To build a modern web application today, we need a decent database to feed our application data. There are many databases we can choose from. In this post, we will learn how to use PostgreSQL as our database to consume the data required for our Jamstack application.

The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
“A modern web development architecture based on client-side JavaScript, reusable APIs, and prebuilt Markup.” – Mathias Biilmann, CEO & co-founder of Netlify
The term Jamstack stands for JavaScript, APIs, and Markup, and it’s a modern way to build our application. Jamstack applications split the code (the app), infrastructure (API), and content (markup) handled in a decoupled architecture, meaning there’s a separation between the server-side and client-side.
It is possible to build the entire application statistically served via a CDN instead of running a monolith backend that is generating dynamic content. But this application is based on API, which ideally results in a much faster experience.
There are several great performance frameworks we can use to leverage the benefits of Jamstack. Some of the noticeable ones are Remix, SevelteKit, Nuxt, Next, 11ty, Gatsby, and Astro.
We will use Next.js to build a simple application, then use PostgreSQL to serve data with connection pooling.
We will set up a blank Next.js project using the CLI. This will create a preconfigured application.
npx create-next-app@latest --typescript
Let’s name the application nextjs-pg-connection-pool, then add the necessary dependencies to start querying our Postgres database.
npm i pg @types/pg
We will connect to the local Postgres database and query the data needed. Let’s use the CLI and enter the following:
psql Postgres
Next, create a fresh new instance of the Postgres database to interact with and list the database we have in our local machine. You can also use a free Postgres database provided by AWS, Heroku, or GCP and connect with a connection string provided to you.
CREATE DATABASE employeedb \l
We can successfully see the name of the database we just created.
For us to start querying the database through our application, we need to connect our application and the local Postgres database. There are multiple ways to do this, such as using open source libraries like pgbouncer, pgcat, pgpool, etc.
For this article, we will use one of the most popular Postgres connection clients called node-postgres, a nonblocking PostgreSQL client for Node.js written in pure JavaScript.
When a client connects to a PostgreSQL database, the server forks a process to handle the connection. Our PostgreSQL database has a fixed maximum number of connections, and once we hit the limit, additional clients cannot connect.
Each active connection consumes about 10MB of RAM. We can overcome these potential issues via connection pooling.
Let’s look at two approaches:
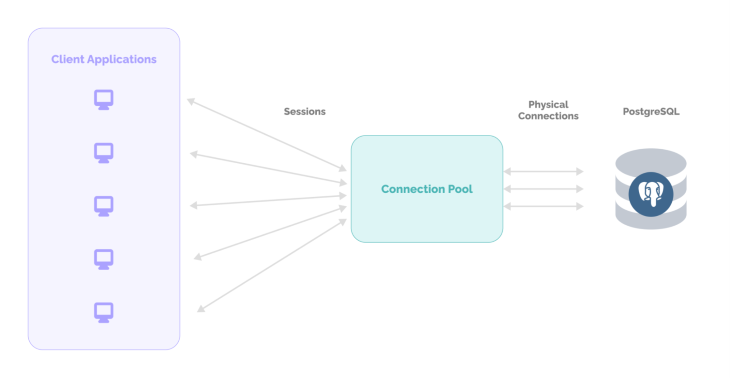
Connection pooling is the method of creating a pool of connections and caching those connections so that they can be reused again. It was one of the most common methods of handling database connections prior to query requests.
We generally think a database connection is fast, but this is not the case when we need to connect to a large number of clients. It takes up to 35–50ms to connect, but only 1–2ms if we are connecting via a connection pooling method. By connection pooling, we pre-allocate database connections and recycle them when new clients connect.
There are a few major types of connection pooling: framework connection pooling, standalone connection pooling, and persistent connection. However, persistent connection pooling is really just a workaround that acts as a connection pooling strategy.
Framework connection pooling occurs at an application level. When we want our server script to start, a pool of connections is established to handle query requests that will be arriving later. However, this can be limited by the number of connections, as it may encounter significant memory usage.
When we allocate an overhead memory between 5–10MB to cater to the request query, we call it standalone connection pooling. It’s configured with respect to Postgres sessions, statements, and transactions, and the main benefit of using this method is the minimal overhead cost of about 2KB for each connection.
This type of connection pooling makes the initial connection active from the time it is initialized. It provides a decent continuous connection but doesn’t fully hold the connection pooling feature.
It is most helpful for a small set of clients whose connection overhead may generally range between 25–50ms. The drawback of this approach is that it’s limited to a number of database connections, usually with a single connection per entry to the server.
Until this point, we have created a new database locally and named it employeedb. But we don’t have any data inside of it. Let’s write a simple query to create a table of employees:
CREATE TABLE IF NOT EXISTS employees( id SERIAL PRIMARY KEY, name VARCHAR(100) UNIQUE NOT NULL, designation VARCHAR(200), created_on TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP );
We also need to add data to the table we created:
INSERT INTO employees (name, designation)
VALUES
('Ishan Manandhar', 'Designer and Developer'),
('Jane Doe', 'JamStack Developer'),
('Alfred Marshall', 'Content Writer'),
('John Doe', 'Product Designer'),
('Dave Howard', 'Security Analyst');
SELECT * FROM employees;
Now, we can create a new directory inside our Next project and call it employeeold:
../src/pages/api/employeeold
// creating a new connection and closing connection for each request
import type { NextApiRequest, NextApiResponse } from 'next';
import { Client } from "pg";
const employeeOld = async (req: NextApiRequest, res: NextApiResponse) => {
const client = new Client({
host: "localhost",
user: "postgres",
password: "postgres",
database: "employeedb",
port: 5432,
});
client.connect();
const { method } = req;
if (method === 'GET') {
try {
const query = await client.query('SELECT * FROM employees');
res.status(200).json(query.rows);
client.end();
return
}
catch (err: any) {
res.status(404).json({ message: 'Error: ' + err.message });
}
}
else {
res.status(404).json({ message: 'Method Not Allowed' });
}
client.end();
}
export default employeeOld;
Here, we created a new endpoint that can query all the lists of employees inside our database. We implemented a normal query request way to establish a connection to our database without the use of pooling.
We used pg-pool to create a new connection that’s made every time we hit this API. We also close the connection we opened every time a client requests the data.
Below are the steps that are involved when a connection occurs:
A web application that connects to a database each time a user requests data would take milliseconds in lag response. But when we are making an enormous request, it can take much longer, especially if these requests are sent simultaneously. This connection consumes resources from the server, which can result in database server overload.
The best practice would be to create a fixed number of database connections in advance and reuse them for different tasks. When there are more tasks than the number of connections, they should be blocked until there is a free connection. This is where connection pooling kicks in.
Note: This may not be an ideal case of connection pooling. You can instead fetch this data as getStaticProps in our next app, but in this article, we just want to demonstrate connection pooling using Next.js.
The node-postgres library is shipped with built-in connection pooling via the pg-pool module. During the creation of the new pool, we need to pass in an optional config object. This is passed to the pool (and passed to every client instance within the pool) when the pool creates the client.
We will go through each field that is passed into the config object. You can find the documentation here.
connectionTimeoutMillis: the number of milliseconds to wait before timing out when a connection to a new client is made. By default, the timeout is set to 0max: the maximum number of clients the pool should contain, which is set to 10 by defaultidleTimeOutMillis: this refers to the millisecond of time the client needs to sit idle in the pool. This won’t get checked out before it’s disconnected from the backend and disregarded. The default time set is 10, but we can set it to 0 to disable the auto-disconnection of idle clientsallowExitOnIdle: a boolean property that, when set to true, will allow the node event loop to exit as soon as all the clients in the pool are idle, even if their socket is still opened. This comes in handy when we don’t want to wait for our clients to go idle before our process exitsLet’s create a new file and name it employeenew inside the api folder, which comes with our next pre-configured setup folder, ./src/pages/api/employeenew:
import type { NextApiRequest, NextApiResponse } from 'next';
import { Pool } from "pg";
let connection: any;
if (!connection) {
connection = new Pool({
host: "localhost",
user: "postgres",
password: "postgres",
database: "employeedb",
port: 5432,
max: 20,
connectionTimeoutMillis: 0,
idleTimeoutMillis: 0,
allowExitOnIdle: true
});
}
const employeeNew = async (req: NextApiRequest, res: NextApiResponse) => {
const { method } = req;
if (method === 'GET') {
try {
const query = await connection.query('SELECT * FROM employees');
return res.status(200).json(query.rows);
}
catch (err: any) {
res.status(404).json({ message: 'Error: ' + err.message });
}
}
else {
res.status(404).json({ message: 'Method Not Allowed' });
}
}
export default employeeNew;
Here, we created a new endpoint that can query all the lists of employees inside our database and implemented a connection pooling mechanism. We have opened up 20 connections beforehand so that we can avoid the time lag issue with the connection opening and closing.
We have implemented two connection mechanisms to connect our Postgres database. We implemented standalone pooling for our demo purpose, where we allocated some maximum connections, freed up listening to the incoming requests, and pre-allocated connections. When we are creating a connection pooling class, we should meet the following factors for increased database performance:
Note: we might not see a significant difference in performance until we create large concurrent requests at once.
To test this inside of the browser, we will open up our developer tools and add this line of code:
for (let i = 0; i < 2000; i++) fetch(`http://localhost:3000/api/employeesOld`).then(a=>a.json()).then(console.log).catch(console.error);
We also need to test our connection performance with another route as well.
for (let i = 0; i < 2000; i++) fetch(`http://localhost:3000/api/employeesNew`).then(a=>a.json()).then(console.log).catch(console.error);
Here’s a snapshot showing the performance comparison of both these approaches.
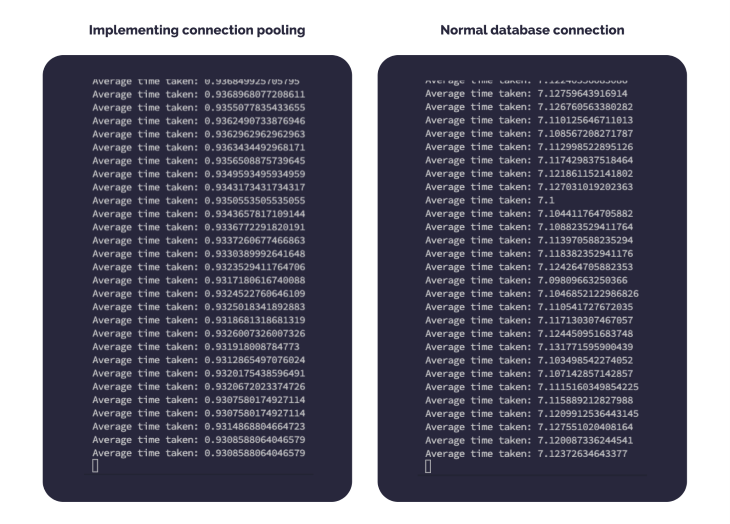
There are many benefits to using connection pooling, especially when establishing a complex connection. For example, the connection to a new client might take 20-30 milliseconds, where passwords are negotiated, SSL may be established, and configuration information is shared with the client and server, all of which can substantially slow down our application performance.
You should also keep in mind that PostgreSQL can only handle one query at a time on a single connected client in a first-in, first-out manner. If we have a multi-tenant application that is using a single connected client, all queries from all simultaneous requests will be in a queue and executed one by one serially, which can drastically slow down performance.
Finally, depending on available memory, PostgreSQL can handle only a limited number of clients at a time. Our PostgreSQL may even crash if we connect an unbounded number of clients.
Connection pooling can be extremely useful if our database:
Opening our database connection is an expensive operation. In the modern web applications we build, we tend to open many connections, which can lead to a waste of resources and memory.
Connection pooling is an essential feature that ensures closed connections are not really closed but instead, returned to a pool, and that opening a new connection returns the same physical connection back, reducing the forking task on the database.
With the help of connection pooling, we can reduce the number of processes a database has to handle in a given amount of time. This can free up the resources required for connecting to our database and improve the speed of connectivity to the database.
Find the code implementation of connection pooling here. Happy coding!
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

Learn how inline props break React.memo, trigger unnecessary re-renders, and hurt React performance — plus how to fix them.

This article showcases a curated list of open source mobile applications for Flutter that will make your development learning journey faster.

Discover what’s new in The Replay, LogRocket’s newsletter for dev and engineering leaders, in the April 1st issue.

This post walks through a complete six-step image optimization strategy for React apps, demonstrating how the right combination of compression, CDN delivery, modern formats, and caching can slash LCP from 8.8 seconds to just 1.22 seconds.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

