Web applications often accept inputs from the users. In most cases, web applications request each user input separately. For example, a typical web application will ask you to enter your first name, last name, and email address during the registration process.

This form-filling mechanism came from the initial Web 2.0 phase. Now, for a better user experience, almost all applications are trying to reduce the number of mandatory user inputs. For example, some applications now only ask for your login email at the registration.
Some web applications do complex user input processing, such as analyzing a log file, accepting a text with custom grammar (e.g., hashtags, internal document identifiers, and user mentions), and domain-specific search queries. If the pattern matching requirement is simple, we can implement a solution using regular expressions. However, if we need to have an extendable solution, we have to implement our own parsers.
This tutorial will explain how you can create a parser to handle raw text inputs with the ANTLR toolkit. For demonstration, we will create a simple log parser application that will convert raw text to HTML-styled output.
Before beginning with ANTLR, we have to be familiar with the following principles of compiler design.
This is the initial generic step of the parsing process. This step accepts a raw text stream and produces a token stream. Tokens represent the smallest part of grammar. For example, the return word is a token in many programming languages.
A parse tree is a tree data structure instance that has information about parsed results. It contains tokens and complex parser nodes.
A typical compiler has three key modules: frontend, middle-end, and backend. The compiler frontend builds an internal representation of the source code by using the language syntax definition.
The compiler backend generates the targeted language code from the internal representation of the source code.
ANTLR (ANother Tool for Language Recognition) is a parser generator toolkit written in Java. ANLTR is widely used in the software development industry for developing programming languages, query languages, and pattern matching. It generates the parser code from its own grammar.
If we are going to implement a parser from scratch , we have to write code for tokenization and parser tree generation. ANTLR generates extendable parser code when the language specification is given. In other words, if we define rules explaining how we need to parse using ANTLR grammar syntax, it will automatically generate the source code of the parser.
ANTLR can generate parser code in 10 different programming languages. ANTLR is known as the JavaScript parser code and runtime.
In this tutorial, I will explain how to make a simple log parser using ANTLR.
Let’s name our log file syntax SimpleLog. Our log parser program accepts a raw log input. After that, it will produce an HTML table from the log file content. Meaning the SimpleLog translator has a compiler backend to generate an HTML table from the parse tree.
You can follow similar steps for making any complex input parser with JavaScript.
If you need to use ANTLR in the back end of your application, you can use the npm package with Node.
Otherwise, if you need to use ANTLR in the front end of your application, there are several ways. The most comfortable and easiest way is to bundle ANTLR runtime with your project source with webpack. In this tutorial, we will set up ANTLR with webpack.
First of all, we need to create the development environment for ANTLR. Make sure to install JRE (Java Runtime Environment) first. Create a directory and download the ANTLR parser generator CLI:
$ wget https://www.antlr.org/download/antlr-4.9.2-complete.jar
The above command is for Linux. Use an equivalent command to download the .jar file for other operating systems. Also, you can download the particular file manually with a web browser.
Create a new npm project with the npm init command. After that, add the following content to the package.json file:
{
"name": "log-parser",
"version": "1.0.0",
"scripts": {
"build": "webpack --mode=development",
"generate": "java -jar antlr-4.9.2-complete.jar SimpleLog.g4 -Dlanguage=JavaScript -o src/parser"
},
"dependencies": {
"antlr4": "^4.9.2",
},
"devDependencies": {
"@babel/core": "^7.13.16",
"@babel/plugin-proposal-class-properties": "^7.13.0",
"@babel/preset-env": "^7.13.15",
"babel-loader": "^8.2.2",
"webpack": "^4.46.0",
"webpack-cli": "^4.6.0"
}
}
Create webpack.config.js with the following content:
const path = require('path');
module.exports = {
entry: path.resolve(__dirname, './src/index.js'),
module: {
rules: [
{
test: /\.js$/,
exclude: /node_modules/,
use: {
loader: 'babel-loader',
options: {
presets: ['@babel/preset-env']
}
}
},
],
},
resolve: {
extensions: ['.js'],
fallback: { fs: false }
},
output: {
filename: 'logparser.js',
path: path.resolve(__dirname, 'static'),
library: 'LogParser',
libraryTarget: 'var'
}
};
We need to have a .babelrc as well, because ANTLR uses some latest ECMAScript features.
Therefore, add the following snippet to .babelrc:
{
"presets": [
"@babel/preset-env"
],
"plugins": [
[
"@babel/plugin-proposal-class-properties",
{
"loose": true
}
]
]
}
Make sure to enter npm install on your terminal to pull the required dependencies, including the ANTLR runtime library. Now our ANTLR environment has enough commands to generate parser code and build the final source code.
However, we are still missing one important piece. It’s the grammar for our log file format. Let’s go ahead and implement the ANTLR grammar.
Let’s assume that our log file follows the following format, and we need to parse it to identify the required information:
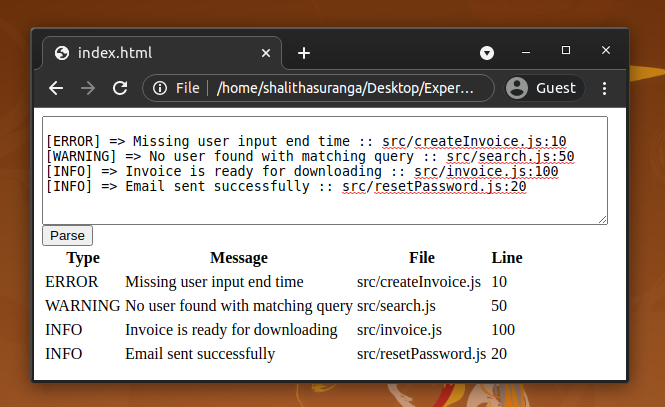
[ERROR] => Missing user input end time :: src/createInvoice.js:10 [WARNING] => No user found with matching query :: src/search.js:50 [INFO] => Invoice is ready for downloading :: src/invoice.js:100 [INFO] => Email sent successfully :: src/resetPassword.js:20
The above log file lines have three log levels: ERROR, WARNING, and INFO. After that, there is a message. Finally, we have the code module and line number where the logging process is triggered.
Before writing the ANTLR grammar for the above log file syntax, we need to identify tokens. The SimpleLog grammar has three key tokens, as shown below:
ERROR, WARNING, and INFO)Datetime, Message, and Module)Now, we have an idea about lexer rules. Let’s write ANTLR grammar by using the above tokens and some parser tree generation rules. When you are writing the grammar, you can follow the bottom-up approach. In other words, you can start with tokens and finish with parser rules. Add the following grammar logic to SimpleLog.g4:
grammar SimpleLog; logEntry : logLine+; logLine : '[' logType ']' ' => ' logMessage ' :: ' logSender; logType : (INFO | WARNING | ERROR); logMessage : TEXT+?; logSender : logFile ':' DIGITS; logFile : TEXT+?; INFO : 'INFO'; WARNING : 'WARNING'; ERROR : 'ERROR'; TEXT : [a-zA-Z ./]+?; DIGITS : [0-9]+; WS : [ \n\t]+ -> skip;
Camelcase words represent parser rules in the above SimpleLang grammar file. These parser rules help to build a parse tree by using tokens. At the very top, our parse tree has an entry to a line. After that, each line node has logType, logMessage, and logSender nodes.
The uppercase definitions are lexer rules. These lexer rules help with the tokenization process. A raw input from the user will be tokenized using those tokes such as text fragment, digits, and log type.
Run the following command on your terminal from your project directory to trigger the parser code generation:
$ npm run generate
If you make the grammar file correctly, you will be able to see the auto-generated parser code inside the src/parser directory. Let’s implement the SimpleLog translator program’s backend.
The ANTLR parsing process will generate an in-memory parse tree. It also provides a listener class to traverse on the parse tree. We need to create a tree visitor to go through the parse tree and produce the output HTML table structure. In compiler theory, this is known as the code generation process.
Add the following code into src/TableGenerator.js:
import SimpleLogListener from "./parser/SimpleLogListener"
export default class TableGenerator extends SimpleLogListener {
tableSource = "";
exitLogLine(ctx) {
const logType = ctx.logType().getText();
const logMessage = ctx.logMessage().getText();
const logFile = ctx.logSender().logFile().getText();
const logLine = ctx.logSender().DIGITS(0).getText();
this.tableSource +=
`
<tr>
<td>${logType}</td>
<td>${logMessage}</td>
<td>${logFile}</td>
<td>${logLine}</td>
<tr>
`
}
getTable() {
const table = `
<table>
<thead>
<th>Type</th>
<th>Message</th>
<th>File</th>
<th>Line</th>
<thead>
${this.tableSource}
</table>
`;
return table;
}
}
The above class extends the auto-generated base listener class. The base listener class has all tree walking related methods. In our scenario, we override only the exitLogLine method for simplicity. We can obtain log type, message, file, and line number from the exitLogLine method. The code writing process is known as emitting. Here we are emitting HTML table syntax from the tree walker class.
We are preparing a client library with webpack because we need to use the parser logic directly in the browser. Now we need a public entry point for our library. Let’s expose LogParser.parse() method to the browser.
Add the following code to src/index.js which is our entry point of the parser library:
import antlr4 from 'antlr4';
import SimpleLogLexer from './parser/SimpleLogLexer';
import SimpleLogParser from './parser/SimpleLogParser';
import TableGenerator from './TableGenerator';
export let parse = (input) => {
const chars = new antlr4.InputStream(input);
const lexer = new SimpleLogLexer(chars);
const tokens = new antlr4.CommonTokenStream(lexer);
const parser = new SimpleLogParser(tokens);
parser.buildParseTrees = true;
const tree = parser.logEntry();
const tableGenerator = new TableGenerator();
antlr4.tree.ParseTreeWalker.DEFAULT.walk(tableGenerator, tree);
return tableGenerator.getTable();
}
The parse method accepts a raw input and returns the HTML table structure accordingly. Now, our parser library is complete.
Execute the following command on your terminal to make a single JavaScript source file from the source code:
$ npm run build
The resultant JavaScript file will be saved into static/logparser.js.
Finally, we can implement the Graphical User Interface (GUI) of our SimpleLog parser program.
Our web application has three major components: the text area, the parse button, and the results area. I built a simple interface using plain HTML and vanilla JavaScript for this example program.
Add the following HTML and JavaScript codes into static/index.html file:
<script src="logparser.js"></script>
<textarea id="rawText"></textarea>
<button onclick="generateTable();">Parse</button>
<div id="tableWrapper"></div>
<script>
function generateTable() {
const textarea = document.getElementById("rawText");
const tableWrapper = document.getElementById("tableWrapper");
tableWrapper.innerHTML = LogParser.parse(textarea.value);
}
</script>
Congratulations! our SimpleLog parser web application is now ready. The web application can be launched either via a static file server or by just double-clicking on the HTML file. Try to copy-paste a sample input. After that, click on the Parse button to get an HTML version of the raw text.
Full project source code is available on GitHub.
We can also use ANTLR for parsing raw text inputs from users. There are various sorts of use cases of ANTLR. This tutorial explained one simple example. The same approach can be used to make web transpilers, advanced web scraping, complex pattern matching, and web-based query languages to build next-level web applications.
Are you trying to build a custom query language for your web application? Try ANTLR.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now
Get to know RxJS features, benefits, and more to help you understand what it is, how it works, and why you should use it.

Explore how to effectively break down a monolithic application into microservices using feature flags and Flagsmith.

Native dialog and popover elements have their own well-defined roles in modern-day frontend web development. Dialog elements are known to […]

LlamaIndex provides tools for ingesting, processing, and implementing complex query workflows that combine data access with LLM prompting.


