A single processor can process tasks from many different jobs at a speed that makes it seem as though they are all occurring simultaneously. For example, we multitask on our computers every day. Each job, whether it is a Chrome tab or a Node.js application, is referred to as a thread. The overall increase in processing speed has come from having multiple cores, where each core is like its own processor processing multiple threads:

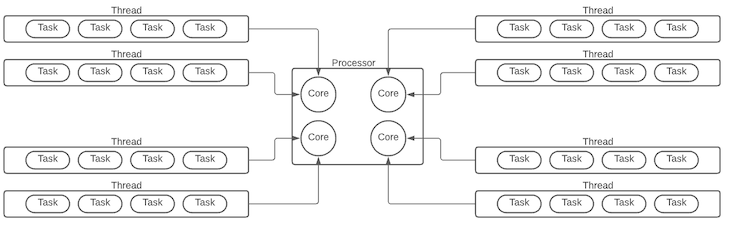
Each thread can handle only a single task at a time. If one task takes a long time, it can freeze up the application, creating a poor user experience. With concurrency, we can avoid this.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Many different concurrency patterns are used across programming languages. For example, we can avoid blocking tasks on a single thread using event loops, like in JavaScript. Additionally, you can spin off parallel threads or child processes or distribute these thread across multiple cores.
However, when we use concurrency in this manner, there are still some logistical issues to consider. For example, how can you coordinate these independent threads so that one thread, which depends on another, doesn’t run into errors? If the two threads share state, how can that state be used by both threads at the same time?
Every language handles these questions differently. In this article, we’ll examine how these are handled in Rust.
Rust handles these questions in a unique way, so developers avoid the typical choice between high-level and low-level languages.
High-level languages often choose one approach, requiring trade-offs to provide a single abstraction, which will be more performant in certain cases than in others. On the other hand, low-level languages often lack abstractions, aiming to provide the flexibility to create optimal solutions for different projects, obviously requiring a lot more work upfront.
Instead, Rust has different concurrency abstractions for various use cases, which provides the ability to maximize performance and minimize errors in a more robust way.
In Rust, you can create 1:1 threads. Rust doesn’t natively have the features of bundling threads, keeping Rust’s runtime minimal. However, you can create a thread and run a series of tasks on that thread. Let’s examine the code below:
use std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
for i in 1..5 {
// print i, then sleep thread for 2 milliseconds
println!("Secondary Thread Prints {}", i);
thread::sleep(Duration::from_millis(2));
}
});
for i in 1..5 {
// print i, then sleep thread for 2 milliseconds
println!("Main Thread Prints {}", i);
thread::sleep(Duration::from_millis(1));
}
}
When we run the program above, a main thread is created to run this code. When we see the thread::spawn call, a new thread is created, running the code enclosed in it. The code after it runs concurrently on the main thread, and both should count from 1 to 4. You should see a result like the following:
Main Thread Prints 1 Secondary Thread Prints 1 Main Thread Prints 2 Secondary Thread Prints 2 Main Thread Prints 3 Main Thread Prints 4 Secondary Thread Prints 3
Notice that the secondary thread never finishes counting. It is a child of the main thread, which has completed first. We can tell the code to wait for the secondary thread to finish before going further. We’ll save the secondary thread in a variable, and using its join method, we’ll pause the main thread until the child thread is completed:
use std::thread;
use std::time::Duration;
fn main() {
let secondary_thread = thread::spawn(|| {
for i in 1..5 {
// print i, then sleep thread for 2 milliseconds
println!("Secondary Thread Prints {}", i);
thread::sleep(Duration::from_millis(2));
}
});
for i in 1..5 {
// print i, then sleep thread for 2 milliseconds
println!("Main Thread Prints {}", i);
thread::sleep(Duration::from_millis(1));
}
secondary_thread.join().unwrap();
}
Now, you’ll see the following code:
Main Thread Prints 1 Secondary Thread Prints 1 Main Thread Prints 2 Secondary Thread Prints 2 Main Thread Prints 3 Main Thread Prints 4 Secondary Thread Prints 3 Secondary Thread Prints 4
You can read more about creating multiple threads in the Rust documentation.
The Go programming language popularized the concept of channels. You can think of channels as a pipeline for one thread to send data to another so that they can share it. The main thread can create a channel that the child thread can then use to send data back and forth:
use std::sync::mpsc;
use std::thread;
fn main() {
// create a channel
let (sender, receiver) = mpsc::channel();
// create a new thread, create a value, send the value using the channel to main thread
thread::spawn(move || {
let val = String::from("I was created in the child thread, will be sent to main thread");
sender.send(val).unwrap();
});
// receive and print the message from the child thread
let received = receiver.recv().unwrap();
println!("I have received this message from the child thread: {}", received);
}
The output should be as follows:
I have received this message from the child thread: I was created in the child thread, will be sent to main thread
With the code above, the main thread creates a channel before creating the child thread. The channel is made up of two objects, the sender or transmitter for sending data, and the receiver for receiving data.
If your code has to do some expensive calculation, you could offset it to another thread, then use the channel to get the result back in the main thread without having to block it. You can learn more about message passing in the Rust Documentation.
While you can use channels to pass values back and forth, the memory to store these values isn’t shared. But maybe you want to share memory between your threads to reduce memory usage. In this scenario, we’ll use mutex objects in Rust.
A mutex object can contain a value that one thread can take ownership of at any point in time. Any thread that wants to use the mutex must claim the object, lock it, use the data, and unlock it. Otherwise, another thread can’t claim it.
It can be tricky to coordinate and ensure that all the locking and unlocking happens in an orderly fashion. However, for data that can be used in many threads, it can provide benefits in memory usage.
To make sure this mutex object can be shared safely between threads, we need to give it some guarantee of atomicity, all or nothing changes, which can be done by wrapping it an Arc object:
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
// create the mutex to have shared state
// Wrap it in an Arc object to share safely
let shared_state = Arc::new(Mutex::new(0));
// create a vector to hold all the threads
let mut threads = vec![];
// loop 16 times, create a thread on each loop, that uses the mutex
for _ in 0..16 {
// create an atomic copy of the shared state
let shared_state = Arc::clone(&shared_state);
let child_thread = thread::spawn(move || {
// lock the shared state in this thread
let mut num = shared_state.lock().unwrap();
// mutate the shared_state
*num += 1;
});
// push thread into vector
threads.push(child_thread);
}
// make sure to wait for all threads to complete
for child_thread in threads {
child_thread.join().unwrap();
}
// the lock shared state and print it in the main thread
println!("Result: {}", *shared_state.lock().unwrap());
}
In the code above, we take the value of 0 and wrap it in a mutex for sharing. We then wrap that in an Arc object to give it atomicity between threads.
We create an array to hold all our child threads and loop 16 times. During each loop, we clone the shared_state, create a new thread from which we lock the shared_state, and increment it. In total, 16 threads will use this shared state.
The threads are pushed into the vector, so we can loop over the vector to make sure the main thread waits for their completion. Then, we print the final value of the shared state. The result is as follows:
Result: 16
When each loop is run, they mutate the same data in memory. You can read more about sharing state between threads in the Rust documentation.
Rust tries to keep concurrency features limited. Notice that to use the features we did, we had to import them from the standard library. They are libraries, not native language features, meaning that you can use the same primitives to create your own concurrency abstractions. Primarily, this is achieved by implementing the Send and Sync traits from the std::marker library. To understand these two traits and more, check out the Rust documentation.
Rust aims to be a low-level language that still provides strong typed abstractions, making the developer’s life easier. When it comes to concurrency in Rust, you can spawn child threads, pass data between threads using channels like Go, or share state between thread using Arc and mutex. These are all built into the standard library, which gives you the building blocks to extend this even further.
I hope you enjoyed this tutorial! Please leave a comment if you have any questions. Happy coding.
Debugging Rust applications can be difficult, especially when users experience issues that are hard to reproduce. If you’re interested in monitoring and tracking the performance of your Rust apps, automatically surfacing errors, and tracking slow network requests and load time, try LogRocket.
LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.

Modernize how you debug your Rust apps — start monitoring for free.

Why the future of DX might come from the web platform itself, not more tools or frameworks.

A hands-on test of Claude Code Review across real PRs, breaking down what it flagged, what slipped through, and how the pipeline actually performs in practice.

CSS art once made frontend feel playful and accessible. Here’s why it faded as the web became more practical and prestige-driven.

Learn how inline props break React.memo, trigger unnecessary re-renders, and hurt React performance — plus how to fix them.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

