There is a growing demand for Large Language Models (LLMS) that can work offline and locally on someone’s machine. This allows for a workflow that is cost-efficient, reliable, and private. Platforms like Ollama can simplify the process by making it easy to download open source models directly onto your hardware. Developers are then able to run models like Llama 3, Gemma 3, and DeepSeek R1 without depending on external API calls, which can be costly and time-consuming. The largest benefit of the process running on a local machine is the ability to access secure AI integration.

In this article, we will explore the benefits of using local LLMs beyond the simple, reactive chatbots with which we’re all familiar. We’ll also cover what it’s like to work with AI agents, which are systems capable of autonomous planning, tool utilization, and more complex goals. We’ll demonstrate these agents through an agentic AI workflow, learning how to integrate local models served via Ollama with a React frontend.
Artificial intelligence has gone through many eras, each one offering significant improvements and creating more powerful and complex systems. Rule-based systems, often called expert systems, dominated during the early days of AI, with humans manually encoding information in IF-THEN rules and statements. This was effective for well-defined problems in smaller use cases, but these types of systems were not very intuitive, difficult to scale, and couldn’t handle challenging problems or learn from more data.
The second major leap came with machine learning and neural networks, especially deep learning. These tools were capable of learning and creating patterns directly from large data instead of explicit rules. This transition made breakthroughs possible in image recognition, speech processing, and eventually led to present-day LLMs.
LLMs are typically based on transformer models and can demonstrate a new ability to understand, generate, and process human language, enabling applications like advanced chatbots, content generation systems, and complex question-answering systems.
There are even more powerful LLMs that can operate reactively, which means that they receive an input (prompt) and produce an output. This led to the creation of AI systems that can proactively solve complex, multi-step problems, as well as the emergence of agentic AI systems.
An agentic workflow usually means a staged set of steps, possibly incorporating multiple LLM calls, tools, or data processing steps, staged to produce a specific output. You can think of it like a predefined recipe where AI elements execute given tasks.
The majority of physical robots in the real world depend on pre-coded instructions or rule-based systems, which limit their autonomy. Even though they are able to perform workflows, which are typically a simple collection of operations, they usually lack the capabilities to reason or adapt. An AI agent, however, is defined by its ability to reason, plan, and act autonomously towards the achievement of a higher-order goal. Agentic workflows are not the same as traditional ones because the agent can dynamically change its strategy in response to feedback, environmental shifts, or new information, as opposed to sticking to a predefined script.
For example, a traditional warehouse robot would travel along a set path to collect and drop off goods, and if it finds an obstruction, it stops and waits for a human to intervene. An AI agent in the same setting, however, might redo its path, reorder its activities based on delivery priority, or even collaborate with other agents to streamline the entire process. It is this ability to change and make independent choices that defines agentic behavior.
The creation of agentic AI systems is a huge milestone toward more capable and independent AI. With reasoning and language capabilities of modern LLMs, these systems are supposed to be capable of performing tasks that require planning, working with external tools (like APIs or databases), and are able to retain context across deep and long interactions. They do not just react to questions and prompts; these types of agents can actively pursue goals.
For an AI agent to function effectively, it usually relies on several important components
These are the core principles for building sophisticated agentic workflows, and we will explore them in the following sections using Ollama and React.
When it comes to developing agentic AI workflows, having the ability to use local models with tools like Ollama can offer significant advantages over using cloud-based solutions.
One advantage is enhanced data privacy. When processing sensitive or proprietary information on local hardware, the data never leaves the controlled environment, meaning it is always secure. This reduces the likelihood that the data can be manipulated or lost, which can be the case when working with external factors.
In addition to privacy, local models have economic and practical benefits. Local model usage can lead to significantly reduced long-term operational costs, especially for high-frequency or high-volume usage, as you avoid having to set up recurring subscription fees for cloud-based APIS.
Local models also allow for better offline capabilities, meaning that agentic workflows can run continuously in offline setups without an internet connection. In the process, they ensure uninterrupted functionality and enhance the number of deployment scenarios for your AI applications, making them more robust and less reliant on network connections.
Performance issues can also be improved when working with local models. This is because when you eliminate the need to transmit data to and from distant servers, local processing drastically reduces latency, which results in quicker response times essential for interactive or real-time agentic work. Even though Cloud infrastructure can be reliable, when you have immediate access and control over the local environment, it allows for better performance optimization.
Privacy, cost advantages, offline support, and performance optimization are powerful reasons for including local models in an agentic AI development workflow.
Ollama is a strong, open source tool that has been designed to simplify running large language models on a machine. Ollama packages models, their weights, configurations, and dependencies into a single package that’s easily distributable. It’s a streamlined process for running various LLMS without the pain of dependencies and frameworks.
Ollama has both a command-line interface (CLI) and an API, so it is easily accessible for direct use and programmatic integration into applications. Its primary function is to serve these models so that you can query them through a simple interface.
Ollama has an increasing list of available models that you can easily download and run. These range from very popular open source models with a variety of sizes and capabilities, such as Llama 3, Mistral, Gemma, and more. Their capabilities vary, with some leaning towards general text generation and conversation, and some being better for highly specialized use cases like code generation, summarization, or even multimodal input processing (e.g., text and images).
The features are dependent on the model that you choose, and in Ollama, you can experiment with different models to choose the best option for your project. You can get a list of the models available and their parameters from either the Ollama GitHub repository or the Ollama model search page.
First, download the Ollama installer application. Go to the Ollama website and download the installer for your operating system as shown here:
On the next screen, we can choose our operating system before downloading the application. Once you download the application, install it on your machine. When Ollama has been installed, it will run as a background service on your machine. The main way to interact with it is through the command line.
When your application is up and running, go to the Ollama search page to find a model to download. Each model can come in different variants (e.g., q4KM, q6_K, f16, etc.), which affect both size and performance. Generally, larger files mean more parameters and better performance, but take up more disk space and memory. Smaller ones are distributed compressed to save space and run faster on lower-end hardware, but sometimes at the cost of accuracy or functionality.
Model files tend to be approximately 1 GB to 50 GB, depending on the model and quantization. Ideally, you will need significant disk space and a reasonably fast machine with plenty of RAM (8 GB minimum, 16 GB+ preferable) for comfortably running large models.
The following commands will download the LLM onto your machine:
# Example syntax to pull a model ollama pull <model_name> # Pulling llama3.2 ollama pull llama3.2
If you want to view the LLMS you have downloaded, you can run this command to list them:
ollama list
You can learn all of the commands by visiting the official Ollama repo on GitHub.
The final step is running the model via the command line. Each model has instructions on its page for how to run the model. For example, we can use the following command to run llama3.2 on our machine:
ollama run llama3.2
After running the LLM, you will see the familiar chat prompt where you can talk to the LLM much like the chat prompts we are familiar with, like ChatGPT, Claude, etc.
And that’s it! Now you can safely and privately run LLMS locally on your machine for free.
Our travel planning app is being developed with two interfaces: Gradio and React. Both are designed to share nearly identical core functionality.
Gradio is an open source Python library perfect for rapidly developing interactive web demos of machine learning models. It’s convenient for quickly exposing and iterating on our Ollama-driven agent’s core logic. Gradio’s biggest strengths are its ease and speed for prototyping AI capability with minimal code, which is extremely valuable when testing interactions and visualizing the flow. However, that ease of use means that we have less control and fewer customization options with Gradio, which is important when building a user interface.
Gradio is very popular in the AI field, so it is worth learning but if we wanted to have more advanced interactive capabilities, precise control over the user experience, and seamless integration with more complex web application features, it would be ideal to use a JavaScript framework or an alternative library more suited for a production application.
React, on the other hand, unlocks the ability to create a genuinely professional, scalable, and maintainable application. As a leading JavaScript library, React offers much better ease of use when building complex, dynamic user interfaces with sophisticated interactions that can provide an enhanced user experience. The fact that React frontends interact with your backend and, in this case, handle the Ollama calls and agent rules using conventional API calls is especially useful.
This UI decoupling from the internal AI backend is important for creating solid applications that can scale with ease, integrate with other services, become maintainable, and provide a professional-level user interface — something that Gradio doesn’t offer, as it’s built more for demoing features.
You can find the source code for this project here. All you need to do is set it up on your local machine to get it running.
The technical stack is as follows:
This application uses Ollama to run models locally on your machine. Make sure that you have Ollama installed and running and that you have downloaded at least one LLM, which we did in the previous section.
Now, follow the steps below to set up the project:
Run the following command in your terminal and clone this Git repository somewhere on your local machine:
git clone https://github.com/andrewbaisden/travel-planner-ai-agent-app.git cd travel-planner-ai-agent-app
You should now have an identical copy of this repo on your machine.
Next, we need to set up our Python and FastAPI backend. In the root directory of the travel-planner-ai-agent-app folder, run the following commands:
Depending on your setup, you might need to use either the
pythonorpython3command.
# Create a Python virtual environment python3 -m venv venv source venv/bin/activate # On Windows, use: venv\Scripts\activate # Install Python dependencies pip3 install -r requirements.txt # Change into the backend folder cd backend # Start the FastAPI servers python3 api.py # Run the FastAPI API server python3 app.py # Run the Gradio frontend
These commands create a Python virtual environment, install the Python dependencies, and get our backend servers running. We have a FastAPI server that has the endpoints for our frontend to use. We also have a Gradio interface for connecting to our backend, which is good for demos.
Finally, let’s get our React frontend up and running. Run these commands to complete the setup process:
# Navigate to the frontend directory cd frontend # Install dependencies npm install # Start the development server npm run dev
Our application should be fully working!
Below are the key endpoints and interfaces for interacting with the backend:
This launches a local web interface to interact with the Travel Planner AI agent.
This is what our Gradio interface looks like in simple mode:
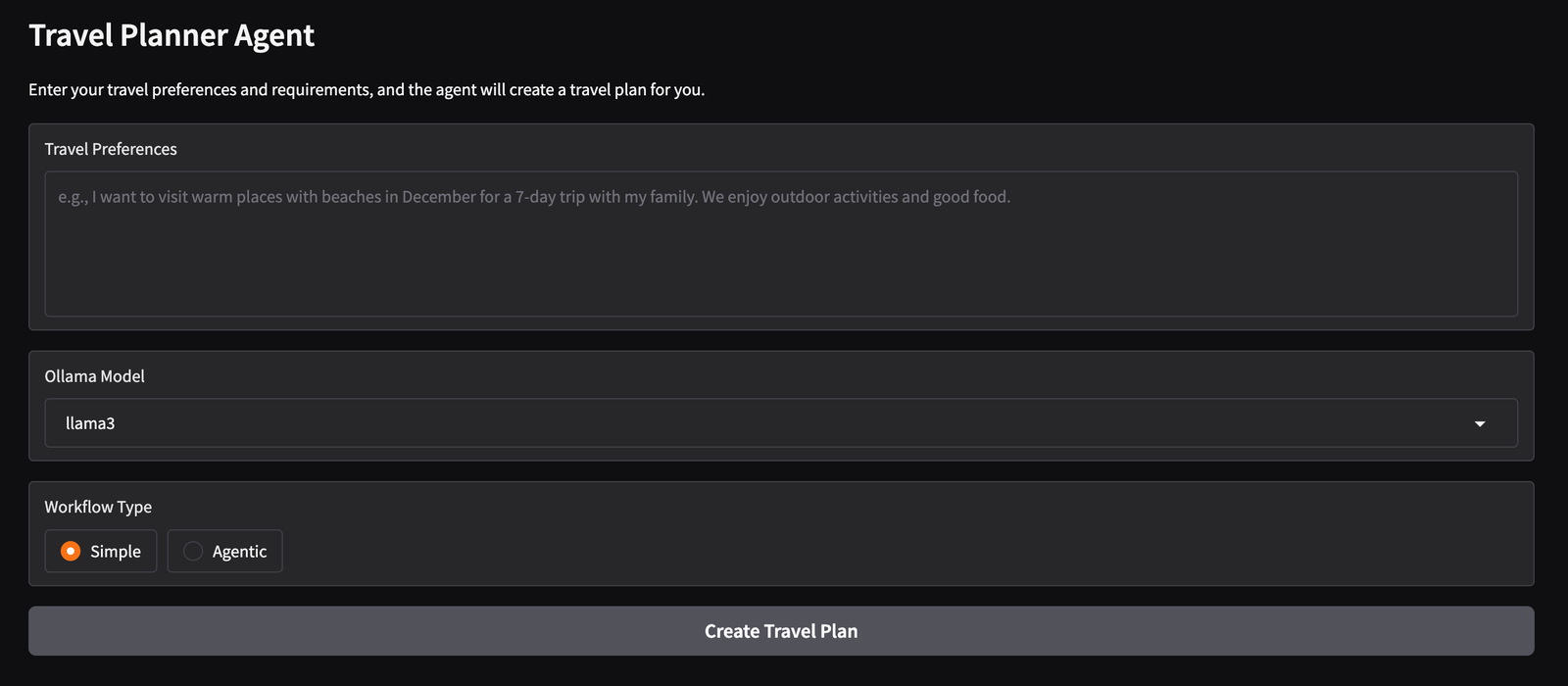
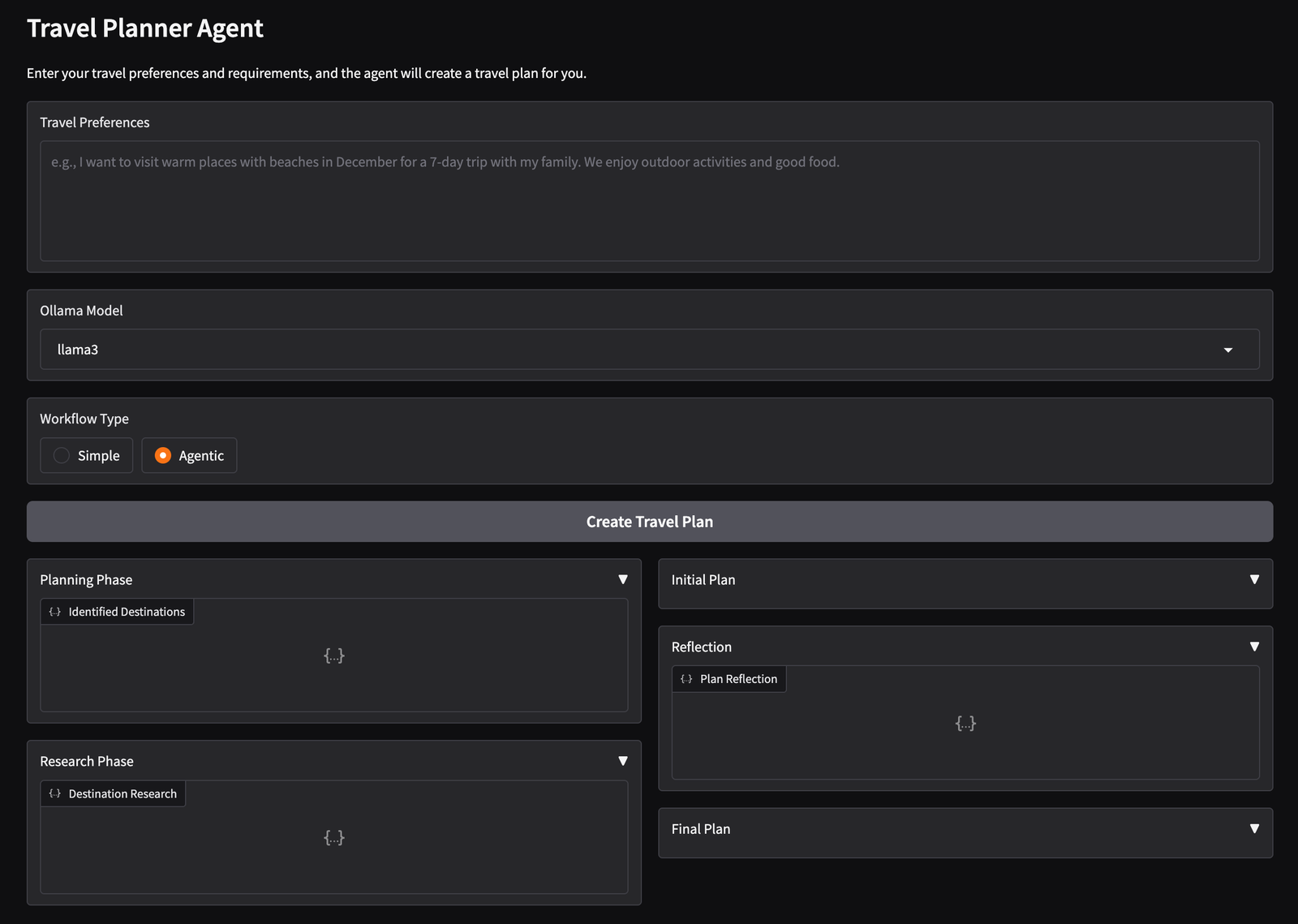
This is what our Gradio interface looks like in agentic mode:
Below is the main URL for accessing the frontend application:
This opens the user-facing web interface for interacting with the Travel Planner agent. Our React application looks like the following in simple mode:
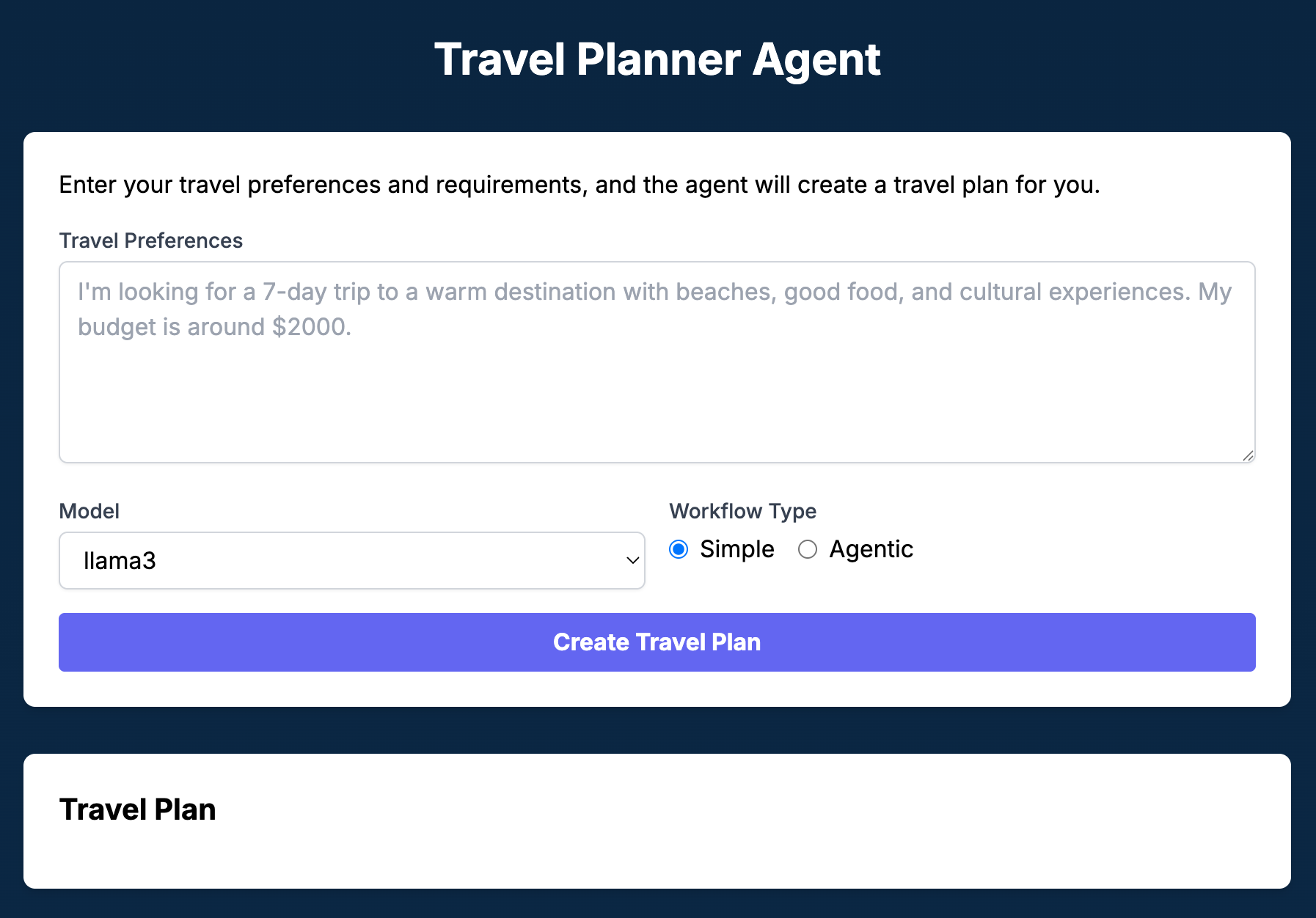
This is what our React app looks like in agentic mode:
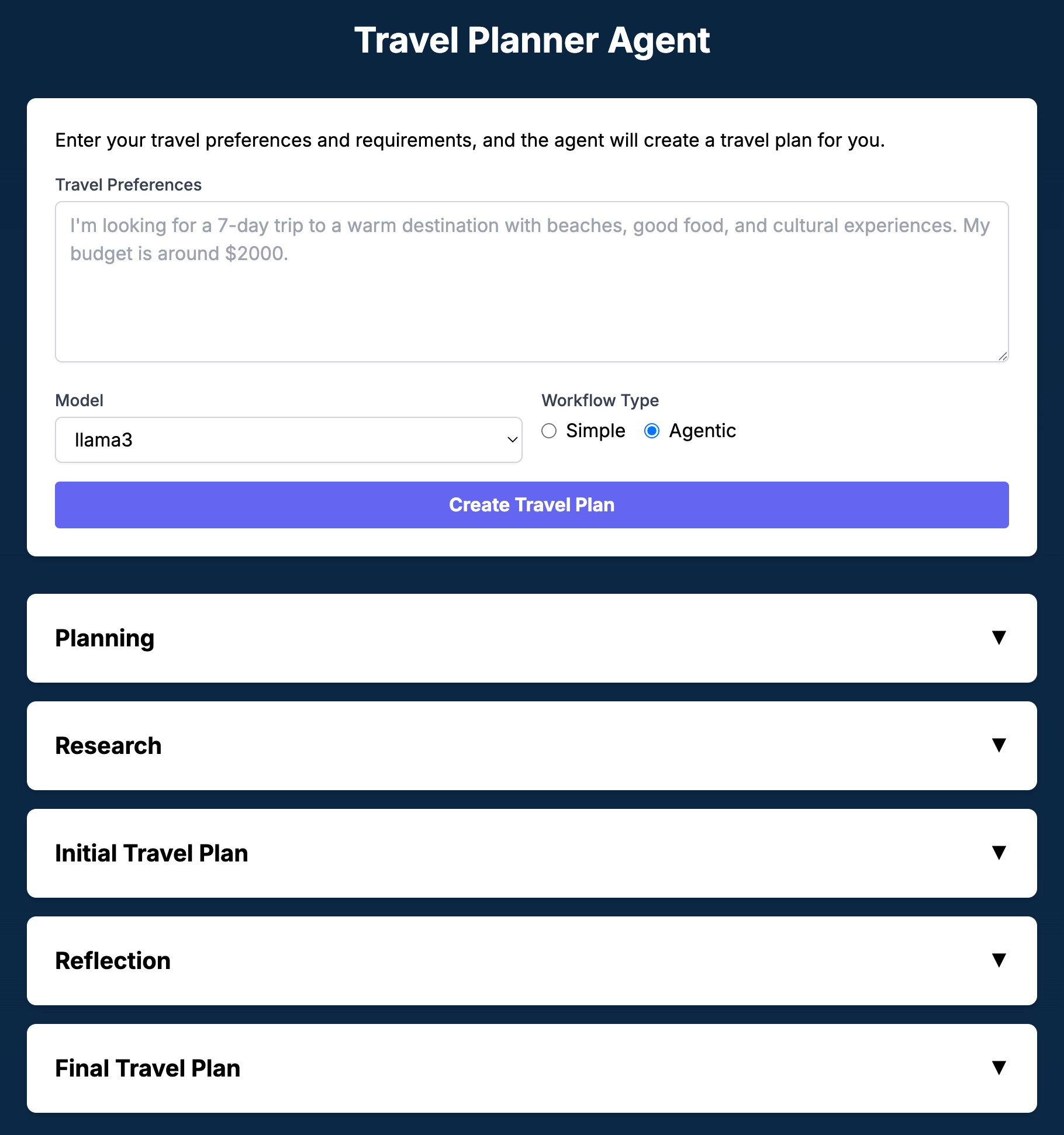
In theory, this application can work with various vendors’ LLMS. However, I find it performs best with the Llama models (e.g., Llama 3.1, Llama 3.2).
Generating a travel plan locally can be a bit slow, depending on your machine’s performance. That’s because you’re running these LLMS directly on your machine, not through cloud-based services. Unlike online LLM platforms, which run on powerful servers built to handle thousands of requests at once, your local setup is limited by your device’s hardware.
On my M1 MacBook Pro, the simple workflow generated a plan in about one to two minutes, while the agentic workflow took over three minutes to achieve the same result. Of course, this is just a demo app and not meant for production, so these times are acceptable for experimentation.
There are many platforms available for creating AI agents. Let’s review some of the popular options and what they have to offer:
Developed by Microsoft, Semantic Kernel is an open source SDK that is used to embed large language models (LLMS) inside mainstream programming languages. It is intended to manage AI workflows and bring AI capabilities into mainstream apps with an emphasis on enterprise applications and multi-language support (primarily C#, Python, and Java).
This architecture is designed to connect LLMS with external datasets, enabling the creation of AI agents that are capable of accessing, consuming, and reasoning about private or domain-specific data. LlamaIndex is good at knowledge-intensive applications and offers data indexing, retrieval functionality, and support for various data storage solutions.
Designed as an extension to the LangChain ecosystem, LangGraph provides a graph-based method for building stateful, multi-actor applications with LLMS. It is well-suited to creating complex, dynamic workflows that require cycles and the capacity to remember conversational state, and allows for much better control over agent conversation direction.
Basing itself on experimental OpenAI Swarm, this SDK offers a more standard toolkit for developing reasoning, planning, and externally calling functions or API-calling agents. It offers primitives for agent specification, task transfer between agents, and safety features to enable multi-step or multi-agent processes to be simpler, especially within OpenAI.
An open source platform primarily focused on building conversational AI agents or chatbots. Rasa provides features for natural language understanding, conversation management, and integration with other messaging platforms to enable developers to create interactive and context-aware AI assistants.
The Hugging Face platform uses the popular Hugging Face Transformers library to enable the creation of agents that can use tools and perform complex tasks by interacting with models on the Hugging Face Hub or elsewhere. It provides a general-purpose solution to create agents with access to lots of pre-trained models and community-contributed tools.
A low-code, open source platform that allows users to visually develop and deploy LLM apps, like AI agents, from a drag-and-drop interface. It supports integration with various data sources, LLMS, and tools, so it would be good for users who prefer a graphical IDE.
While a general-purpose workflow automation platform, n8n has the ability to embed AI agents into automations. Its graphical workflow designer offers the capability to connect applications and services, including AI models, to build complex automations that can use agent-like functionality.
Below are some other tools to consider:
Building an agentic AI workflow can give us valuable insights into how large language models are used for developing intelligent, task-specific systems. One of the biggest advantages they offer is being able to use local models with the help of tools like Ollama, which addresses the main concerns when using these LLMS online, including data privacy, cost saving, offline access, and performance optimization. Combining this local AI functionality with a React frontend allows for robust, user-friendly applications.
The development of tools like Ollama and more efficient open source models demonstrates the growing importance of local models in the future of AI. They are essential for creating more private and manageable AI, making their powerful abilities more accessible to users and their data. Building with local models is a good investment for creating a world where we have a distributed, privacy-conscious world of AI.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

I migrated 20 production-style components from Tailwind to StyleX. Here’s what the data showed about LOC, CSS bundle size, build time, and type safety.

A guide for using JWT authentication to prevent basic security issues while understanding the shortcomings of JWTs.

Discover how to build, render, and automate product demo videos with Remotion, replacing traditional screen recordings with reusable React code.

Chrome’s Modern Web Guidance embeds modern web platform skills into AI coding agents, helping them choose native HTML, CSS, and browser APIs over legacy patterns.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

