GraphQL and REST are the two most popular architectures for API development and integration, facilitating data transmissions between clients and servers. In a REST architecture, the client makes HTTP requests to different endpoints, and the data is sent as an HTTP response, while in GraphQL, the client requests data with queries to a single endpoint.

In this article, we’ll evaluate both REST and GraphQL so you can decide which approach best fits your project’s needs.
Editor’s note: This article was last updated by Temitope Oyedele in March 2025 to include decision-making criteria for when to use GraphQL vs. REST, as well as to update relevant code snippets.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
REST (Representational State Transfer) is a set of rules that has been the common standard for building web API since the early 2000s. An API that follows the REST principles is called a RESTful API.
A RESTful API helps structure resources into a set of unique uniform resource identifiers (URIs), which serve as addresses for different types of resources on a server. The URIs are used in combination with HTTP verbs, which tell the server what we want to do with the resource.
These verbs are the HTTP methods used to perform CRUD (Create, Read, Update, and Delete) operations:
POST: Means to createGET: Means to readPUT: Means to updateDELETE: Means to deleteSome requests, like POST and PUT, sometimes include a JSON or form-data payload that contains server-side information. The server processes the request and responds with an HTTP status code that indicates the outcome, which, most of the time, can include a response body containing data or details.
The HTTP status codes are as follows:
200-level: A request was successful400-level : Something was wrong with the request500-level : Something is wrong at the server level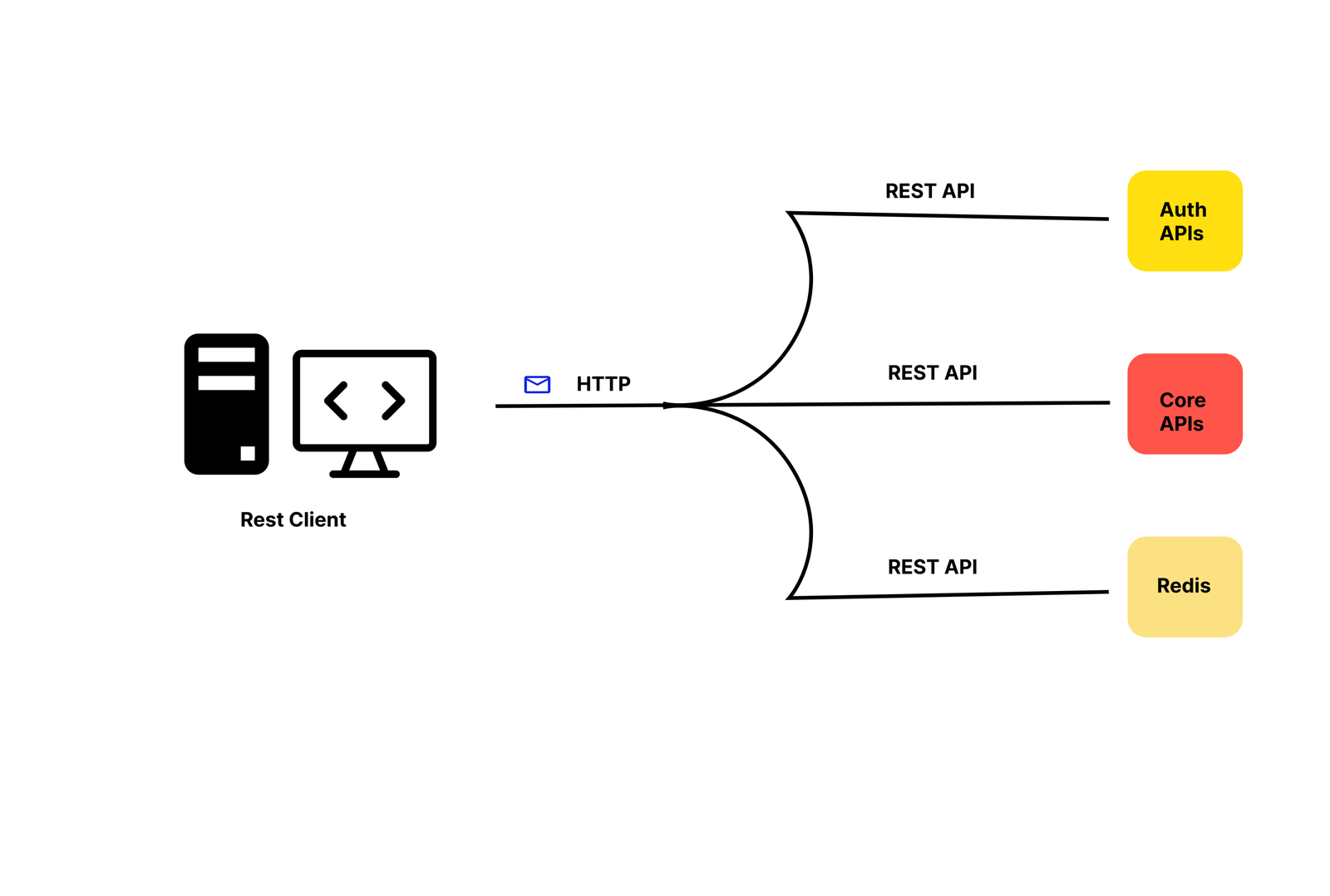
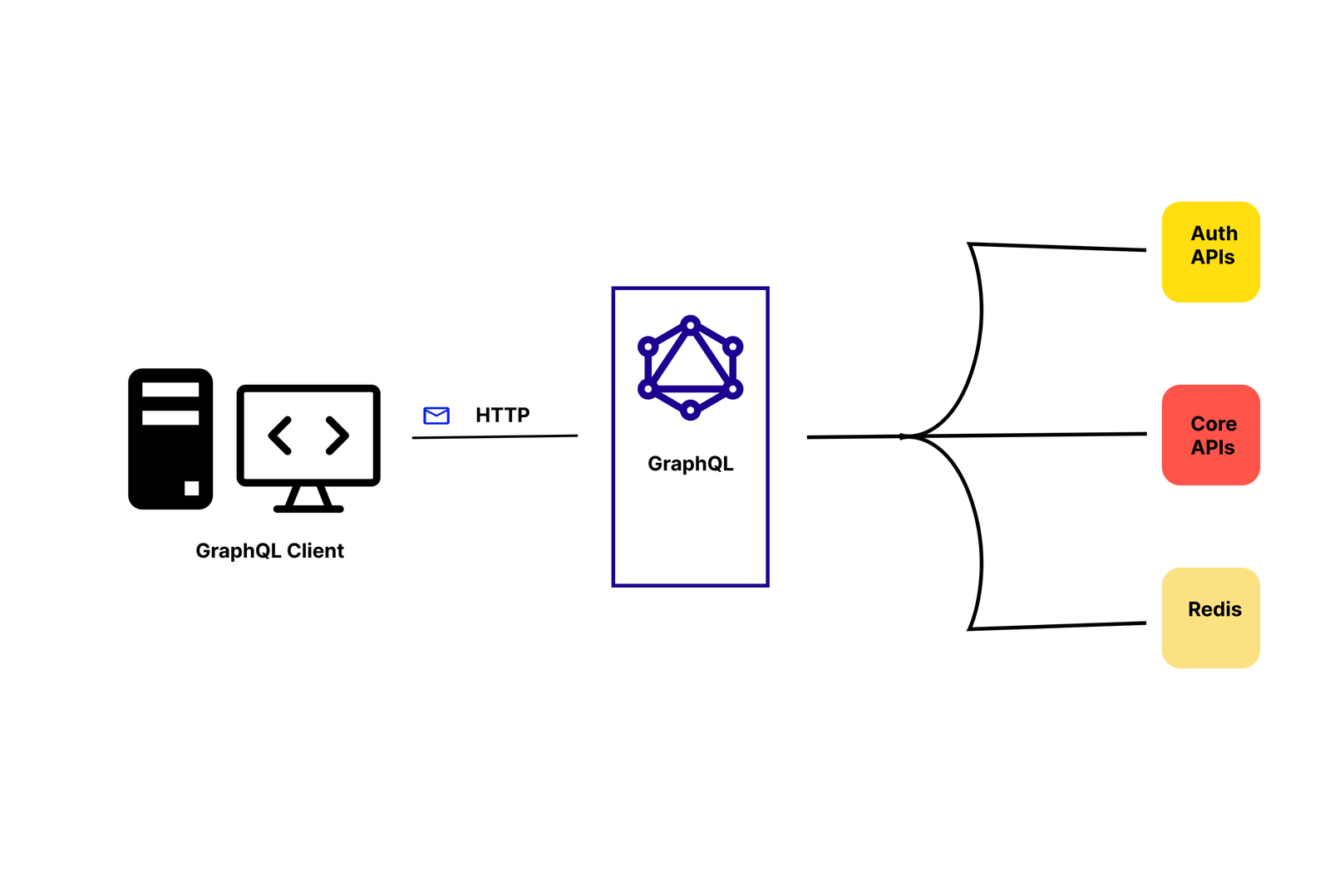
GraphQL is a query language developed by Meta. It provides a schema of the data in the API and gives clients the power to ask for exactly what they need.
GraphQL sits between the clients and the backend services. One cool thing about GraphQL is that it can aggregate multiple resource requests into a single query. It also supports mutations, which are GraphQL’s way of applying data modifications, and subscriptions, which are GraphQL’s way of notifying clients about data modifications during real-time communications:
REST centers around resources, each identified by a unique URL. For example, to fetch a single book resource, you might do:
GET /api/books/123
The response might look like this:
{
"title": "Understanding REST APIs",
"authors": [
{
"name": "John Doe"
},
{
"name": "Anonymous"
}
]
}
Some APIs can split related data into separate endpoints. For example, a different request might fetch the authors instead of including them in the main book response. The exact design depends on how the API is structured.
GraphQL, on the other hand, uses a single endpoint (e.g., /graphql) and lets clients query exactly the data they need in one request. You start by defining types, and then the client sends a query describing which fields to fetch. For example, after defining your Book and Author types, a query for the same book data could look like this:
query {
book(id: "123") {
title
authors {
name
}
}
}
The response contains only the requested fields:
{
"data": {
"book": {
"title": "Understanding GraphQL APIs",
"authors": [
{
"name": "John Doe"
},
{
"name": "Anonymous"
}
]
}
}
}
This approach reduces over-fetching and under-fetching since the client decides exactly which fields to request.
REST uses HTTP status codes for error handling and relies on standard HTTP methods (GET, POST, PUT, DELETE). It provides a variety of API authentication and encryption mechanisms, such as TLS, JWTs, OAuth 2.0, and API keys.
GraphQL uses a single endpoint and requires safeguards like query depth limiting, introspection control, and authentication to prevent abuse. While simpler in some ways, it can introduce complexity. As a developer, you’ll need to come up with some authentication and authorization methods to prevent performance issues and denial-of-service (DoS) caused by introspection.
REST has a rigid structure, as it can return unwanted data when over-fetched and insufficient data when under-fetched. This means you might need to make multiple calls, which increases the time required to retrieve the necessary information.
GraphQL, on the other hand, allows clients a lot of flexibility by giving the client exactly what is requested with a single API call. The client specifies the structure of the requested information and the server returns just that. This eliminates over-fetching and under-fetching issues and makes data fetching more efficient.
RESTful APIs adopt versioning to manage modifications on data structures and deprecations in order to avoid system failures and service disruptions for end users. This means you need to build versions for every change or update that you make, and if the number of versions grows, maintenance can become difficult.
GraphQL, on the other hand, reduces the need for versioning as it has a single versioned endpoint. It allows you to define your data requirements in the query. GraphQL manages updates and deprecations by updating and extending the schema without explicitly versioning the API.
REST is widely used across several industries. For example, platforms like Spotify and Netflix use RESTful APIs to access media from remote servers. Companies like Stripe and PayPal use REST to securely process transactions and manage payments. Other companies that use REST include Amazon, Google, and Twilio.
GraphQL’s popularity has grown in recent years and is now being used by companies and organizations. For example, GraphQL is using Meta, its creator, to solve the inefficiencies of RESTful APIs. Samsung also uses it for its customer engagement platform. Other companies that use GraphQL include Netflix, Shopify, Twitter, etc.
Because REST APIs are poorly typed, you need to implement error handling. This means using HTTP status codes to indicate the status or success of a request. For example, if a resource is not found, the server returns 404, and if there’s a server error, it returns a 500 Error.
GraphQL, on the other hand, always returns a 200 ok status for all requests regardless of whether they resulted in an error. The system communicates errors in the response body alongside the data, which requires you to parse the data payload to determine whether the request was successful.
REST doesn’t inherently provide type definitions, making it prone to runtime errors in client-side applications.
GraphQL ships with built-in type safety in its schema. Each field in the schema is typed, ensuring that clients know the exact structure and type of the data they will receive. This reduces runtime errors in client-side applications.
API technologies like REST would require multiple HTTP calls to access data from multiple sources.
On the other hand, GraphQL simplifies aggregating data from multiple sources or APIs and then resolving the data to the client in a single API call.
Below is a detailed comparison table summarizing their main differences:
| Feature | REST | GraphQL |
|---|---|---|
| Data fetching | May over-fetch or under-fetch data due to fixed endpoints | Fetches only the requested fields, reducing data transfer overhead |
| API schema | No strict schema enforcement by default | Uses Schema Definition Language (SDL) to enforce a strongly typed schema |
| Number of endpoints | Multiple endpoints for different resources | Single endpoint handling all queries and mutations |
| Caching | Built-in support with HTTP caching (CDN, browser, and proxy caching) | More complex; requires custom caching strategies |
| Error handling | Uses HTTP status codes (e.g., 404, 500) for clear error responses | Returns 200 OK even for errors; requires parsing the error object |
| Real-time updates | Requires WebSockets, polling, or SSE for real-time communication | Supports real-time subscriptions natively |
| Complex queries | Clients must make multiple requests to retrieve related data | Clients can request multiple related entities in a single query |
| Security | Easier to enforce role-based access and rate-limiting | Requires additional security measures, such as query complexity limits |
| Industry adoption | Still the dominant API standard in enterprise, finance, and healthcare | Gaining popularity in startups, ecommerce, and social media apps |
Each has its advantages and disadvantages, so the choice ultimately depends on your project’s needs. Do you want your project to be built based on performance, security, or flexibility? Once you’ve answered that, you can choose the one that best suits your project.
REST provides you with a scalable API architecture that powers millions of applications worldwide. It excels in simplicity, caching, and security, which makes it the go-to choice for public APIs, financial services, and enterprise applications.
Choose REST when:
GraphQL on the other hand, would give you full control over data fetching. It’s perfect for flexible, frontend-driven applications that require real-time updates and efficient API queries.
Choose GraphQL when:
Both GraphQL and REST offer distinct advantages. REST is used for most applications due to its simplicity and dependability, but GraphQL is best suited for modern, frontend-driven apps that require flexibility and efficiency. Knowing all of this will help you choose the right architecture for your project.
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

How senior engineers run TypeScript effectively at scale in modern codebases.

Discover what’s new in The Replay, LogRocket’s newsletter for dev and engineering leaders, in the March 18th issue.

A CTO outlines his case for how leaders should prioritize complex thinking over framework knowledge when hiring engineers for the AI era.

Build dynamic, AI-generated UI safely with Vercel’s JSON Render using structured JSON, validated components, and React.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now


55 Replies to "GraphQL vs. REST APIs: What’s the difference between them"
I think all this article did was convince me that REST has hacks for things that GraphQL has natively. You argue, “There are many libraries by way of JSON API and JSON Schema” but when there is a library that solves a pain point for GraphQL your counter point is, “it means adding another dependency to manage your project”.
Your argument for performance and heavy queries is silly. If someone wants to do a heavy query, it’s more taxing on the server in the REST model because of the network overhead. Neither REST nor GraphQL are going to stop people from doing bad, bloated queries or sets of queries.
The whole idea is that REST constrains what you are allowed to query, whereas GraphQL is less constrained, with the potential for user provided queries which kill the back-end.
Fundamentally untrue. Can only be said by someone with a limited knowledge of graphql. Graphql is easier to strictly define than rest and constraints are easier to apply and uphold.
With OpenAPI and JSON Schema you can define HTTP APIs as strict as you like. The question is not about strictness of definitions, though. In HTTP APIs you expose resources and representations that solve clients’ needs, which you are sure will work correctly regardless of the load. GraphQL lacks any means to constrain the liberty of creating complex queries, apart from the manual implementation directly in the resolvers. I recently learned that even Facebook exposes only a predefined set of “allowed” queries, which means that if they, as the creators of this technology, can’t solve the problem, then you also won’t. This also means that this liberty of creating queries may be a small benefit in the beginning, but in the long run you will have more issues with constraining GraphQL to do ONLY what you wanted in the first place. HTTP APIs can do everything GraphQL does, but not the other way. You could even send GraphQL query as a per-resource GET media type and still have a HTTP API for everything else!
Github is imposing node count and rate limit restrictions for their GraphQL API. See https://docs.github.com/en/graphql/overview/resource-limitations.
Sure, they impose rate limits for their REST API too.
But considering that proxy/CDN per-URL caching works just fine for REST APIs and that GraphQL queries can produce much higher server load. consider such restrictions especially for you GraphQL APIs deployment.
I might consider using it after it’s mature enough like REST. Error handling only is not a small thing to me to mess with.
with GraphQL you can use persisted queries and receive them with GET. This way you can have them cached on CDN for each query+params combination.
This article made myself more convinced to use GraphQL, rather than re-inventing the wheel by implementing your own query language on top of a general REST interface.
GraphQL has potential but caches issues are a great problem
I don’t believe GraphQL has cache problems, it just depends on the architecture of your GraphQL application
Thank you for your perspective, maybe graphql is not yet the best tool in some occasions but it is possible that with the development of this query language in a near future graphql surpass rest, another perspective is given in this article that gives the opinion of using graphql or making co exist with rest https://www.imaginarycloud.com/blog/graphql-vs-rest/.
GraphQL is great etc but there will be certain use cases where REST may be more suitable.
In my case we have a Java backend ecommerce server that needs to Shopify API (they have REST and GraphQL APIs).
We GET all orders from a RESTorders endpoint and then UPDATE the status of the orders it’s processed. Same for the inventory REST endpoint.
For the most part those are the only endpoints our backend system needs to connect to, it can limit the fields it needs to request in the REST query and is unlikely to change the query and updates anytime soon.
If it used GraphQL it would need to install Ruby, migrate the build from ant to Gradle. So there will be a lot more complexities and additional dependancies to the runtime environment.
Also we only have dev team, small-ish project and we are consuming not building APIs so no need for the flexibility of GraphQL.
GraphQL and REST are ultimately tools and every tool has it’s use.
If I had the chance I would explain to every REST designer that this: “GET /books/1492030716?fields=title,pageCount” does NOT scale.
I’ve been working at a large payroll company where we have canonical representations of human resources which for example represent a ‘worker’. Those schemas are huge. Like 18.000 lines huge. You absolutely 100% don’t successfully whitelist those with a “fields” querysstring item. Nor do you successfully filter them with a $filter querystring item. It’s just too large.
Graphql is the way to go there.
how about sending a GET with something in the request body?
Using request body in a get request is bad practice
It depends on how many clients do you need to adapt. If you only have one client, let’s say a web page, which always displays 100 fields, then you don’t need to pass the fields to the API, just always return those 100 fields. If you have a lot clients to adapt, which will show different sets of fields, then it’s a different story. But even in multi-clients situation, you can still do the job using restful, design the url pattern like:
/worker/1/basic-info
/worker/1/family-info
“It may be done poorly” is not a compelling argument against any particular technology.
“It adds complexity” can be, but one assumes we are not talking trivial cases in arguments like this, so what’s really necessary is to show whether the complexity is significant on a serious project. GraphQL can drastically simplify the number and complexity of routes, e.g., versus a standard REST project.
Performance arguments can be as well, but again, you need an apples-to-apples comparison. A big part of the purpose of GraphQL is to eliminate the multiple round-trips. If that’s not a pain point for you, maybe it’s not necessary. But if it is, you’re going to end up building increasing numbers of REST calls to accommodate.
Possible, but not standard — https://stackoverflow.com/questions/978061/http-get-with-request-body
Agree but oData is worse than graphQL
Custom caching = more complexity. Just added a 3rd level of custom cache to our gql app.
“It may be done poorly” is not a compelling argument against any particular technology.
I think how frequently is a very important indication if not the most important against a tech stack, i looked at 3 graphQL implementations recently and they were all slow and terrible.
Something as simple as REST and its still done poorly in say half the cases for something as complex as GraphQL especially ins strongly typed languages id suggest the chance of a good outcome is very low and would certainly need management buy in to have a few goes at getting right.
They more I use graphql the less I like it. So far I couldn’t find anything that graphql does that REST wouldn’t do. Especially sucks java implementation of graphql: starting with outdated documentation and examples ending with their design choice of chain of builders of the builders of the builders… Nice try to generalize queries and put them under one umbrella, but it’s more pain than it’s worth.
If you want to query your API, why not SQL? See a POC at: https://github.com/zolyfarkas/jaxrs-spf4j-demo/wiki/AvroCalciteRest the advantage is that SQL is something everybody is already familiar with…
having used GraphQL, I see why a lot of new comers won’t bite this article, but in fact if you use it for a while, you’ll see why it can lead to some bloated APIs, moreover, I do think there are better alternatives, besides, think of who created it, Facebook, they created this piece of tech to suite their own needs, which I can argue is not what I would consider a general need, but rather driven by their business requirements. Things like using HTTP status codes, etc, these are important, and can in fact simplify clients significantly, but I guess for those who have not used it really, they won’t know these things, or yet they’ve got to stumble upon them.
Completely agree with Suhail Abood. GraphQL should not be seen as a general purpose REST replacement, which currently seems to be happening a lot. I am working on a new GraphQL API and it is already a big ugly mess with many issues that need to be resolved that would not have existed were it created in REST.
I think getting the full benefits from GraphQL requires a paradigm shift. GraphQL is inherently about type-driven design. It supports algebraic data types and this plays really nicely with functional programming languages that natively support AlgDTs. GraphQL also supports a Functional Domain Driven Design approach.
Also, if you use a GraphQL endpoint like Hasura, you can create end-to-end modelling of domain entities in your data. Dillon Kearns, a developer who uses Elm, discusses a “types without borders” benefit of GraphQL:
https://www.youtube.com/watch?v=memIRXFSNkU
When you take a deep type-driven design approach using AlgDTs as the basis for your data entities you get a whole host of benefits. This comment really says it all:
https://softwareengineering.stackexchange.com/questions/317587/is-it-still-valid-to-speak-about-anemic-model-in-the-context-of-functional-progr/317599#317599
Scott Wlashin doesn’t specifically mention GraphQL but everything in his talk is the background for thinking about GraphQL:
https://www.youtube.com/watch?v=1pSH8kElmM4
Scott also talks about creating APIs that give consumers feedback about what they can do, rather than just erroring what they can’t:
https://www.youtube.com/watch?v=fi1FsDW1QeY
Also, look at Richard Feldman’s talk “Making impossible states impossible”:
https://www.youtube.com/watch?v=IcgmSRJHu_8
I think that when you care deeply about type-driven design GraphQL makes a whole lot of sense. Especially if your language supports AlgDTs and type and function composition. As well as immutable data.
Also check this article out that links GraphQL with CQRS and Event Sourcing:
https://gist.github.com/OlegIlyenko/a5a9ab1b000ba0b5b1ad
There is also this awesome article that really helps to put CQRS and Event Sourcing into perspective:
https://gist.github.com/OlegIlyenko/a5a9ab1b000ba0b5b1ad
Check out Hasura GraphQL Endpoint:
https://blog.hasura.io/
I think GraphQL is just getting started.
“Performance issues with GraphQL queries”
This is exactly the reason why GraphQL is not bad, IT’S DANGEROUS.
GraphQL could work fine for small set of data. Some developers think that since they use the cloud then they don’t need a DBA so the end user could exploit the queries as they are pleased… Well, the cloud is metered (also it is not unlimited unless you want to pay really premium for that).
About DBA, even a server-less configuration needs a DBA (because AWS and Azure makes a poor DBA replacement). And if the project has a DBA, then he (or she) will say “nope!” to GraphQL.
In any case, it’s not rare to find rookies that does not even know about paging a query, so they load 1 million of rows to simply list 50 rows.
You are aware that you can have input parameter and valid them like how high a number can go, right?
There is no body in GET request according to the HTTP standard.
In what possible way is OData worse than GraphQL? It’s far more feature complete, makes all tasks simpler, handles errors beautifully, and handles update and deep inserts/updates seamlessly.
Graphl it is very bureaucratic and slows down development
Couldn’t you just use a separate endpoint for the requests that need specific return fields?
The request body in a GET request will most likely be ignored by the server.
https://stackoverflow.com/questions/978061/http-get-with-request-body
In rest you need to write your api, then write a swagger of the contract, then use a code generator for your client to finally have your api running between your server and client. There is several possible point of failure:
1. You can easily design your rest api the wrong way
2. You might be stuck in rest to find the right path url to link 2 or more concepts together
3. You might introduce mistakes writing the swagger and you need to document both the swagger and your code
4. Your client api generator might not generate exactly what is inside your swagger dropping some typings
5. The client generated might implicitly rely on way to post data which your server might not support (I had the problem with form and Autorest for instance)
With a GraphQL schema at least you do have a typed AND documented contract, thanks to the GraphQL standard your endpoint does not give you a lot for interpretation for your client.
@Aaron GET has no body!
Interesting, looks like we came full circle back to WCF+RIA Services that did SQL queries against WCF Rest services.
Not sure what you’re using, but in DotNet, you just build the service and the swagger is auto-generated. Nothing to keep in sync, no mistakes in swagger.
I feel hate to GraphQL and that someone hasn’t bothered to investigate properly
Agree with comments here – more reason to use it, than not
Just implement properly
Instead of only `fields`= why not:
`include`=
`exclude`=
Also 18k LINES in for a “worker” instance?!??! Really?
Your problem is modeling and design, at many levels, not technology.
Half of these complaints seem to be that GraphQL isn’t conducive to the kinds of bad habits that loose typing tends to bring.
Am I missing something?
I agree that GraphQL is not really the best solution in all cases. From what I’ve worked with, not even most cases. If you have to let the client limit fields you may have a use case for using this technology but, if not, the added complexity just adds headaches for the team. Not to mention teaching new team members how to use it and trying to explain to them that we can’t just rip it out. If you’re just doing a basic api for a web application rest is easier to work with. I can only say this against .net core. Maybe other technologies see graphql as a breath of fresh air but in .net core rest is really easy to implement.
The error part with graphql returning a 200 even when there are errors is a huge red flag for me. When I develop an api I want it to use those internet standards.
What are “internet standards” for error handling? In my opinion those differ per API. Sometimes I’ve seen RESTful APIs that always return 200s but in the event of an error the body of the response has the error information. I’ve seen that work well. Other APIs that are more “pure” use the HTTP response codes to codify errors. You still have a document how you’re using those and what they mean. GraphQL is no different. You get to choose the return payload and you can construct it in a way to communicate errors just fine, it’s just not with HTTP status codes because those don’t make as much sense with GraphQL since it is designed to be agnostic of the protocol over which it is communicated. Unlike rest, I think they have actually achieved something that can work outside of HTTP just fine. REST was supposed to be agnostic of the HTTP protocol in the original design, but it has become so tied to HTTP, I don’t know that it would work in any other system.
I’d say in the end, use the right tool for the right job. I think GraphQL solves a nice problem that is hard in REST to get consistently right. I don’t know that this article has really given GraphQL enough focus to see what it can really do. I personally have been involved in large RESTful API construction and it has worked fine, but as I’ve looked into GraphQL, there are lots of things native to it that we’ve had to spend a lot of time figuring out how to do correctly and maintainably in REST.
Look up RFC 7807 Problem API.
The title of this article is misleading and seems to contradict your conclusion.
Thanks for the tip — I can see how the conclusion was a bit confusing and seemed contradictory. It’s been reworded a bit to reflect the main focus of the article.
Exactly. It should have been “When to use GraphQL” but then no one would click it.
Hello, I came into a project using graphql and hasura. Front end developers wrote queries that kill the database. It is an incredible pain to debug as everything is 200, and then have to go look up the errors in Hasura UI (which is very buggy). Everything a post. Different schema results based on what the graphql query does. We are dropping GraphQL/hasura as a failed experiment. I gave it my best try, but GraphQL is a solution in search of a problem.
Sounds more like the problem is more that the backend team didn’t RTFM with GraphQL as opposed to GraphQL itself being the problem.
What you might want to do is use GraphQL schemas and design REST-like APIs and Endpoints.
Boom, all the performance benefits of using architectures exposed by REST to design efficient query patterns (using efficient indexes and joins on the database), with effectively free documentation to evolve your API.
No need to manually re-program yet another REST API and find manual / semi-automated ways to communicate changes if you can use GQL like REST. So much easier to deal with. One of the amazing features of GQL is the shared schema, and by god I’ll use it.
(yes I also have use and use GraphQL properly but it is often more expensive against databases and I wouldn’t use it for any high throughput solution)
Why is GraphQL Schema listed as a disadvantage? Schemas are a massive advantage of GraphQL: clearly define and validate requests, and build certainty into the response structure. Contract violations cannot occur in GraphQL; this is built into the framework. You also neglected to mention how GraphQL makes versioning much simpler.
Reading the performance issue part confuses me. At the end of the day, if the client needs that information, they’re going to get that information. So in REST they could equally just send a huge number of API requests trying to get all of the reviews for all books so they can filter by author.
I think you’re arguing that you could make a REST API specifically designed to grab this information they want, but you can equally do that in GraphQL. So say, as in your example, your goal is to get a list of users that have reviewed a given author. You could simply add a `reviewers` field onto the author object. `author.reviewers.name`. That’s now a “shortcut” to users who have reviewed that author.
That’s how GraphQL should be designed. It should be a densely weaved mesh of interconnectivity. Trying to stick to some “pure” resource based set of resolvers is going to be just as bad in GraphQL as it can be in “pure” REST APIs. If you need a connection to exist because a client needs it and you want it to be performant, THEN ADD IT! You would have to add that in REST, and you have to add it to GraphQL as well.
A huge part of GraphQL is shifting functionality complexity from the client to the server. You put more effort into the GraphQL design, and this allows your clients to be mindless by comparison.
RPC is what people want, REST is what they get. While it can do the job, REST is just a mistake in itself, there are so many possible points of frictions between creating a swagger (openAPI) properly, handling the errors, generating a compatible, typed client etc. that you better directly use an RPC protocol precisely made for this purpose. Unless you need high performances such as gRPC, GraphQL does this job as good as any RPC protocol (if not better)
I liked your point about the 200 ok results from GraphQL errors. Other articles I’ve read don’t mention this. One thing I would clarify is that sending multiple requests could be handled using REST but you would need to make those requests on the server and send them back in a single response to the client. The question would then become do I want to place the burden of handling these requests to multiple sources on the server or on the client?
A question I would like to ask you is, from the perspective of developing and maintaining your code, is it better to be consistent in your use of one approach or is it advisable to mix use of GraphQL and REST in your project? For example, some requests I make to my server only use the user’s email as an argument. This means I would need to write code for a schema, resolver, and a query when using GraphQL. It is it worth adding all this code to manage a simple request in order to maintain uniform use of GraphQL throughout my code? On the other hand if I use a mix of both approaches then my error handling will have to be different between GraphQL and REST calls. What do you advise?
You can have both worlds of REST and RPC in your GraphQL schema. It’s about finding the right balance for you team and finding a convention that sticks.
I put together some ideas, with examples, of using a REST base blueprint which I extend with RPC-inspired queries/mutations: https://medium.com/@olegkomarov_77860/how-to-tame-your-graphql-schema-f83d08de41ef
Thanks for replying and sending the article. I feel like if I’m always chasing the latest technology I’m learning something new but never really fully applying what I already know. Years ago I just got done learning REST. Then GraphQl came on the scene and I was banging my head against the wall because now I had to learn a new technology or be left behind in the dust. I really don’t know what RPC. But rather chasing an unfamiliar technology I’m just going to stick with what I know.