Web scraping is a technique that lets you inspect, parse, and extract data from websites that would have otherwise been difficult to access due to the lack of a dedicated API. Web crawling involves systematically browsing the internet, starting with a “seed” URL, and recursively visiting the links the crawler finds on each visited page.

Colly is a Go package for writing both web scrapers and crawlers. It is based on Go’s net/HTTP (for network communication) and goquery (which lets you use a “jQuery-like” syntax to target HTML elements).
In this article, we will scrape the details of celebrities whose birthdays are on a certain date. We will be leveraging Colly’s powers to get this data from the IMDB website.
To follow along, you will need to have a system with Go installed (preferably version 1.14 or higher).
Note: The shell commands used below are for Linux/macOS but feel free to use your operating system’s equivalent if it’s different.
Create the directory where you want this code to live and initialize a new Go module:
$ mkdir birthdays-today && cd birthdays-today $ go mod init gitlab.com/idoko/birthdays-today
Colly is the only external package we need to install since it comes with the ability to make HTTP requests and parse the HTML DOM built-in. Run the command below to bring it in as an app dependency:
$ go get github.com/go-colly/colly
At the heart of Colly is the Collector component. Collectors are responsible for making network calls and they are configurable, allowing you to do things like modifying the UserAgent string, restricting the URLs to be crawled to specific domains, or making the crawler run asynchronously. You can initialize a new Collector with the code below:
c := colly.NewCollector(
// allow only IMDB links to be crawled, will visit all links if not set
colly.AllowedDomains("imdb.com", "www.imdb.com"),
// sets the recursion depth for links to visit, goes on forever if not set
colly.MaxDepth(3),
// enables asynchronous network requests
colly.Async(true),
)
Alternatively, you can let Colly use the default options by just calling:
c := colly.NewCollector()
Collectors can also have callbacks such as OnRequest and OnHTML attached to them. These callbacks are executed at different periods in the collection’s lifecycle (similar to React’s lifecycle methods), for instance, Colly calls the OnRequest method just before the collector makes an HTTP request. You can find a complete list of supported callbacks on Colly’s godoc page.
For more complex scrapers, you can also configure collectors to store the visited URLs and cookies on Redis or attach a debugger to them to see what’s going on under the hood.
Let’s create two separate functions – main and crawl. Our program calls main automatically, which in turn calls crawl to visit and extract the information we need from the web page. Later on, we will extend main to read the desired month and day as command-line arguments so that we can get the birthday list for any day:
package main
import (
"encoding/json"
"flag"
"fmt"
"github.com/gocolly/colly"
"log"
"strings"
)
func main() {
crawl()
}
func crawl() {
c := colly.NewCollector(
colly.AllowedDomains("imdb.com", "www.imdb.com"),
)
infoCollector := c.Clone()
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting: ", r.URL.String())
})
infoCollector.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting Profile URL: ", r.URL.String())
})
c.Visit("https://www.imdb.com/search/name/?birth_monthday=12-20")
}
The snippet above initializes a collector and restricts it to the “IMDB” domain. Because our scraper comprises of two sub-tasks (fetching the birthday list and fetching individual celebrity pages), we replicate the created collector using c.Clone(). We have also attached different OnRequest implementations to the collectors to know when they start running. Finally, it calls c.Visit with a “seed” URL which lists all the celebrities born on the 20th of December.
By default, the IMDB listing shows 50 items per page, with a Next link to go to the next page. We will recursively visit these next pages to get the complete list by attaching an OnHTML callback to the original collector object by attaching the code block below at the end of the crawl function (right before calling c.Visit):
c.OnHTML("a.lister-page-next", func(e *colly.HTMLElement) {
nextPage := e.Request.AbsoluteURL(e.Attr("href"))
c.Visit(nextPage)
})
The code targets the Next link and converts it to its full absolute URL. The URL is then visited, and the same thing happens on the next page. Note that this kind of fast, automated visit to a website could get your IP address blocked. You can explore Colly’s limit rules to simulate random delays between your requests.
Similarly, attach another OnHTML listener for visiting the individual celebrity pages to the first collector:
c.OnHTML(".mode-detail", func(e *colly.HTMLElement) {
profileUrl := e.ChildAttr("div.lister-item-image > a", "href")
profileUrl = e.Request.AbsoluteURL(profileUrl)
infoCollector.Visit(profileUrl)
})
In the snippet above, we delegate the infoCollector to visit the individual page. That way, we listen for when the page is ready and extract the data we need.
Next, let’s set up the movie and star structs to hold each celebrity’s data. The movie struct represents the details of the person’s top movies as listed on their page, and the star struct contains their bio-data. Add the following snippet right before the main function in the main.go file:
type movie struct {
Title string
Year string
}
type star struct {
Name string
Photo string
JobTitle string
BirthDate string
Bio string
TopMovies []movie
}
Next, attach a new OnHTML listener to the infoCollector in the crawl function. The callback will go through the profile container (the div whose ID is content-2-wide), extract and print the celebrity data contained in it.
For context, here is a sample IMDB profile page:
infoCollector.OnHTML("#content-2-wide", func(e *colly.HTMLElement) {
tmpProfile := star{}
tmpProfile.Name = e.ChildText("h1.header > span.itemprop")
tmpProfile.Photo = e.ChildAttr("#name-poster", "src")
tmpProfile.JobTitle = e.ChildText("#name-job-categories > a > span.itemprop")
tmpProfile.BirthDate = e.ChildAttr("#name-born-info time", "datetime")
tmpProfile.Bio = strings.TrimSpace(e.ChildText("#name-bio-text > div.name-trivia-bio-text > div.inline"))
e.ForEach("div.knownfor-title", func(_ int, kf *colly.HTMLElement) {
tmpMovie := movie{}
tmpMovie.Title = kf.ChildText("div.knownfor-title-role > a.knownfor-ellipsis")
tmpMovie.Year = kf.ChildText("div.knownfor-year > span.knownfor-ellipsis")
tmpProfile.TopMovies = append(tmpProfile.TopMovies, tmpMovie)
})
js, err := json.MarshalIndent(tmpProfile, "", " ")
if err != nil {
log.Fatal(err)
}
fmt.Println(string(js))
})
In addition to extracting the bio-data from the page, the code above also loops through the top movies the person featured in (identified by the divs whose classes are knownfor-title and stores them in the movie list. It then prints a formatted JSON representation of the star struct. You can as well go ahead and append it to an array of celebrities or store it in a database.
Our scraper is almost ready, though it only fetches the birthday list for a specific date (01/11). To make it more dynamic, we will add support for CLI flags so that we can pass in any day and month as command-line arguments.
Replace the current main function with the code below:
func main() {
month := flag.Int("month", 1, "Month to fetch birthdays for")
day := flag.Int("day", 1, "Day to fetch birthdays for")
flag.Parse()
crawl(*month, *day)
}
The above code block allows us to specify the month and day we are interested in e.g go run ./main.go--month=10 -- day=10 will fetch a list of celebrities whose birthdays are on the 10th of October.
Next, modify the crawl function to accept the month and day arguments by changing its signature from func crawl() to func crawl(month int, day int).
Use the function arguments in the seed URL by replacing the line that contains c.Visit("https://www.imdb.com/search/name/?birth_monthday=10-25") with the code below:
startUrl := fmt.Sprintf("https://www.imdb.com/search/name/?birth_monthday=%d-%d", month, day)
c.Visit(startUrl)
Build and run the scraper with the following commands:
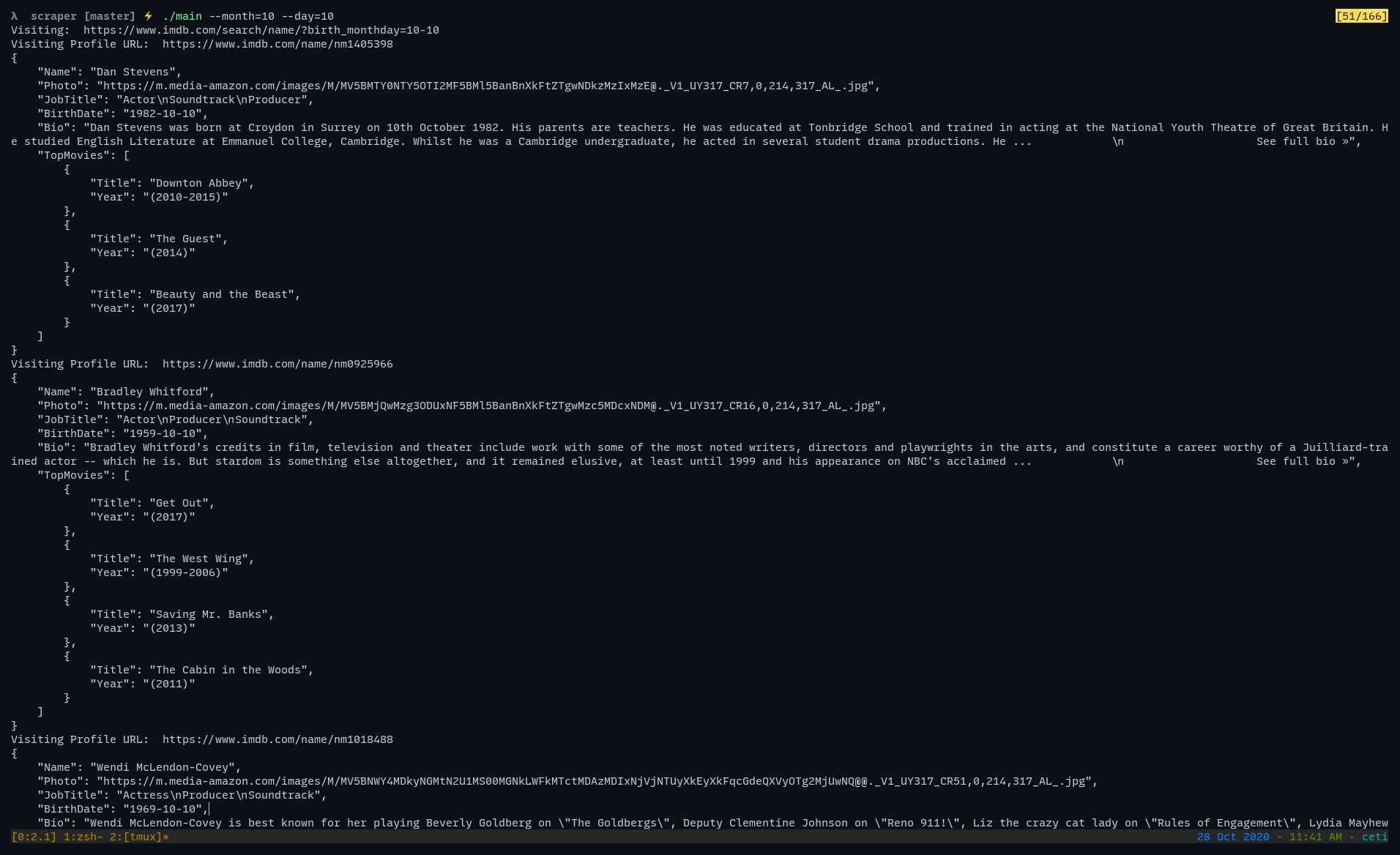
$ go build ./main.go $ ./main --month=10 --day=10
You should get a response similar to the screenshot below:
In this article, we learned how to crawl a website and extract information from the pages we visit to meet our needs. The complete source code is available on GitLab. Interested in exploring Colly further? Here are some links that could help:
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

Learn how to protect full-stack projects from NPM supply chain attacks with a practical security checklist.

Explore 15 essential MCP servers for web developers to enhance AI workflows with tools, data, and automation.

Learn how contrast-color() automatically picks accessible text colors using native CSS, without JavaScript.

Learn how to build a harness-style AI workflow using Claude Code with specialized Dev, QE, and Ops subagents, gated handoffs, MCP telemetry, and LEARNING.md.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now
