This is the second post in the not all compilers are created equal series, in which we compare TypeScript (TS) and PureScript (PS), two statically typed languages that compile to JavaScript (JS). In the first post, we introduced both languages and explained their reason to be. We also talked about how having restrictions provide us certain guarantees that increase our confidence in the code. The first restriction we talked about was purity, in this post we are going to address another one: Immutability.

The world is always changing, and if a software application is trying to represent some aspect of the real world, it will have to have mutable state. But the fact that somewhere in the application we need to model values that change, doesn’t mean that all values in the program should be allowed to change. And I’d argue that adding a restriction to work with immutable data gives you the guarantee that no value will change unexpectedly.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Both JavaScript and TypeScript are mutable by default. We can use some of the language features to avoid accidental mutation, but we need to pay attention to some details.

It’s worth mentioning that the only TypeScript specific syntax is the type definition in line 26 and the as XXX in lines 28 and 32, the rest is plain old JavaScript that is validated by the compiler.
Being able to mark a value as read-only is really helpful when working with libraries such as Redux that relies on the reducers being immutable to properly work. Overlooking a situation where we mutate some data inadvertently is so common in plain JavaScript that there is a documentation page explaining the common mistakes and some patterns to correctly work with immutable data structures. By using TypeScript’s Readonly, ReadonlyArray and the new const assertions (released in version 3.4), we can free up our mind from that burden and put the weight in the compiler, trusting that it will lead us to more accurate code.
But Redux isn’t the only place where we can benefit from using immutable values. It is said that if you are not ashamed of the code you wrote X years ago, you haven’t learned anything in those X years( and I’ve learned a lot from an unfinished project that I wrote 6 years ago 😅).
It was a tool called mddoc that was meant to sync up documentation and code, read files that had references to other files, extract information and create a web page customized by plugins. One of the biggest problems was the communication between different steps of the program. I chose to use a shared mutable object that I called Metadata.
Without tools like TypeScript, it was very complicated to understand the structure of this object, which had several nested properties, not all relevant, some with cryptic names and some that were assigned at later times from different parts of the code.
Having the simplicity to just share an object and mutate it freely was really helpful at the beginning but as the project grew it became very hard to manage. Eventually, I abandoned it, except for a small sprint a couple of months ago, whereby migrating the project to TypeScript I resolved the pain of not knowing the structure of the Metadata object and shed some light into some of the problems that made the project hard to maintain.
PureScript is immutable by default, which makes it a great fit to work with pure functions. Similar to the const keyword, once we set a value to an identifier, we can’t change it.
nine :: Int
nine = 9
-- Compiler error: The value nine has been defined multiple times
nine = 8
A nice side effect is that the syntax is clearer because we don’t need to distinguish between let and const. Even more, there is no syntax to change the value of a property once it’s defined. What we can do is create a new object from the old one, by simply defining the properties we want to change. This pattern is so common that there is a syntax feature called record updates to help us express this in a clean way.
type Request = { url :: String, verb :: String }
-- We define a full object
defaultReq :: Request
defaultReq = { url: "", verb: "GET"}
-- And then use it to create a new one, with a changed property
googleReq :: Request
googleReq = defaultReq { url = "http://www.google.com" }
-- { url: "http://www.google.com", verb: "GET" }
If we do want to work with mutable data, one option is to use the ST and STRef types. As the documentation states, these types allow us to create computations with local mutation, i.e. mutation which does not “escape” into the surrounding computation. We can compose and extend the computation and eventually run it in order to get a value. Once we run it, we lose the reference to the mutable data, hence the “safe mutation”.
The following is a contrived example to show how we can use those types to represent mutable data and their TypeScript counterpart. The mutable1 example creates a reference to a new mutable object with an initial value of 0, then reads that value into the val identifier and writes the result of the expression (val + 1) into the mutable object. The mutable2 example uses modify with an anonymous function to do the same in a more concise way. And mutable3 shows how we can use a loop function that plays nicely with mutations like for or while.

In the previous post, we mentioned the importance of a language that can grow by showing that JavaScript’s pipeline operator (which is still being debated in committee) is implemented in PureScript user-land by the applyFlipped function. The same happens with object mutation. In TypeScript, we need special language modifier such as Readonly, ReadonlyArray and as const, while in PureScript we use a normal user-land type (ST) that has a clever foreign function interface (FFI).
Before we explain how ST and STRef work, let’s introduce an example we’ll use in the final section and use it to explain some language features. The following is a naive implementation of the QSort algorithm using a recursive function and immutable arrays.

The first thing we need to do is to distinguish the base case from the recursion and separate the head and tail of the array. In TypeScript, we use an if statement for the first part and destructuring assignment for the second. In PureScript we use the uncons function, which returns a Maybe value to an object with the properties head and tail. Then with pattern matching, we can distinguish the base case from the recursion, and assign identifiers to the object properties.
For the second part, we need to calculate small, mid and large using the arrays native filter. In TypeScript we just add those definitions inside the function block and call the filter method on tail, passing an arrow function. In PureScript we need to use an expression, so instead of a block code, we have to use the let or where bindings. Then we call the filter function with an anonymous lambda and the tail. From an imperative or OOP perspective it would seem that the arguments are in reverse order, but as this Haskell article shows, it’s to allow better composition. Finally, in order to create the result array, we use the JavaScript’s spread operator in TS and the append method in PS.
We can only get so far in a statically typed language without introducing the notion of abstraction. The previous function only sorts numbers ascendingly, but we would like to sort anything in any order. To do so, we extract the compare function and leave it as a parameter that should be provided by the user. And to enforce type correctness we use generics in TypeScript, and parametric types in PureScript.

TypeScript defines generic types inside angle brackets just before the function parameters. Influenced by Java and .NET it is customed to use capital letters like T or at least words that start with an uppercase (even if it’s not required to)). PureScript, inspired by Haskell, uses the universal quantifier forall to declare the type parameters. The parameters are separated by space and have a dot to distinguish them from the rest of the definition. It is customed to use lowercase letters like a. You can use words, but unlike TS it has to start with a lowercase letter. PureScript supports unicode, so you can replace forall for its mathematical symbol ∀.
Notice that we don’t know anything about T or a, so we cannot do much with them, just pass them around. In this example, we are basically using them to make sure that the compare function receives two values of the same type as the array. In both languages, we have a way to add a restriction on the type, which gives us more power in what we can do with it, but that’s a concept for a different post.
Let’s analyze the mutable1 example to see how the types fit together. If we look at the documentation for new we can see the following signature, that we can split into four parts.
new :: forall a r. a -> ST r (STRef r a) -- 1) forall a r. -- 2) a -> -- 3) ST r (...) -- 4) (STRef r a)
First, the function defines two type parameters: a is the type of the mutable value, and r is a “phantom type” whose only purpose is to restrict the scope of the mutation. Then the function receives only one parameter, the initial value of type a. It returns a mutable computation ST r (...) that it’s bound to the phantom type. The computation is not to a value of type a, rather to a reference to the value (STRef r a), which is also bound by the phantom type.
The read function receives a reference to a value and returns a mutable computation to it.
read :: forall a r. STRef r a -> ST r a -- 1) forall a r. -- 2) STRef r a -> -- 3) ST r a
The write function receives two arguments: the value to write and where to write it. The function then returns a mutable computation of the written value so we don’t have to read it or compute it again.
write :: forall a r. a -> STRef r a -> ST r a -- 1) forall a r. -- 2) a -> -- 3) STRef r a -> -- 4) ST r a
We can glue these functions together in an “imperative way” using the do notation. This language feature allows us to work with types that have the shape M a, like Effect Unit, Array String, etc as long as the type M satisfies a certain restriction that we shall not name in this post. Just rest assured that these types and many others, meet this restriction. The do notation does something different depending on the underlying type. When used with Effect, we can call synchronous effectful computations one after the other. When used with Maybe, we can call different computations that may result in a value or may be empty and if one of them returns empty then the whole computation returns empty. When used with Array we can achieve array comprehensions and when used with ST then we can run different computations that mutate data.
Each expression inside do has to return the same M but can have different a types. Those different a can be bound to an identifier using identifier ← expression, except for the last expression which defines the type of the entire do expression.
foo :: M Int bar :: M String zoo :: Int -> String -> M Boolean what :: M Boolean what = do int <- foo str <- bar zoo int str
If we are working with Maybe String we could replace M with Maybe and a with String. Similarly, if we have Array Number we could say M = Array and a = Number, but what happens when we work with types that has multiple type parameters? If we have Either String Number then M = Either String and a = Number which means that all the expressions can succeed with different values (a) but if they fail, they fail with a String. If we have ST r Number then M = ST r and a = Number .
If we look back to the types of new, read and write, we can see that they all return an ST r something, so if we put it all together we can see the type of our do expression.
new :: forall a r. a -> ST r (STRef r a)
read :: forall a r. STRef r a -> ST r a
write :: forall a r. a -> STRef r a -> ST r a
myDoExpr :: forall r. ST r Int
myDoExpr = do
-- ref :: STRef r Int
ref <- Ref.new 0
-- val :: Int
val <- Ref.read ref
-- ST r Int
Ref.write (val + 1) ref
Finally, once we build up our computation, we can run it in order to get the value out.
run :: forall a. (forall r. ST r a) -> a myDoExpr :: forall r. ST r Int mutable1 :: Int mutable1 = run myDoExpr
Notice that the run function has a forall inside the first parameter, that feature, called Rank N types, is the one responsible to avoid leaking the mutation.
We could then ask the millenary question: If a value is mutated inside a function and no one from outside can mutate it, does it make a sound? I mean, is it still pure? I would say yes, and point out that even to resolve the simplest addition (1 + 1) the ALU needs to mutate internal registry, and no-one would question its purity.
In the section “representing abstraction” we examined a naive immutable implementation of the QSort algorithm. Now let’s see how a mutable version looks in both languages (implemented from this pseudo-code).
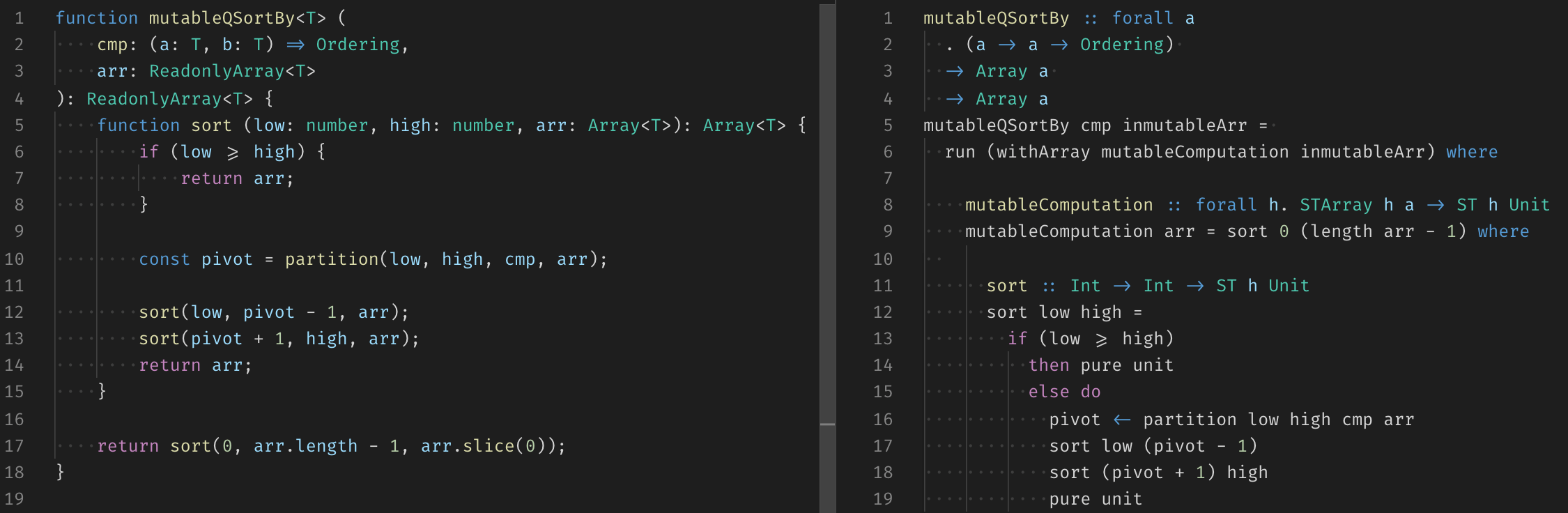
In the TypeScript version, we can notice that mutableQSortBy receives and returns a ReadonlyArray, but inside the body, the recursive function sort uses a normal mutable array. In line 17 we do the only copy, which we’ll sort in place and once it returns it’ll be marked as a ReadonlyArray to avoid further mutation. In PureScript we do a similar thing, in line 6 the withArray function executes a mutable computation on a copy of the immutable array, and that computation uses an inner recursive sort function that has in scope a reference to the mutable arr.
In both cases, the inner sort uses an auxiliary function called partition, which will pick a pivot and swap the lower elements to the left and the higher elements to the right. We can use the comments to see how different parts of the algorithm relates to each other.

In the swap function, the one that actually does the array mutation, PureScript knows that reading or writing a value with a random index can cause an out of bounds error. So we can use a safe peek that returns a Maybe to the value, or an unsafe peek that can cause a runtime exception. We use the later which is faster as we don’t need to wrap and unwrap the value, but it requires us to use unsafePartial to indicate that we know the risks.

In this post, we’ve seen how we can represent the same mutable and immutable algorithms in TypeScript and PureScript, and how the default of the language changes the ergonomics. Even if it is subjective, I’d say that mutable algorithms look more natural in TypeScript and immutable ones in PureScript.
Choosing whether to use mutation or not can depend on different factors, but personally, I try to avoid mutation and only use it when the convenience is greater than the risk. An interesting example to debate can be found in purescript-halogen-realworld, whereby using the Ref effect (similar to ST) in conjunction with the ReaderT type, the application handles the logged user in a sort of “controlled global variable”. Please comment and share if you find it useful.

LogRocket lets you replay user sessions, eliminating guesswork by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks, and with plugins to log additional context from Redux, Vuex, and @ngrx/store.
With Galileo AI, you can instantly identify and explain user struggles with automated monitoring of your entire product experience.
Modernize how you understand your web and mobile apps — start monitoring for free.
Debugging code is always a tedious task. But the more you understand your errors, the easier it is to fix them.
LogRocket allows you to understand these errors in new and unique ways. Our frontend monitoring solution tracks user engagement with your JavaScript frontends to give you the ability to see exactly what the user did that led to an error.
LogRocket records console logs, page load times, stack traces, slow network requests/responses with headers + bodies, browser metadata, and custom logs. Understanding the impact of your JavaScript code will never be easier!

Build a CRUD REST API with Node.js, Express, and PostgreSQL, then modernize it with ES modules, async/await, built-in Express middleware, and safer config handling.

Discover what’s new in The Replay, LogRocket’s newsletter for dev and engineering leaders, in the March 25th issue.

Discover a practical framework for redesigning your senior developer hiring process to screen for real diagnostic skill.

I tested the Speculation Rules API in a real project to see if it actually improves navigation speed. Here’s what worked, what didn’t, and where it’s worth using.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

