A knowledge gap pushes people toward over-engineering, and sooner or later, it shows up in performance.

Take content-visibility: auto. It does what React-Window does with zero JavaScript and zero bundle weight. Same story with the modern viewport units (dvh, svh, lvh). They solved the mobile height mess we’ve been patching with window.innerHeight has been hacked for years.
Both features cleared 90 percent global support in 2024. Both are ready for production today. Yet we keep defaulting to JavaScript because CSS evolved while we were all arguing about React Server Components.
This article closes that gap. We’ll look at benchmarks, show migration paths, and be honest about when JavaScript still wins. But before anything else, let’s state the obvious: if you’re reaching for useEffect and useState to fix a rendering issue, you’re probably barking up the wrong tree.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
React developers treat virtualization libraries like react-window and react-virtualized as the default fix for rendering lists. On paper, the logic is solid: if the user only sees 10 items at a time, why bother rendering all 1,000? Virtualization creates a small “window” of visible items and unmounts everything else as you scroll.
The issue isn’t that virtualization is wrong – it’s that we reach for it way too early and way too often. A product grid with 200 items? react-window. A blog feed with 50 posts? react-virtualized.
We’ve built a kind of cargo cult around list performance. Instead of checking whether the browser can handle the work natively, we jump straight into wrapping everything in useMemo and useCallback and call it “optimized.”
Here’s what a minimal react-virtualized setup actually looks like:
import { List } from 'react-virtualized';
import { memo, useCallback } from 'react';
const ProductCard = memo(({ product, style }) => {
return (
<div style={style} className="product-card">
<img src={product.image} alt={product.name} />
<h3>{product.name}</h3>
<p>{product.price}</p>
<p>{product.description}</p>
</div>
);
});
function ProductGrid({ products }) {
// Memoize the row renderer to prevent unnecessary re-renders
const rowRenderer = useCallback(
({ index, key, style }) => {
const product = products[index];
return <ProductCard key={key} product={product} style={style} />;
},
[products]
);
return (
<List
width={800}
height={600}
rowCount={products.length}
rowHeight={300}
rowRenderer={rowRenderer}
/>
);
}
This works fine. It’s roughly 50 lines of code, adds about 15KB to your bundle, and requires you to set up item heights and container dimensions. Pretty standard stuff.
But React developers rarely stop there. We’ve all been trained to chase re-render optimizations, so we start wrapping everything in memoization and callbacks:
import { List } from 'react-virtualized';
import { memo, useCallback, useMemo } from 'react';
const ProductCard = memo(({ product, style }) => {
return (
<div style={style} className="product-card">
<img src={product.image} alt={product.name} />
<h3>{product.name}</h3>
<p>{product.price}</p>
<p>{product.description}</p>
</div>
);
});
function ProductGrid({ products }) {
const rowCount = products.length;
// Memoize the row renderer to prevent unnecessary re-renders
const rowRenderer = useCallback(
({ index, key, style }) => {
const product = products[index];
return <ProductCard key={key} product={product} style={style} />;
},
[products]
);
// Memoize row height calculation
const rowHeight = useMemo(() => 300, []);
return (
<List
width={800}
height={600}
rowCount={rowCount}
rowHeight={rowHeight}
rowRenderer={rowRenderer}
/>
);
}
Look at that useMemo(() => 300, []). We’re memoizing a constant. We wrapped the component in memo() to avoid re-renders that probably weren’t happening in the first place. We tossed in useCallback for a function react-window already optimizes internally.
We’re doing all of this because we think we’re supposed to, not because we actually measured a problem. And while we were busy shaving off hypothetical re-renders, CSS quietly shipped a native solution.
It’s called content-visibility. It tells the browser to skip rendering off-screen content. Same idea as virtualization, except the browser handles it for you – no JavaScript, no scroll math, no item height configuration.
The question isn’t whether virtualization works. It does. The question is whether your list actually needs it. Most React apps deal with lists in the hundreds, not the tens of thousands. For those cases, content-visibility gets you about 90 percent of the benefit with a fraction of the complexity.
Here’s a quick overview of what content-visibility does. If you want the full deep dive, check out our guide.
The content-visibility property has three values: visible, hidden, and auto. Only auto matters for performance.
When you apply content-visibility: auto to an element, the browser skips layout, style, and paint work for that element until it’s close to the viewport. The keyword is “close” – the browser starts rendering a bit before the element enters view, so scrolling stays smooth. As soon as it moves out of view again, the browser pauses all that work.
The browser already knows what’s visible. It already has viewport intersection APIs. It already handles scroll performance. content-visibility: auto just gives it permission to skip rendering work.
Using the content-visibility with the same product grid, we will have this:
function ProductGrid({ products }) {
return (
<div className="product-grid">
{products.map(product => (
<div key={product.id} className="product-card">
<img src={product.image} alt={product.name} />
<h3>{product.name}</h3>
<p>{product.price}</p>
<p>{product.description}</p>
</div>
))}
</div>
);
}
CSS:
.product-card {
content-visibility: auto;
contain-intrinsic-size: 300px;
}
Two lines. The contain-intrinsic-size property tells the browser how much space to reserve for off-screen content. Without it, the browser assumes those elements have zero height, which throws off the scrollbar. With it, scrolling stays consistent because the browser has a rough idea of the element’s size even when it’s not rendered.
And this isn’t the only place where CSS quietly took over jobs we used to handle in JavaScript. Another big one: container-based responsive design.
Responsive design taught us to write media queries based on viewport width. Works fine until you put a component in a sidebar. Your card component needs different layouts depending on its container width, not the screen width. A 300px card in a sidebar should look different from a 300px card in the main content area, even though the viewport is the same.
Developers reached straight for JavaScript. We used ResizeObserver to track container widths, toggled classes at different breakpoints, and forced layout updates on every resize. Any component that needed container-aware styling ended up with JavaScript measuring its width and pushing the right styles onto it.
function updateCardLayout() {
const cards = document.querySelectorAll('.card');
cards.forEach(card => {
const width = card.offsetWidth;
if (width < 300) {
card.classList.add('card--small');
} else if (width < 500) {
card.classList.add('card--medium');
} else {
card.classList.add('card--large');
}
});
}
const resizeObserver = new ResizeObserver(updateCardLayout);
document.querySelectorAll('.card').forEach(card => {
resizeObserver.observe(card);
});
That’s 20+ lines of JavaScript to solve what should be a CSS problem. You’re measuring DOM elements, managing observers, adding event listeners, and maintaining class state. The browser already knows the container width. You’re asking for it in JavaScript instead of letting CSS handle it directly.
CSS container queries shipped in all major browsers in 2023. They let you write layout rules based on a parent container’s size, not the viewport.
.card-container {
container-type: inline-size;
}
@container (min-width: 300px) {
.card {
display: grid;
grid-template-columns: 1fr 2fr;
}
}
@container (min-width: 500px) {
.card {
grid-template-columns: 1fr 1fr;
}
}
Three declarations, the browser recalculates container queries the same way it recalculates media queries natively, without involving the main thread. Your card component responds to its container width automatically.
The container-type: inline-size property tells the browser this element is a container whose children might query its width. Then @container rules work like @media rules, except they check the container’s dimensions instead of the viewport’s.
Browser support is 90%+ as of 2025. Chrome 105+, Safari 16+, Firefox 110+. If you’re still writing resizeObserver code to handle component-based responsive design, you’re solving yet another problem CSS already solved.
Animations that fire when elements enter the viewport have always been a JavaScript job. You want something to fade in as the user scrolls, so you set up an IntersectionObserver, watch for visibility, add a class to trigger the CSS animation, and then unobserve the element to avoid leaks.
const observer = new IntersectionObserver((entries) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
entry.target.classList.add('fade-in');
observer.unobserve(entry.target);
}
});
});
document.querySelectorAll('.animate-on-scroll').forEach(el => {
observer.observe(el);
});
.fade-in {
animation: fadeIn 0.5s ease-in forwards;
}
@keyframes fadeIn {
from {
opacity: 0;
transform: translateY(20px);
}
to {
opacity: 1;
transform: translateY(0);
}
}
This works. It’s been the standard approach since IntersectionObserver shipped in 2019. Every parallax effect, fade-in card, and scroll-triggered animation uses this pattern.
The problem is you’re using JavaScript to tell CSS when to run an animation based on scroll position. The browser already tracks scroll position. It already knows when elements enter the viewport. You’re bridging two systems that should talk directly.
CSS scroll-driven animations let you tie animations directly to scroll progress like this:
@keyframes fade-in {
from {
opacity: 0;
transform: translateY(20px);
}
to {
opacity: 1;
transform: translateY(0);
}
}
.animate-on-scroll {
animation: fade-in linear both;
animation-timeline: view();
animation-range: entry 0% cover 30%;
}
The animation-timeline: view() property ties the animation progress to how much of the element is in view. The animation-range property controls when the animation starts and ends based on scroll position. The browser handles everything.
The animation runs on the compositor thread, not the main thread. IntersectionObserver callbacks run on the main thread. If your JavaScript is busy rendering React components or processing data, IntersectionObserver callbacks get delayed. Scroll-driven animations keep running smoothly because they’re not competing with JavaScript execution.
Browser support hit major milestones in 2024. Chrome 115+ (August 2023), Safari 18+ (September 2024). Firefox is implementing it behind a flag. You’re looking at 75%+ coverage now, which means you can use it with a progressive enhancement approach and have IntersectionObserver as a fallback for older browsers.
The real win is performance. Scroll-driven animations are declarative. You tell the browser what animation to run and when to run it. The browser optimizes the execution. With IntersectionObserver, you’re imperatively managing state, adding classes, and hoping you wrote efficient callback code.
CSS isn’t always the answer. There are unique cases where JavaScript is still the right tool, and pretending otherwise is dishonest.
You have truly infinite lists with 1000+ items. content-visibility loads all the data into the DOM even if it doesn’t render it. With 1000 items, that’s a memory problem. React-virtualized only creates DOM nodes for visible items, keeping memory usage low.
Your list has variable or unknown heights that change after render. content-visibility needs contain-intrinsic-size to work properly. If your items grow and shrink dynamically based on user interaction or loaded content, calculating intrinsic sizes becomes complicated. Virtualization libraries handle this with measurement APIs.
You need precise item tracking and scroll position control. If you’re building a data table where users can jump to row 5,000, or you need to restore exact scroll positions across page loads, virtualization gives you APIs for that. Content-visibility doesn’t expose that level of control.
You still need JavaScript when your logic depends on exact measurements. Container queries let CSS adapt based on size, but if your code needs to know whether a container is exactly 247px wide, you’re back to resizeObserver or getBoundingClientRect().
JavaScript also wins when the layout itself is too dynamic for CSS. If you’re building a dashboard with draggable panels, resizable columns, and layout rules driven by state and math, that’s squarely in JavaScript territory.
You need callbacks at specific animation points. Scroll-driven animations don’t fire events when they start or end. If your animation triggers data fetching or needs to update application state, IntersectionObserver or scroll event listeners are still necessary.
I’ll leave you with a simple decision framework for when to reach for CSS or JavaScript. Start by checking whether CSS can handle the problem outright. If it can, use CSS. If it can’t, see whether a progressive-enhancement approach works – modern CSS first, with a JavaScript fallback. If that covers your case, go with it. Only default to a JavaScript-first solution when CSS truly can’t do the job.
The point isn’t to avoid JavaScript. It’s to stop using JavaScript by reflex when CSS already gives you the answer. Most lists don’t have a thousand items. Most animations don’t need precise callbacks. Most components do perfectly well with container queries.
Figure out what your UI actually needs. Measure real performance. Then pick the simplest tool that solves the problem. More often than not, that’s CSS.
And if you’ve replaced a long-standing JavaScript workaround with a clean CSS solution, drop it in the comments.
As web frontends get increasingly complex, resource-greedy features demand more and more from the browser. If you’re interested in monitoring and tracking client-side CPU usage, memory usage, and more for all of your users in production, try LogRocket.
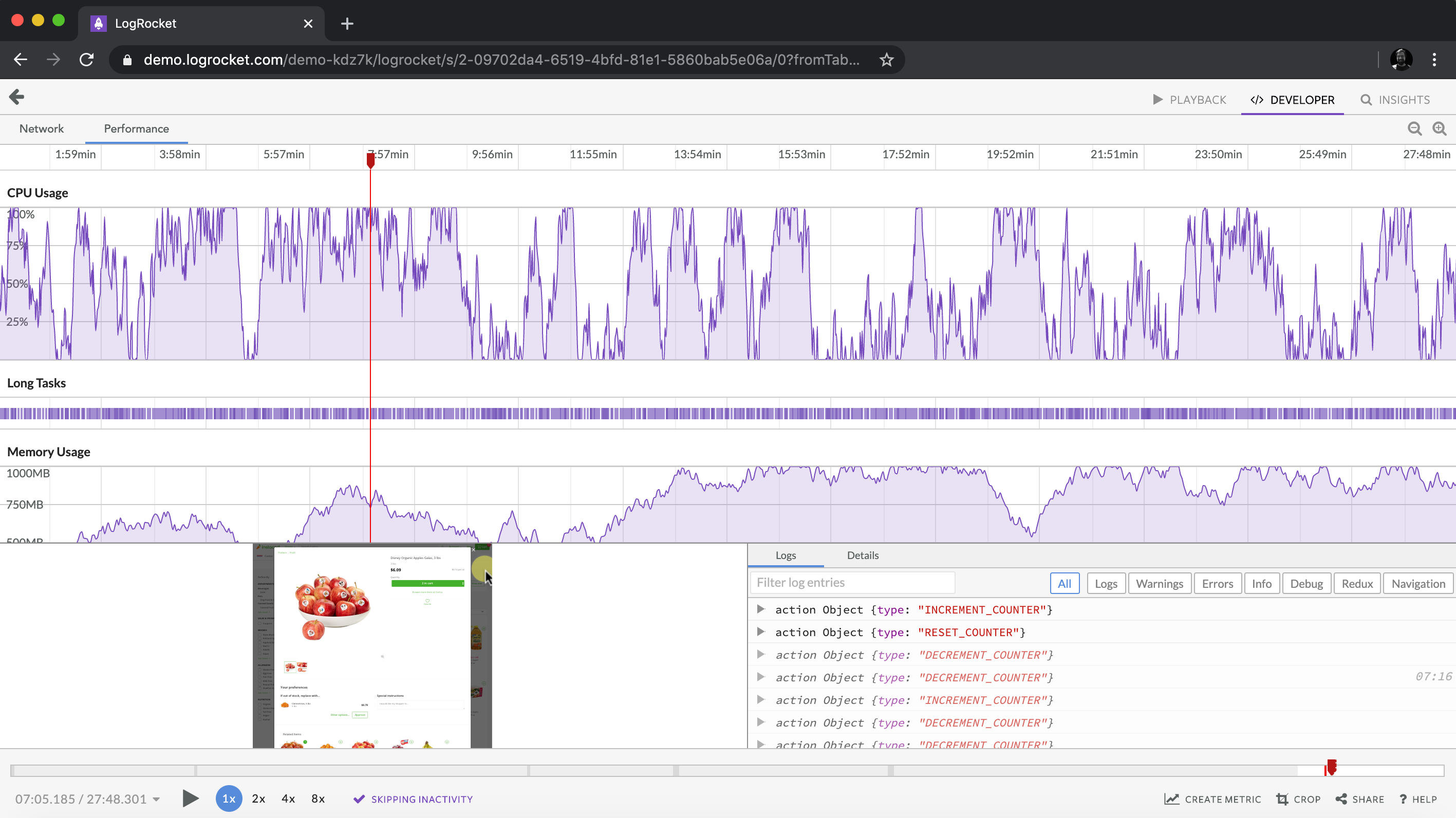
LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.
Modernize how you debug web and mobile apps — start monitoring for free.

Learn how inline props break React.memo, trigger unnecessary re-renders, and hurt React performance — plus how to fix them.

This article showcases a curated list of open source mobile applications for Flutter that will make your development learning journey faster.

Discover what’s new in The Replay, LogRocket’s newsletter for dev and engineering leaders, in the April 1st issue.

This post walks through a complete six-step image optimization strategy for React apps, demonstrating how the right combination of compression, CDN delivery, modern formats, and caching can slash LCP from 8.8 seconds to just 1.22 seconds.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

