GraphQL has recently enjoyed rapid adoption among various teams and companies. Schema plays a significant role in GraphQL servers, and it requires extra attention while constructing our database. In this post, we will be analyzing a few anti-patterns or common mistakes we may encounter while designing a schema, as well as possible solutions for them.

In a GraphQL schema, every field is nullable by default. There are many possible reasons why the data may be null, whether due to network errors, database connection issues, wrong arguments, etc. To combat these, all fields allow null values by default, and even if there are no values, the query won’t fail in the frontend.
This is one of the most prevalent anti-patterns, as the client expects data for a field or an error. But it receives null without an error and might break the frontend as a result.
Making such fields non-nullable helps us solve the issue. A field becomes non-nullable when an exclamation mark ! is added next to it in the schema design. Marking a field non-nullable is often based on the product requirements and, hence, has to be considered strictly when designing the schema.
# Nullable fields (Default)
type Passenger {
name: String
age: Int
address: String
}
# Non-nullable fields
type Passenger {
name: String!
age: Int!
address: String!
}
GraphQL has awesome self-generated documentation for our queries and mutations. Most of the time, these queries are self-explanatory and easily understandable by the frontend developers. However, at times, there can be confusion about the meanings of field names or types.
Documentation strings play a critical role here and help us add a description for fields/types and display them in the generated documentation. It supports both single-line and multi-line strings and enables clear communication about the schema.
Single-line strings are encapsulated between " marks while multi-line strings are encapsulated between """ marks. Let’s add some descriptions to the above example:
# A single line, type-level description
"Passenger details"
type Passenger {
""" a multi-line description
the id is general user id """
id: ID!
name: String!
age: Int!
address: String!
"single line description: it is passenger id"
passengerId: ID!
}
The docs look like this:
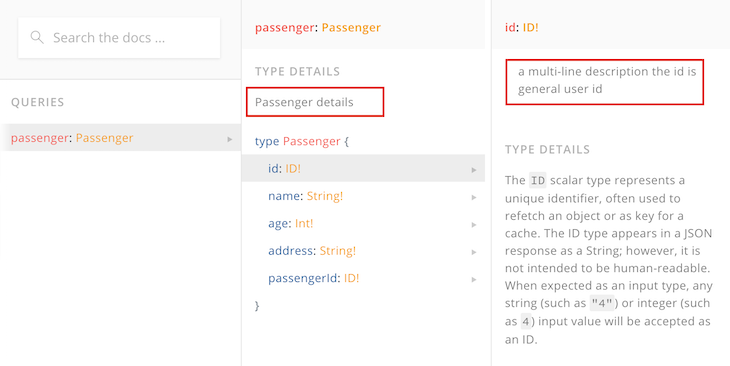
This now provides some clarity on the difference between id and passenger Id.
A mutation is the write/edit or delete operation in GraphQL and often requires a few arguments to process. Let’s consider the example of adding a new passenger. The type and mutation may look like:
type MutationResponse {
status: String!
}
type Mutation {
createPassenger(name: String!, age: String!, address: String!): MutationResponse
}
# Query in Frontend looks like:
mutation PassengerMutation($name: String!, $age: String!, $address: String! ) {
createPassenger(name: $name, age: $age, address: $address ) {
status
}
}
This approach is neither maintainable or readable. Adding one or more fields make the above mutation highly unreadable in the frontend. The solution to this problem is input objects.
Input objects pass all the arguments to a mutation as a single object, thereby making it more readable and easily maintainable. Let’s add an input object to the above mutation:
type MutationResponse {
status: String!
}
type PassengerData {
name: String!
age: String!
address: String!
}
type Mutation {
createPassenger(passenger: PassengerData!): MutationResponse
}
# Query in Frontend looks like:
mutation PassengerMutation($passenger: PassengerData! ) {
createPassenger(passenger: $passenger) {
status
}
}
Mutations are required for any data change in the GraphQL ecosystem. The beauty of a mutation is that we could send response data that can be consumed like a query in the frontend. Details about the mutation, like status, response code, error message, etc., are sent in a mutation response.
However, in a real-world application, there will be a need to update data on the frontend after every data change in the backend. Considering this scenario, after every successful mutation, we will have to manually fire another query to get the updated data in the frontend.
To avoid this issue, after every mutation, the affected/modified data can be sent as a response to the mutation itself. The frontend can make use of mutation response and update its local state, thereby avoiding an extra query. The mutation in the previous example falls under this anti-pattern. Solving it will result in a mutation as follows:
type MutationResponse {
status: String!
updatedPassenger: Passenger
}
type Passenger {
id: ID!
name: String!
age: String!
address: String!
}
type PassengerData {
name: String!
age: String!
address: String!
}
type Mutation {
createPassenger(passenger: PassengerData!): MutationResponse
}
# Query in Frontend looks like:
mutation PassengerMutation($passenger: PassengerData! ) {
createPassenger(passenger: $passenger) {
status
updatedPassenger
}
}
GraphQL supports only limited scalar types: Int, Float, String, Boolean and ID. Assuming they are self-explanatory, there are many scenarios in which we could allow invalid inputs/arguments in queries and mutations. This can be verified inside resolvers and an error can be thrown, but this is not an optimal approach.
Custom scalars and enums are useful solutions for this issue.
When the requirements don’t fit in the default scalar types, you can build a custom scalar type. This will invalidate the inputs at the validation state itself and is a highly scalable solution. One fine example of custom scalars is the Date type. Currently, the date has to be passed as a string in GraphQL. However, a custom Date type can be created using GraphQLScalarType.
From the official Apollo Docs:
# Schema implementation of custom Date type
scalar Date
type MyType {
created: Date
}
# Resolver / Logic implementation for the same
import { GraphQLScalarType } from 'graphql';
import { Kind } from 'graphql/language';
const resolverMap = {
Date: new GraphQLScalarType({
name: 'Date',
description: 'Date custom scalar type',
parseValue(value) {
return new Date(value); // value from the client
},
serialize(value) {
return value.getTime(); // value sent to the client
},
parseLiteral(ast) {
if (ast.kind === Kind.INT) {
return new Date(+ast.value) // ast value is always in string format
}
return null;
},
}),
};
An enum (enumeration) is a predefined set of values, and a field should contain one of those values to be a valid input. A nice use case could be a country name.
A country name will always be a string, and this enables the GraphQL server to accept any string value sent from the client. Using an enum, we can restrict the server to accept only a valid country name and throw an error in case of a random string.
Enums ensure data credibility and avoid redundancy across the application. Enums are also listed by default in the documentation. A sample implementation:
# Enum of allowed countries:
enum AllowedCountry {
Germany
USA
Sweden
Denmark
}
type Passenger {
name: String!
age: Int!
country: AllowedCountry!
#Country accepts only one of the values from the enum
}
A circular reference could present a potential anti-pattern depending on the scenario. Consider the following example:
type Passenger {
name: String!
location: Location!
}
type Location {
country: String!
passenger: Passenger!
}
This particular schema is in risk of getting exploited as it can be queried to infinite depth. Having nested queries can be an advantage in many scenarios but may turn fatal in a circular reference. An infinite nested query can even crash the server. A small example of such circular reference query can be seen below:
query getPassenger {
name
location {
country
passenger {
name
location {
country
passenger {
name
location {
country
}
}
}
}
}
}
The above query can reach an infinite level of depth. To avoid such scenarios, it is better to avoid circular reference while designing the schema. In case of exception where the circular reference can’t be avoided, a npm utility like graphql-depth-limit can prevent such nesting more than a specific depth.
A real-world application will have a huge amount of data. Considering the previous examples, if we query for the list of passengers from a travel portal, the results will have a few million records, if not billions. Consuming all these records in the client might crash the client. Thus, GraphQL supports pagination with limit and offset out of the box.
However, in the world of mistakes, a query can be fired without a limit value, resulting in fetching massive amounts of data from the server. This problem can be mitigated by assigning a default value for limit at the time of schema design. A sample implementation:
type Passenger {
name: String!
age: Int!
}
type Query {
# a limit of 10 makes sure, when a limit is not passed,
# it doesnt send more than 10 values
getAllPassenger(limit: Int = 10): [Passenger!]!
}
These are the few commonly occurring anti-patterns in GraphQL. In addition to the above, a few best practices can also turn into anti-patterns when not implemented in the right way. It’s always better to know the internals before implementing any tool to get the most use of it. Happy coding 🙂
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Discover how React Fiber works under the hood. Learn how React builds the DOM, handles concurrent rendering, and works alongside React 19 features and the new React Compiler.

Learn how to use Skybridge, an open-source React framework, to build and deploy cross-platform AI apps and interactive UI widgets for ChatGPT, Claude, and MCP clients from a single codebase.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

