If you were to meet your friend in the street, straight away you would likely greet them and ask them how they are. Or, in the reverse, if your friend came up to you and asked you how you were, you would recognize them and have a conversation with them.

Why would we do this? It’s simple – we recognize our friend by the way they look. And, because they are our friend, we feel comfortable sharing with them how we are, and how our week has been.
As humans, we’re abstracted away from the implementation of this process, as our brain does it all for us automatically. We look at someone, recognize who they are, and move on with our conversation.
In all exchanges, we need to establish who someone is, but in the digital world, we can’t go on the way someone looks. Instead, people need to authenticate with an online service, and then we need to check that they are authorized to access the resource they are after. A large part of this involves JWTs, OAuth and Bearer token.
To understand these, we have to undertake 💫 the journey of understanding authentication on the web. 💫
When the web became a place where people could actually perform meaningful tasks, like banking or work, there came the implicit need to authenticate the people who were using services.
After all, we couldn’t just trust that the people who were supposed to use the services used them. Some way had to be implemented where people could prove they were who they said they were.
Initially, this was as simple as a username and password combination. In theory, you’re the only person who would ever know your password.
Typically, you would fill out a form on a webpage with your credentials and hit submit. Your details would be sent to the server via a HTTP POST request, and the server would check if your password matched what was on file, and then you were issued with a cookie.
The cookie would contain your token and would be submitted with every subsequent request so the server knew to trust you on each subsequent request.
If data needed to be stored during your session, such as what you had chosen or preferences, they could be stored in your session. Sometimes, this would be referred to as “sessionizing” your data.
Stashing data in the user’s session was an easy and cheap way of storing and retrieving transient pieces of information.
Unfortunately, this approach had several downsides:
As for storing data in a user’s session, this worked if there was one server serving up the application. The moment the server was spanned between multiple servers, all servers would have to keep their session in sync.
Many ways were devised to accomplish this, such as storing the session data on a database server, or in some kind of in-memory store, but the better solution in the long-run was to simply remove the session altogether.
Relying on a mutable data store on the server wasn’t a good idea, and ideally, the consumer should have all of the information needed for an app to work.
To bring it back to our original example, when we look at another person, we can assess quickly if we know them. Depending on whether we know them or not, we can give them more details about our life and what has been happening.
But we can’t rely on always being able to see someone to trust them. Sometimes, we can engage in an exchange of trust without seeing the other person.
For example, when you turn up to work, you might have a swipe card that you swipe against the card reader. The card reader reads your card, and if it’s valid, then you are authenticated. That’s better because you don’t have to disclose to anyone your password or anything that’s secret to you.
We know that using the card reader to enter the building is secure because the chain of trust is intact. The card reader is issued by a trustworthy company, and your access card is probably also issued by them. We could take the card away and store it somewhere for a long time, and when we came back to it, it would still be trustworthy.
If someone were to open the card up and change it or alter it to try to give them more access than they should have, they would damage the card instead, and it would cease to work.
JWTs are a bit like that. They are made up of three discrete components:
The algorithm for calculating the signature is the encrypted result of the header and the payload combined with a secret. Because of this, if the header or payload ever changed, the signature would be invalid and the contents would not be trusted.
So even if we included data in our JWT to indicate that a user was an admin, as long as the signature is validated correctly, we could be sure that the JWT was still a correct representation of that fact. Because the general public wouldn’t have access to our signing secret, we could be sure that the only entity that could have issued that JWT was our server.
We can easily see the contents of our JWT token on a site like https://jwt.io. The three components are separated by a single dot: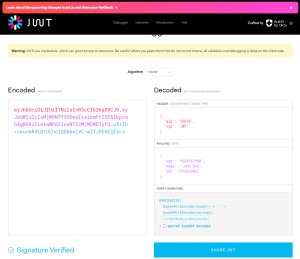
Now that we have a token, the next question should be how we present it to the server. Previous authentication methods would have required cookie based authentication. But, typically with our JWT tokens, we would present them to the server with the protected resources so we could be granted access.
This means that within our HTTP methods (POST, GET, etc.), we would also include a Authorization value. It would typically look like this:
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.uXrIhrveuvbR4tD1ULholQObboLVC-wIfJOEVElEzcs
With this token, the server can validate the token before parsing the claims within the token. What’s in a claim though?
Claims are just fields within the JWT that have information on the particular token. They fall into three categories: registered, public, and private.
Registered claims are standard fields that can be used within a JWT token. They’re not required but would typically be found in most tokens.
Public claims are defined by the application and relate to data for the application in use.
Private claims are custom claims used to share information between implementations, but only the entities involved know what the claims are and how they work.
So, a standard token could include an expiry date, the intended audience, and information on the user.
We’ve detailed what JWTs are, how they work, and why we can trust them. Frequently, they’re mentioned in conjunction with OAuth, and sometimes people try to compare them or try to choose one over the other.
However, they’re not comparable, but instead, OAuth typically uses JWT tokens to transport information that relates to it. Because JWTs are a reliable method to transit important data in a way that is tamper-proof, they are a good choice for use in OAuth 2.
For example, an ID token that OAuth sends is always sent as a JWT. When an access token is sent as well, it is also typically sent as a JWT. OAuth uses JWT to implement the various flows that relate to it.
Another type of token is the Bearer token, which is sent with every HTTP method in the Authorization header. This acts as a security resource that indicates that the bearer of the token is authorized to access the resource in question. For this reason, it’s important to only send the Bearer token to protected endpoints that require it.
OAuth could use any other viable system to transport its tokens around, but because JWT is a standard, that’s the one in use. In fact, JWT is being extended upon by OpenID Connect.
JWT and OAuth are critical parts of a secured and asynchronous web. As we’ve seen in this article, they’re not competitors, nor should you (or can you) choose one over the other. JWT exists in a complementary capacity to OAuth and does an excellent job of moving trusted data from point A to point B.
Debugging code is always a tedious task. But the more you understand your errors, the easier it is to fix them.
LogRocket allows you to understand these errors in new and unique ways. Our frontend monitoring solution tracks user engagement with your JavaScript frontends to give you the ability to see exactly what the user did that led to an error.
LogRocket records console logs, page load times, stack traces, slow network requests/responses with headers + bodies, browser metadata, and custom logs. Understanding the impact of your JavaScript code will never be easier!

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.

I migrated 20 production-style components from Tailwind to StyleX. Here’s what the data showed about LOC, CSS bundle size, build time, and type safety.

A guide for using JWT authentication to prevent basic security issues while understanding the shortcomings of JWTs.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

