Caching is a way to serve content faster. Caching happens at different levels in a web application:

CDN is used to cache static assets in geographically distributed servers. It sends the assets faster to the end user from the cache.
Database caching is the caching natively used by every database. Every database has smart algorithms to optimize reads and writes. This caching depends primarily on the structure of the database. You can optimize your database caching by tweaking the schema.
Indexing in a database is one way of optimizing database reads. The database also has a working set of data in-memory to handle frequent requests to the same data.
Server caching is the custom caching of data in a server application. Usually this caching heavily depends on the business need. Highly optional for small applications that don’t have enough concurrent users.
Browsers cache the static assets based on the cache expiry headers. Also, browsers cache the GET requests smartly to avoid unnecessary data calls.
In this article, we will see different caching strategies that happen in the API (i.e., server level caching).
When you are creating an API, you want to keep it simple. But, once the concurrent requests increase, you’ll face a few issues.
In most cases, horizontal scaling will work fine to resolve these issues. Horizontal scaling adds more resources and machine power to handle traffic. However, you will eventually reach a point where your database can’t handle the requests irrespective of the traffic.
On an API level, there are many optimizations you can do to solve such issues. Some of the solutions include paginating data fetches from the database, caching read data that are the same for many users or visitors, and database sharding.
You use caching when you have a highly concurrent need to read the same data, or for any application that has heavy read and write. You can also use caching for frequently accessed information.
For example, caching is useful for COVID APIs.
Lot of users around the world are reading about this topic, but its write frequency is not very high. Therefore, you can simply cache the response in memory and serve it very fast. Once there is new data, write it to the database, invalidate the cache, and update it asynchronously.
Caching is also useful for user meta information. When you’ve logged in to any site, the user data will be required on every page.
You don’t need to request it again and again — rather, you can keep that information in a cache to serve faster. When the information gets updated, update the cache as well. Server session is one type of user meta information.
It can also be helpful to cache live scorecards. Online scorecards are live data accessed by millions of users when any sports match is live.
You don’t need to fetch data from the database all the time to serve live scorecard information — you can simply cache the data for a few seconds to serve millions of the same requests and then recache with live data again in a set time interval.
Using this method, your database will be hit by only one user every second as opposed to millions of users directly.
In most cases, the cache lives in-memory. This is the reason it’s faster to fetch data from the cache rather than the database. Even databases cache their working set in-memory.
But those are not custom caches defined by the business requirement. Those caching mechanisms are based on database internal operations.
Let’s learn some of the caching strategies with real-world use cases.
The lifecycle of caches play a major role. Invalidating a cache is one of the most difficult computer science problems.
We’re going to talk about cache with time to live (TTL) and cache without TTL.
Cache with TTL
A cache with TTL is the most commonly used cache. When your data is frequently updated and you want to expire your cache in regular intervals, you can use cache with a time limit. The cache will get deleted automatically once the time interval has passed.
Server sessions and live sports scores are examples of caches with TTL.
Cache without TTL
A cache without TTL is used for caching needs that don’t need to be updated frequently.
Course content in course websites and heavy static content sites like multi-author blogs often use caches without TTL.
Real world example for cache without TTL are,
Content will be published and updated infrequently, so it’s easier to cache it. Cache invalidation is easy too.
There are several strategies in caching. Some of them include cache aside (or lazy loading), read through cache, and write through cache.
Cache aside keeps the cache updated through the application asynchronously.
First, the application checks to see whether data exists in the cache. If it exists, you can read from cache. If it doesn’t, you read from the data source.
Then, it will write to the cache and return the data as the response. The subsequent requests will be served through the cache.
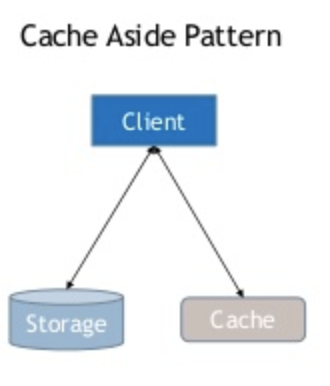
Cache aside is very easy to implement but very difficult to manage. Cache invalidation is difficult. Whenever the data in the source is updated, we need to check the cache and invalidate it. It will be difficult and expensive if you use multiple sources to update the data in the store.
Pseudocode: Cache aside for COVID API:
app.get('/summary', async (req, res) => {
// Check the cache
if (cache.has('summary')) {
const data = await cache.get('summary');
return res.json({ data });
}
// If no cache, then get data from datastore
const data = await getSummary();
// Set the cache for future request
await cache.set('summary', data);
// Send the response
return res.json({ data });
});
For read through cache, the data will be read through the cache every time.
First, check whether data exists in the cache. If it does, read from the cache and send the response. If it doesn’t, the cache will be updated from the datasource. Cache will then send the response back to the client.
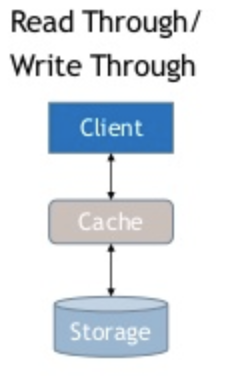
Read through cache has the same problem as cache aside — if the datastore gets updated through many sources, the cache will be obsolete.
Cache aside and read through cache are mostly used on heavy read sites. The cache invalidation issue can be solved using write through cache.
Pseudocode: Read through cache for COVID API:
app.get('/summary', async (req, res) => {
// If no cache exist
if (!cache.has('summary')) {
await getSummaryFromStoreAndSetCache();
}
const data = await cache.get('summary'); // Always exist at this point
// Send the response
return res.json({ data });
});
Read through cache is similar to cache aside, the only difference being that it always sends the result from the cache.
The data will first be written to the cache and then the cache will update the datastore.
First, write to the cache and then to the main database.
Write through cache only solves the write issue. It needs to be combined with read through cache to achieve proper results.
When both are combined, the data always gets read from cache and written to the database through the cache, so there won’t be any obsolete data in the cache.
However, this will make the resources expensive very easily if you want to keep everything in the cache. There are cloud databases that support read through and write through caches natively without writing custom cache layers.
Pseudocode: Write through cache for COVID API:
// Sample creation endpoint
app.post('/summary', async (req, res) => {
const { payload } = req.body;
// Create cache first
await cache.set('summary', payload);
// Send the response
return res.json({ success: 'Content updated successfully' });
});
// Sample updation endpoint
app.put('/summary', async (req, res) => {
const { payload } = req.body;
// Get previous cache and update payload
const previousCache = await cache.get('summary') || [];
const data = [...previousCache, payload];
// Update or overwite cache first
await cache.set('summary', data);
// Send the response
return res.json({ success: 'Content modified successfully' });
});
Cache will send the response before writing to the datastore. It writes to the datastore asynchronously depending on the load.
It is just a special type of write through cache. It doesn’t wait for the datastore to acknowledge whether data is stored.
This technique is used in every NoSQL and SQL database internally. First, the data will be written in memory. The database acknowledges the response and writes it to the disk asynchronously. This way, the database can smartly handle heavy writes.
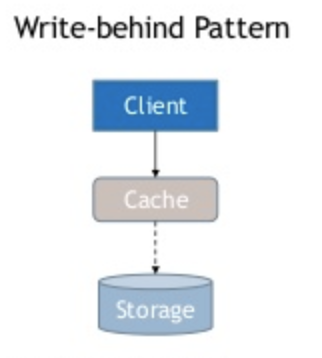
Again, this strategy alone won’t be sufficient. It should be coupled with read through cache to solve cache invalidation issues. Most relational database have write behind and read through cache supported natively.
Refresh ahead cache is used to refresh the data before it expires. It happens asynchronously so the end user won’t see any issues.
This kind of cache is used heavily on real-time websites, such as live sports scoring sites and stock market financial dashboards. You can always read from cache. The cache will refresh with live data before it expires.
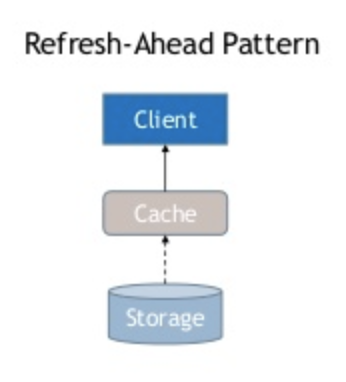
There are two problems everyone faces in caching: when to invalidate the cache and how to name the key for the cache.
For simple and straightforward caches, you can name it easily with a static string key. If you have to cache paginated data, you can use a key that contains the page number and limits information.
Example: tweets:${pageNumber}:${limit}
You can choose your own delimiter. This works if you already know the filtering information. If you have many more filters, then it becomes hard to handle the dynamic key.
Choosing a key is a hard problem once your cache is very deep and has many levels of variables. It is always a good idea to keep the cache data and the key simple enough to retrieve and load easily and faster to the end user.
Twitter is a complex and large-scale distributed app. It’s not easy to consider every use case.
Let’s consider a simple Twitter app with hundreds of users.
How do you serve the users as fast as you can through a reliable caching mechanism?
There are many levels of cache you can build.
One option is to cache with TTL for user-based views. The expiry duration will be short enough under a minute. This way, you can show the same paginated results to the minute to the user for consequent refreshes.
You can also cache infrequent hashtags. Keep the cache in a paginated set and update the last set based on new tweets for those hashtags.
Caching trending hashtag-based tweets is costly since a lot of real-time users are tweeting about it.
You can do the same approach as caching with TTL for the first few pages.
Caching a single tweet and its related threads is easy. An even simpler caching strategy like cache aside will work easily. Since the order of threads aren’t very important, you can invalidate and recache when new threads start coming in.
Caching is a vast topic. We scratched the surface with a few strategies.
Most applications don’t require custom caching solutions since databases and servers themselves handle requests smartly through their in-built caching mechanism.
Once the scale reaches certain levels, caching is the first solution to reach for. It improves the end user experience and helps to avoid unnecessary resource costs.
Hope you learned few strategies to implement on your web app!
Debugging code is always a tedious task. But the more you understand your errors, the easier it is to fix them.
LogRocket allows you to understand these errors in new and unique ways. Our frontend monitoring solution tracks user engagement with your JavaScript frontends to give you the ability to see exactly what the user did that led to an error.
LogRocket records console logs, page load times, stack traces, slow network requests/responses with headers + bodies, browser metadata, and custom logs. Understanding the impact of your JavaScript code will never be easier!
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now
This article explores several proven patterns for writing safer, cleaner, and more readable code in React and TypeScript.

A breakdown of the wrapper and container CSS classes, how they’re used in real-world code, and when it makes sense to use one over the other.

This guide walks you through creating a web UI for an AI agent that browses, clicks, and extracts info from websites powered by Stagehand and Gemini.

This guide explores how to use Anthropic’s Claude 4 models, including Opus 4 and Sonnet 4, to build AI-powered applications.

6 Replies to "Caching strategies to speed up your API"
very good article
Good one
Very good overview of the different strategies and their pros and cons. Great place to start my learning
For caching solution u can try litespeed webserver
How cache aside and cache through are different?
In your example you (the application) talked to both cache and database. I think in cache through strategy the application/client should not be aware of database existence at all.
Very needful info for optimization 👍