Zod is the undisputed king of TypeScript validation. In a remarkably short time, it has become the gold standard, celebrated across the ecosystem for its phenomenal developer experience, elegant chainable API, and robust type inference. For countless developers, Zod is not just a library — it’s the default, instinctive choice for ensuring data integrity in their applications.

But what if the tool everyone reaches for first has a hidden cost?
A persistent debate roils under the surface of Zod’s popularity, centered on a series of startling performance benchmarks. These tests reveal that, for certain operations, Zod is orders of magnitude slower than its lesser-known competitors. This raises a crucial question: how can a tool that feels so right be, quantifiably, so slow? And more importantly, does it even matter?
This article will tackle that question head-on. We’ll explore the deep technical reason for Zod’s performance characteristics, moving beyond surface-level benchmarks to understand the architectural trade-offs at its core. Most importantly, we’ll reveal a powerful, production-proven technique to mitigate this slowness, allowing you to get top-tier performance without leaving the Zod ecosystem. The problem, as we’ll see, isn’t Zod itself — it’s how it’s typically used. And the fix is more accessible than you might think.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
To understand the Zod performance debate, we have to start with the data that sparked it. A comprehensive benchmark suite of TypeScript runtime validators presents a stark picture. In a “safe parsing” test — a common operation for validating and cleaning unknown inputs — the difference between Zod and its fastest competitors is not small.
While the high-performance library Typia clocks in at an astonishing ~76 million operations per second, the latest version of Zod (v4) performs around 6.7 million ops/sec. The older, widely used Zod v3 is even slower, at under 1 million ops/sec. We can compare these differences through bar charts, pulled from the Typescript Runtime Type Benchmarks website.
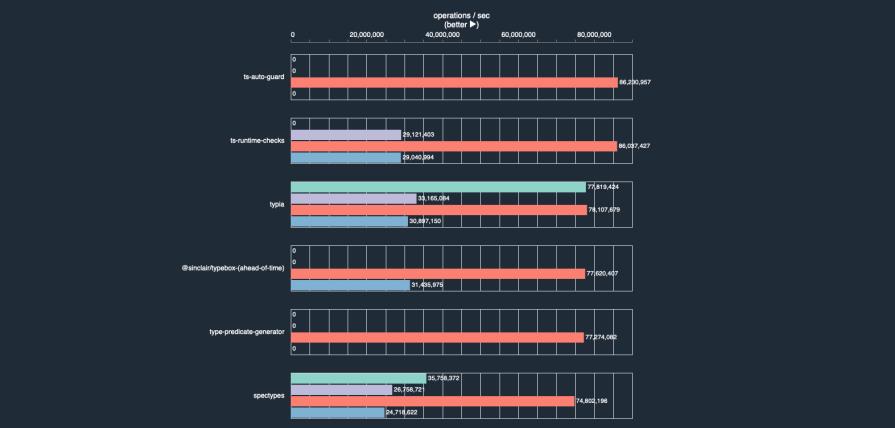
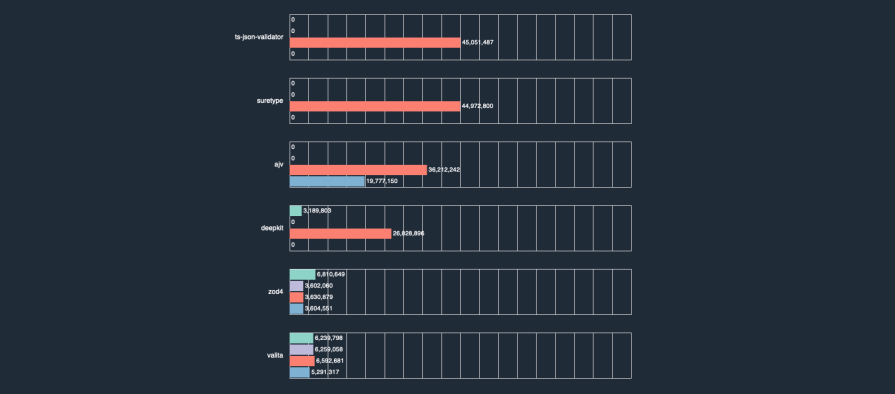
The immediate reaction to a chart like this is often defensive — and for good reason. The most common counterargument is that for the vast majority of web applications, this difference is purely academic. In a typical CRUD app, the few milliseconds Zod might spend validating an incoming request payload are completely dwarfed by network latency, database queries, and other I/O operations. In this context, choosing a library with a superior developer experience like Zod is a perfectly rational trade-off. For 95% of use cases, Zod is, without question, “fast enough.”
This article is for the other 5%.
The conversation changes dramatically when we move from typical web applications to high-throughput systems. Consider a real-world scenario: a high-traffic API gateway designed to handle billions of requests per day. For such a service, every CPU cycle counts. Profiling one such gateway revealed that Zod validation was consistently the single largest consumer of CPU time, creating a significant performance bottleneck that directly impacted infrastructure costs.
This isn’t a theoretical benchmark; it’s a production reality. In these environments, the performance difference stops being a micro-optimization and becomes a critical factor. After implementing an optimization for how Zod was used — a technique we’ll cover later in this article — the service’s CPU usage plummeted from a sustained 80% down to just 20%. This is the kind of impact that proves the performance gap, for a certain class of applications, is a problem that demands a solution.
To understand why the performance gap exists, we need to look under the hood. The difference between Zod and its faster competitors isn’t about small optimizations; it’s a fundamental split in their architectural philosophy. It’s a classic tale of the interpreter versus the compiler.
Zod’s greatest strength — its phenomenal developer experience — comes from its architecture as a runtime interpreter. When you define a schema, you’re creating a descriptive object, a blueprint that Zod holds in memory.
import { z } from "zod";
const UserSchema = z.object({
username: z.string().min(3),
email: z.string().email(),
age: z.number().positive(),
});
When you call UserSchema.parse(data), Zod’s engine begins a dynamic process. It traverses the UserSchema object graph, key by key, and executes the validation logic for each part (.string(), .min(3), etc.) in real time.
This approach is powerful and flexible. It allows for complex, dynamic schemas, rich error reporting, and the elegant, chainable API developers love. However, this interpretation carries a performance cost. For every validation, the JavaScript engine must walk the object graph and execute the corresponding logic. This dynamic overhead, repeated thousands or millions of times, is the source of the slowness in high-throughput scenarios.
Libraries like Typia take a completely different approach: Ahead-of-Time (AOT) compilation. Instead of interpreting a schema object at runtime, they use a build step to analyze your TypeScript types or schemas and generate raw, highly optimized JavaScript validation functions.
// A simplified, conceptual example of AOT-generated code
const validateUser = (input) => {
if (typeof input !== "object" || input === null) return false;
if (typeof input.username !== "string" || input.username.length < 3) return false;
if (typeof input.email !== "string" || !/^[^\s@]+@[^\s@]+\.[^\s@]+$/.test(input.email)) return false;
if (typeof input.age !== "number" || input.age <= 0) return false;
return true;
};
At runtime, there is no schema object to traverse — only a simple, highly optimized function made of basic JavaScript checks. This code is incredibly fast because modern JavaScript engines like V8 are exceptionally good at optimizing these straightforward patterns.
This is the core of the performance difference. Zod pays a runtime cost for its dynamic flexibility, while AOT validators pay a (one-time) build-step cost for extreme runtime speed. Understanding this trade-off is the key to unlocking the best of both worlds.
Understanding the architectural trade-off between Zod and its competitors leads to a powerful question: what if we didn’t have to choose? What if we could keep Zod’s world-class developer experience during development and get raw, AOT-compiled performance in production?
This is not only possible — it’s a practical solution for optimizing critical hot paths in your application.
// server.ts
import express from "express";
import { z } from "zod";
const app = express();
app.use(express.json());
const UserSchema = z.object({
username: z.string().min(3),
email: z.string().email(),
age: z.number().positive(),
});
app.post("/users", (req, res) => {
try {
const validatedData = UserSchema.parse(req.body);
res.status(201).send({ message: "User created!", data: validatedData });
} catch (error) {
res.status(400).send({ message: "Invalid data", errors: error });
}
});
app.listen(3000, () => {
console.log("Server running on port 3000");
});
This code is clean, type-safe, and perfect for most use cases. But in a high-throughput environment, the UserSchema.parse(req.body) line becomes the bottleneck.
To eliminate the runtime interpretation cost, we can use a build script. The strategy is to convert Zod schemas into JSON Schemas, then use a fast JSON Schema validator like ajv to compile them into JavaScript functions.
npm install -D ajv zod-to-json-schema
// scripts/compileValidators.ts
import fs from "fs";
import path from "path";
import Ajv from "ajv";
import { zodToJsonSchema } from "zod-to-json-schema";
import { UserSchema } from "../src/schemas";
const ajv = new Ajv();
const schemaName = "UserSchema";
const jsonSchema = zodToJsonSchema(UserSchema, schemaName);
const validate = ajv.compile(jsonSchema);
const validatorModule = `
const Ajv = require("ajv");
const ajv = new Ajv();
module.exports = ajv.compile(${JSON.stringify(validate.schema)});
`;
const outputPath = path.join(__dirname, "../src/validators");
if (!fs.existsSync(outputPath)) {
fs.mkdirSync(outputPath);
}
fs.writeFileSync(path.join(outputPath, "userValidator.js"), validatorModule);
console.log("Validators compiled successfully!");
Then, add this to package.json to run before your app starts:
{
"scripts": {
"build:validators": "ts-node scripts/compileValidators.ts",
"start": "npm run build:validators && ts-node src/server.ts"
}
}
// server.ts (refactored)
import express from "express";
const validateUser = require("./validators/userValidator");
const app = express();
app.use(express.json());
app.post("/users", (req, res) => {
const isValid = validateUser(req.body);
if (!isValid) {
return res.status(400).send({ message: "Invalid data", errors: validateUser.errors });
}
res.status(201).send({ message: "User created!", data: req.body });
});
app.listen(3000, () => {
console.log("Server running on port 3000");
});
By shifting the performance cost from runtime to compile time, the application now executes a simple, optimized function instead of dynamically interpreting schemas.
To account for the bad UX of requiring a build step in development that would break HMR, and potentially slow down the dev feedback loop, add the following:
// server.ts
...
import { UserSchema } from "./schemas"; // Import Zod schema for dev
...
// Use compiled validator in production, Zod in development
const validateUser = process.env.NODE_ENV === "production"
? require("./validators/userValidator")
: (data: unknown) => {
try {
UserSchema.parse(data);
return true;
} catch (error) {
validateUser.errors = error;
return false;
}
};
...
Then, update package.json scripts to:
{
"scripts": {
...
"dev": "ts-node src/server.ts",
"start": "npm run build:validators && NODE_ENV=production ts-node src/server.ts"
}
}
Zod’s position as the gold standard for TypeScript validation is well-earned, thanks to a developer experience that’s second to none. However, this flexibility comes from its nature as a runtime interpreter — a design choice that creates a significant performance bottleneck in high-throughput applications when compared to Ahead-of-Time (AOT) compiled alternatives.
This architectural trade-off is the real reason Zod can be slow, turning its greatest strength into a weakness in demanding environments. But as we’ve shown, this doesn’t force a choice between developer experience and elite performance. By implementing a build-time compilation step, we can transform Zod schemas into highly optimized functions for production — effectively eliminating the bottleneck.
This pattern is a powerful reminder that we don’t have to discard the tools that make us productive; instead, by understanding their core trade-offs, we can strategically optimize them to meet the demands of any environment.

Learn how to use Gemini CLI subagents to delegate frontend, backend, testing, and docs tasks to specialized agents with guardrails and clear ownership.

Learn how next-browser gives AI agents runtime context for debugging Next.js apps, including React props, hydration, PPR, forms, and performance.

Build dynamic LLM routing in Next.js with OpenRouter, TanStack AI, task classification, model fallbacks, and cost-aware routing.

TSRX adds first-class control flow, conditional hooks, and scoped styles to React via a TypeScript compiler extension — no new framework required.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

