuba Gooding Jr.","born":1968}│
├───────────────────────────────────────┤
│{"name":"Vincent Ward","born":1956} │
└───────────────────────────────────────┘
The query returned only nodes labeled Person.
The simplest type of relationship match is achieved by connecting a node with another node using -- without specifying a direction.
MATCH(m)--(n) RETURN m, n
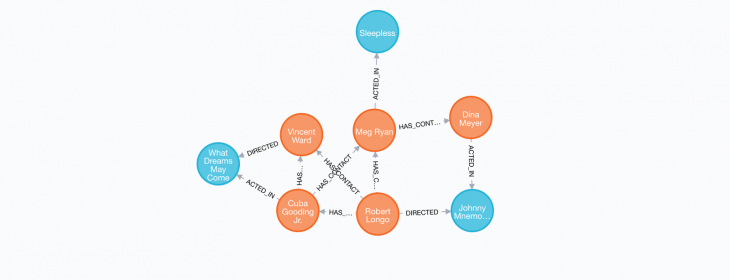
The -- indicates a relationship that connects nodes m and n.
The above Cypher query does not return any information about the relationship. To get relationship information, we need to assign a variable to the relationship. Relationship variables are assigned a name within a square bracket([]).
MATCH(m)-[rel]-(n) RETURN m, rel, n
You can also specify the direction of the relationship by using a < or > at either end of the connecting nodes.
To match a node m that has a relationship with node n, the query would look like this:
MATCH(m)-[rel]->(n) RETURN m, rel, n
Here we are matching any node that has any relationship to another node. To match a specific relationship, we would have to add the relationship type.
Our graph database has a relationship type called :ACTED_IN. Let’s match a node connected to another node by the :ACTED_IN relationship.
MATCH(m)-[rel:ACTED_IN]-(n) RETURN m, rel, n
To restrict our search to specific nodes, we can add labels to the node.
MATCH(someone:Person)-[rel:ACTED_IN | DIRECTED]-(movie:Movie)
RETURN someone, rel, movie
╒══════════════════╤════════════════════════╤══════════════════════╕
│"someone.name" │"rel" │"movie.title" │
╞══════════════════╪════════════════════════╪══════════════════════╡
│"Robert Longo" │{} │"Johnny Mnemonic" │
├──────────────────┼────────────────────────┼──────────────────────┤
│"Dina Meyer" │{"roles":["Jane"]} │"Johnny Mnemonic" │
├──────────────────┼────────────────────────┼──────────────────────┤
│"Meg Ryan" │{"roles":["Annie Reed"]}│"Sleepless in Seattle"│
├──────────────────┼────────────────────────┼──────────────────────┤
│"Vincent Ward" │{} │"What Dreams May Come"│
├──────────────────┼────────────────────────┼──────────────────────┤
│"Cuba Gooding Jr."│{} │"What Dreams May Come"│
└──────────────────┴────────────────────────┴──────────────────────┘
The pipe character (|) indicates that the relationship could be of type ACTED_IN or DIRECTED.
So far, we have matched nodes and relationships in our graph database and returned all the results we found. Now let’s walk through how to filter the results and only return a specific subset of data.
Cypher filtering can be done either by specifying properties of interest in a MATCH statement using curly braces ({}) or by using the WHERE clause.
MATCH(someone{ name: "Robert Longo" })
RETURN someone
╒═══════════════════════════════════╕
│"someone" │
╞═══════════════════════════════════╡
│{"name":"Robert Longo","born":1953}│
└───────────────────────────────────┘
Neo4j would search all nodes looking for a node that has the name property and a value of Robert Longo.
You can restrict the search to certain nodes by adding a label.
MATCH(someone:Person{ name: "Robert Longo" })
RETURN someone
╒═══════════════════════════════════╕
│"someone" │
╞═══════════════════════════════════╡
│{"name":"Robert Longo","born":1953}│
└───────────────────────────────────┘
A search can also be a person against multiple comma-separated properties.
MATCH(someone:Person{ name: "Robert Longo", born: 1953 })
RETURN someone
╒═══════════════════════════════════╕
│"someone" │
╞═══════════════════════════════════╡
│{"name":"Robert Longo","born":1953}│
└───────────────────────────────────┘
WHERE clauseYou can also perform filtering with the WHERE clause. Let’s rewrite the above filtering using the WHERE clause.
MATCH(robert: Person) WHERE robert.name = "Robert Longo" AND hugo.born = 1953 RETURN robert;
This will return the same result as the one above.
There are a couple of comparison operators that can be used together with the WHERE clause. In the WHERE clause example above, we used a comparison operator (=) to compare the name property of a node and the value Hugo Weaving. Other operators are: <, >, <=, >=, and <> (not equal to).
MATCH(person: Person)
WHERE person.born >= 1960
RETURN person;
╒═══════════════════════════════════════╕
│"person" │
╞═══════════════════════════════════════╡
│{"name":"Dina Meyer","born":1968} │
├───────────────────────────────────────┤
│{"name":"Meg Ryan","born":1961} │
├───────────────────────────────────────┤
│{"name":"Cuba Gooding Jr.","born":1968}│
└───────────────────────────────────────┘
MATCH(person: Person)
WHERE person.born <> 1968 AND person.born <> 1956
RETURN person;
╒═══════════════════════════════════╕
│"person" │
╞═══════════════════════════════════╡
│{"name":"Robert Longo","born":1953}│
├───────────────────────────────────┤
│{"name":"Meg Ryan","born":1961} │
└───────────────────────────────────┘
Boolean operators allow you to perform advanced filtering. With boolean operators, you can combine multiple WHERE statements into one.
We’ve yet to examine an example of a boolean operator AND in the WHERE clause example above. OR, NOT, IN, and XOR are other boolean operators which you can use to perform filtering.
MATCH(person: Person)
WHERE person.born = 1961 OR person.born = 1962 OR person.born = 1963
RETURN person;
╒═══════════════════════════════╕
│"person" │
╞═══════════════════════════════╡
│{"name":"Meg Ryan","born":1961}│
└───────────────────────────────┘
The above query returned persons that were born in 1961, 1962, or 1963. If you want to expand the query and add more years, it can become long and a bit tedious to write out. You can use the IN operator instead of OR when the values to compare become large.
MATCH(person: Person)
WHERE person.born IN [1960, 1961, 1962, 1963, 1964, 1965]
RETURN person;
╒═══════════════════════════════╕
│"person" │
╞═══════════════════════════════╡
│{"name":"Meg Ryan","born":1961}│
└───────────────────────────────┘
To match a broader range, such as years between 1960 and 2000, you can have a combination of the boolean operator AND and comparison the operators <= and >=.
MATCH(person: Person)
WHERE person.born >= 1960 AND person.born <= 2000
RETURN person;
╒═══════════════════════════════════════╕
│"person" │
╞═══════════════════════════════════════╡
│{"name":"Dina Meyer","born":1968} │
├───────────────────────────────────────┤
│{"name":"Meg Ryan","born":1961} │
├───────────────────────────────────────┤
│{"name":"Cuba Gooding Jr.","born":1968}│
└───────────────────────────────────────┘
Ordering is done using the ORDER BY expression [ASC|DESC] clause. ORDER BY sorts nodes and relationships using the properties of the node or relationship.
Pagination is done using the SKIP {offset}and LIMIT {count} clauses
ORDER BYMATCH(actor: Person)-[:ACTED_IN]->(movie:Movie)
WHERE movie.title = "Johnny Mnemonic"
RETURN actor
ORDER BY actor.born
╒═════════════════════════════════════╕
│"actor" │
╞═════════════════════════════════════╡
│{"name":"Takeshi Kitano","born":1947}│
├─────────────────────────────────────┤
│{"name":"Ice-T","born":1958} │
├─────────────────────────────────────┤
│{"name":"Keanu Reeves","born":1964} │
├─────────────────────────────────────┤
│{"name":"Dina Meyer","born":1968} │
└─────────────────────────────────────┘
The query returned all actors in the movie “Johnny Mnemonic” in the ascending order of their birth year. To return the actors in the descending order of their birth year, add the DESC keyword after the variable used to perform the sorting.
MATCH(actor: Person)-[:ACTED_IN]->(movie:Movie)
WHERE movie.title = "Johnny Mnemonic"
RETURN actor
ORDER BY actor.born DESC
╒═════════════════════════════════════╕
│"actor" │
╞═════════════════════════════════════╡
│{"name":"Dina Meyer","born":1968} │
├─────────────────────────────────────┤
│{"name":"Keanu Reeves","born":1964} │
├─────────────────────────────────────┤
│{"name":"Ice-T","born":1958} │
├─────────────────────────────────────┤
│{"name":"Takeshi Kitano","born":1947}│
└─────────────────────────────────────┘
SKIP and LIMITIf you do not want the top n results, you can trim if off with SKIP. SKIP accepts any expression that evaluates to a positive integer .
MATCH(actor: Person)-[:ACTED_IN]->(movie:Movie)
WHERE movie.title = "Johnny Mnemonic"
RETURN actor
ORDER BY actor.born DESC
SKIP 2
╒═════════════════════════════════════╕
│"actor" │
╞═════════════════════════════════════╡
│{"name":"Ice-T","born":1958} │
├─────────────────────────────────────┤
│{"name":"Takeshi Kitano","born":1947}│
└─────────────────────────────────────┘
There are four actors for the “Johnny Mnemonic” movie. The first two actors were skipped and the others returned.
LIMIT will constrain the number of rows in the result. Just like SKIP, LIMIT accepts any expression that evaluates to a positive integer.
MATCH(actor: Person)-[:ACTED_IN]->(movie:Movie)
WHERE movie.title = "Johnny Mnemonic"
RETURN actor
ORDER BY actor.born DESC
SKIP 2
LIMIT 1
╒════════════════════════════╕
│"actor" │
╞════════════════════════════╡
│{"name":"Ice-T","born":1958}│
└────────────────────────────┘
The result of the query was limited to a single row.
Cypher also supports aggregation operations, such as calculating averages, sums, minimum/maximum, and counts.
In Cypher, aggregation happens in the RETURN clause while computing the final results. Common aggregation functions are: count, sum, avg, min, max, etc.
countcount() returns the number of values or rows that match an expression.
There are two different ways of performing count() operation. The first is by using count(n) to count the number of occurrences of n (the result does not include null values).
The alternative way to perform the count() operation is with count(*), which counts the number of result rows returned (including those with null values).
Here’s how you could count the number of actors that appeared in the movie “Johnny Mnemonic”:
MATCH(actor: Person)-[:ACTED_IN]->(movie:Movie) WHERE movie.title = "Johnny Mnemonic" RETURN count(actor) ╒══════════════╕ │"count(actor)"│ ╞══════════════╡ │4 │ └──────────────┘
To count only unique values, use DISTINCT. For example: count(DISTINCT actor).
sumsum() returns the sum of a set of numeric values or duration. Assuming that the :ACTED_IN relationship in our graph has a numeric property called earning, you can calculate the money earned by a particular actor for the film in which they acted.
MATCH(actor:Person)-[role:ACTED_IN ]-(movie:Movie) WHERE actor.name = "Dina Meyer" RETURN sum(role.earning)
avgavg() returns the average of a set of numeric values or duration. To calculate the average birth year of actors in our database:
MATCH(actor:Person)-[role:ACTED_IN ]-(movie:Movie) RETURN avg(actor.born) ╒═════════════════╕ │"avg(actor.born)"│ ╞═════════════════╡ │1961.0 │ └─────────────────┘
max and minmax() returns the maximum value in a set of numeric values, while min() returns the minimum value.
In Cypher, string functions are used to convert nonstring values into strings and to manipulate existing strings in certain ways. Common string functions include toString, toUpper, toLower, trim, etc.
toStringThe toString() function converts an integer, float, or boolean value to its string equivalent.
RETURN toString(true) ╒════════════════╕ │"toString(true)"│ ╞════════════════╡ │"true" │ └────────────────┘
toUpper and toLowerThe toUpper() function accepts a string value and returns the original string in uppercase. toLower() returns the original string in lowercase.
RETURN toLower("STRING")
╒═══════════════════╕
│"toLower("STRING")"│
╞═══════════════════╡
│"string" │
└───────────────────┘
trimtrim() accepts a string and returns a new string with the leading and trailing spaces removed.
RETURN trim(" I will be trimmed ")
╒═══════════════════════════════════╕
│"trim(" I will be trimmed ")"│
╞═══════════════════════════════════╡
│"I will be trimmed" │
└───────────────────────────────────┘
Math functions operate on numeric values only. If a non-numeric value is used with a math function, the database will throw an error.
Math functions in Cypher include ceil, floor, rand round, etc.
floorfloor() returns the greatest floating point value less than or equal to an expression.
RETURN floor(0.9) ╒════════════╕ │"floor(0.9)"│ ╞════════════╡ │0.0 │ └────────────┘
ceilceil() returns the greatest floating point value greater than or equal to an expression.
RETURN ceil(0.9) ╒═══════════╕ │"ceil(0.9)"│ ╞═══════════╡ │1.0 │ └───────────┘
roundround() returns the value of the given number rounded to the nearest integer.
╒═════════════════╕ │"round(3.141592)"│ ╞═════════════════╡ │3.0 │ └─────────────────┘
randrand() returns random floating point values between 0 (inclusive) and 1.
RETURN rand() ╒═════════════════╕ │"rand()" │ ╞═════════════════╡ │0.161308614578638│ └─────────────────┘
Inserting a node in Cypher is very similar to matching a node. Instead of the MATCH keyword used for matching, we’ll use CREATE for data insertion. CREATE can be used to insert nodes and relationships.
CREATE()
The above Cypher statement is the simplest way to add a node to the graph. It creates an anonymous node without labels and properties.
You can create a node with a label using : followed by the name of the label.
CREATE(:Person)
You can also assign multiple labels to a node.
CREATE(:Person :Actor)
If we execute the above statement, Cypher returns the number of changes, in this case adding one node and two labels. If you also want to return the created, data you can add a RETURN statement.
CREATE(person:Person :Actor) RETURN person
Properties are added to the node using curly brackets({}).
CREATE(john:Person{name:"John Doe", born:1900} )
RETURN john
╒═══════════════════════════════╕
│"john" │
╞═══════════════════════════════╡
│{"name":"John Doe","born":1900}│
└───────────────────────────────┘
If you want to create more than one node, you can separate the nodes with commas or use multiple CREATE statements.
CREATE(john:Person{name:"John Doe", born:1900} )
CREATE(jane:Person{name:"Jane Doe", born:1800} )
RETURN jane, john
CREATE(john:Person{name:"John Doe", born:1900} ), (jane:Person{name:"Jane Doe", born:1800} )
RETURN jane, john
╒═══════════════════════════════╤═══════════════════════════════╕
│"jane" │"john" │
╞═══════════════════════════════╪═══════════════════════════════╡
│{"name":"Jane Doe","born":1800}│{"name":"John Doe","born":1900}│
└───────────────────────────────┴───────────────────────────────┘
you can also create relationships, such as an ACTED_IN relationship with information about the actor, or DIRECTED ones for a director.
CREATE (tom:Person { name:"Tom Hanks", born:1956 })-[roles:ACTED_IN { roles: ["Forrest"]}]->(movie:Movie { title:"Forrest Gump",released:1994 })
CREATE (robert:Person { name:"Robert Zemeckis", born:1951 })-[:DIRECTED]->(movie) RETURN tom,roles,movie, robert
Properties and relationships can also be added to an existing node. To add new information to a node, first match the existing node and then attach the newly created nodes to them with relationships.
To add “Cloud Atlas” as a new movie for Tom Hanks, do the following:
MATCH (tom:Person { name:"Tom Hanks" })
CREATE (movie:Movie { title:"Cloud Atlas",released:2012 })
CREATE (tom)-[role:ACTED_IN { roles: ['Zachry']}]->(movie)
RETURN tom,role,movie
The Cypher query above will create a :Movie node and :ACTED_IN in relationship for every matched node. In many cases, this is what you want.
If that’s not intended, then we need to use the MERGE statement. MERGE acts like a combination of MATCH or CREATE, which checks for the existence of data first before creating it. With MERGE, you define a pattern to be found or created.
If you don’t know whether your graph already contains the movie “Cloud Atlas” but want to add the :ACTED_IN relationship to it, you can use the MERGE statement to ensure that “Cloud Atlas” is not recreated if it already exists.
MATCH (tom:Person { name:"Tom Hanks" })
MERGE (movie:Movie { title:"Cloud Atlas",released:2012 })
MERGE (tom)-[role:ACTED_IN { roles: ['Zachry']}]->(movie)
RETURN tom,role,movie
If you already have a node or a relationship in the database but want to modify or update the properties, you can do this by first matching the node or relationship and then using the SET clause to update the properties.
We could update Tom’s node to add a birthdate property, for example.
MATCH (tom:Person { name:"Tom Hanks" })
SET tom.birthday = date("1956-07-01")
RETURN tom
╒════════════════════════════════════════════════════════╕
│"tom" │
╞════════════════════════════════════════════════════════╡
│{"birthday":"1956-07-01","name":"Tom Hanks","born":1956}│
└────────────────────────────────────────────────────────┘
Cypher uses the DELETE keyword to delete nodes and relationships. Because Neo4j is ACID-compliant, you cannot delete a node that has a relationship attached to it if the node still has relationships.
The first step toward deleting a node is to delete its relationships.
First, match the start and end nodes and then use the DELETE keyword, as shown in the statement below.
Go ahead and delete the ACTED_IN relationship between Tom Hanks and “Cloud Atlas.”
MATCH (tom:Person { name:"Tom Hanks" })-[role:ACTED_IN]-(:Movie{title: "Cloud Atlas"})
DELETE role
Deleting a node is as simple as matching the node and then using the DELETE keyword, just as we did for the relationship above.
To delete Tom Hanks’ node:
MATCH (tom:Person { name:"Tom Hanks" })
DELETE tom
you can delete a node and a relationship at the same time using the DETACH DELETE syntax. The DETACH DELETE syntax tells Cypher to delete any relationships the node has, as well as remove the node itself.
MATCH (tom:Person { name:"Tom Hanks" })
DETACH DELETE tom
The graph database — especially Neo4j — is a fantastic technology that can be applied to numerous scenarios.
The use cases that have the most value are those that have data models that are highly connected, causing your queries become long and complex to read, write, and understand. Examples include fraud detection, real-time recommendation engines, network and IT operations, identity and access management (IAM), and more.
There’s no doubt that frontends are getting more complex. As you add new JavaScript libraries and other dependencies to your app, you’ll need more visibility to ensure your users don’t run into unknown issues.
LogRocket is a frontend application monitoring solution that lets you replay JavaScript errors as if they happened in your own browser so you can react to bugs more effectively.
LogRocket works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and @ngrx/store. Instead of guessing why problems happen, you can aggregate and report on what state your application was in when an issue occurred. LogRocket also monitors your app’s performance, reporting metrics like client CPU load, client memory usage, and more.
Build confidently — start monitoring for free.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

I migrated 20 production-style components from Tailwind to StyleX. Here’s what the data showed about LOC, CSS bundle size, build time, and type safety.

A guide for using JWT authentication to prevent basic security issues while understanding the shortcomings of JWTs.

Discover how to build, render, and automate product demo videos with Remotion, replacing traditional screen recordings with reusable React code.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

