Parsing PDF files is essential in various applications, particularly those involved with document processing and data extraction. There are a plethora of online tools available for PDF parsing. As such, the decision on which package to use can be a daunting task.

This article will provide a comprehensive guide for how to navigate PDF parsing in Node.js, delving into the integration of Node packages like pdf-parse and pdf-reader. We’ll highlight the unique benefits, usage, and challenges each package presents. We’ll also explore why developers might prefer to construct custom parsers, tailoring solutions to fit the needs of their projects.
Let’s begin!
To start, we’ll create a simple Node.js application. Head over to the terminal and run the following command:
npm init -y
Next, create a folder called uploads, which will be used to store the sample PDF files used to test the packages.
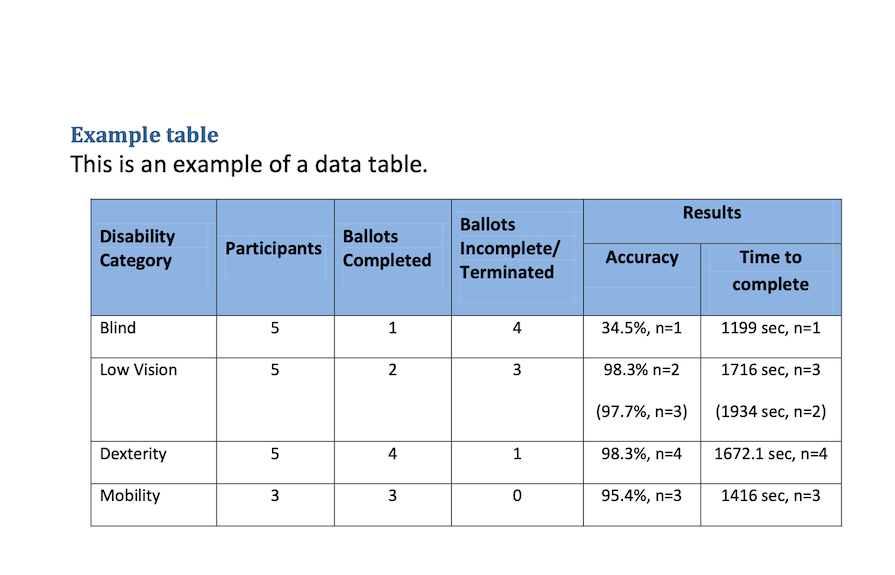
Two PDF files are used for testing. One contains only a page of text contents and can be found in uploads/test.pdf. The second file contains text with a table in it and can be found in uploads/table.pdf.
Here is what the test.pdf file looks like:

And here is what the table.pdf file looks like:
Let’s explore some of the most popular open source Node packages for parsing files.
pdf-parse is a popular parsing package among developers for its user-friendly interface. Its stability stems from its independence from other parser frameworks, which contributes to fewer bugs.
To install pdf-parse, run the following command:
npm i pdf-parse
Next, create a file named pdf-parse.mjs in the project root and add the following:
import pdf from "pdf-parse-debugging-disabled";
const data = await pdf("./uploads/test.pdf");
console.log(data)
This is a basic setup to demonstrate how to integrate pdf-parse into your workflow. Simply calling the pdf() method on line three and passing the path to the PDF is all that’s needed to process the file contents of the file.
The sample result looks like this:
{
numpages: 1,
numrender: 1,
info: {
PDFFormatVersion: '1.4',
IsAcroFormPresent: false,
IsXFAPresent: false,
Title: 'Test',
Producer: 'Skia/PDF m123 Google Docs Renderer'
},
metadata: null,
text: '\n\nTypescript,Serverless.',
version: '1.10.100'
}
The numpages property shows the number of pages in the PDF. In our example, it is one page. text contains the contents of the PDF. info contains more information about the document, such as its title, the PDF format version, and how the PDF was produced. Finally, metadata contains the PDF’s metadata.
Now, let’s take a look at an example of a PDF file that has a table:
import pdf from "pdf-parse-debugging-disabled";
const data = await pdf("./uploads/table.pdf");
console.log(data)
The resulting payload looks like this:
{
numpages: 1,
numrender: 1,
info: {
PDFFormatVersion: '1.6',
IsAcroFormPresent: false,
IsXFAPresent: false,
Author: 'Mary',
Creator: 'Acrobat PDFMaker 9.0 for Word',
Producer: 'Adobe PDF Library 9.0',
CreationDate: "D:20110123144232-05'00'",
ModDate: "D:20140304212414-05'00'"
},
metadata: Metadata {
_metadata: [Object: null prototype] {
'xmp:modifydate': '2014-03-04T21:24:14-05:00',
'xmp:createdate': '2011-01-23T14:42:32-05:00',
'xmp:metadatadate': '2014-03-04T21:24:14-05:00',
'xmp:creatortool': 'Acrobat PDFMaker 9.0 for Word',
'xmpmm:documentid': 'uuid:4a18570c-d5bf-445d-9e0e-2efeb989eeb1',
'xmpmm:instanceid': 'uuid:813474a4-22b0-4180-9415-bb67674d2b7b',
'xmpmm:subject': '3',
'dc:format': 'application/pdf',
'dc:creator': 'Mary',
'pdf:producer': 'Adobe PDF Library 9.0',
'pdfx:sourcemodified': 'D:20110123172633'
}
},
text: '\n' +
'\n' +
'Example table \n' +
'This is an example of a data table. \n' +
'Disability \n' +
'Accuracy Time to \n' +
'complete \n' +
'Blind 5 1 4 34.5%, n=1 1199 sec, n=1 \n' +
'Low Vision 5 2 3 98.3% n=2 \n' +
'(97.7%, n=3) \n' +
'1716 sec, n=3 \n' +
'(1934 sec, n=2) \n' +
'Dexterity 5 4 1 98.3%, n=4 1672.1 sec, n=4 \n' +
'Mobility 3 3 0 95.4%, n=3 1416 sec, n=3 \n' +
' ',
version: '1.10.100'
}
As we can observe, pdf-parse doesn’t preserve the table structure. Instead, it treats it all as a line. The pdf-parse package is useful if you only intend on extracting text from the PDF and aren’t worried about the file’s structure.
pdf2json is a module that transforms PDF files from binary to JSON format, using pdf.js for its core functionality. It also incorporates support for interactive form elements, enhancing its utility in processing and interpreting PDF content.
To install pdf2json, run the following command:
npm i pdf2json
Next, create a file called pdf2json.mjs in the root folder of the project and insert the following:
import fs from "fs";
import PDFParser from "pdf2json";
const pdfParser = new PDFParser(this, 1);
const filename = "./uploads/table.pdf";
pdfParser.on("pdfParser_dataError", (errData) =>
console.error(errData.parserError)
);
pdfParser.on("pdfParser_dataReady", (pdfData) => {
console.log(pdfData);
});
pdfParser.loadPDF(filename);
This is a basic setup to show how to integrate this package into your workflow. on("pdfParser_dataReady") is called when the parser is finished processing the PDF contents.
The sample result looks like this:
{
Transcoder: '[email protected] [https://github.com/modesty/pdf2json]',
Meta: {
PDFFormatVersion: '1.6',
IsAcroFormPresent: false,
IsXFAPresent: false,
Author: 'Mary',
Creator: 'Acrobat PDFMaker 9.0 for Word',
Producer: 'Adobe PDF Library 9.0',
CreationDate: "D:20110123144232-05'00'",
ModDate: "D:20140304212414-05'00'",
Metadata: {
'xmp:modifydate': '2014-03-04T21:24:14-05:00',
'xmp:createdate': '2011-01-23T14:42:32-05:00',
'xmp:metadatadate': '2014-03-04T21:24:14-05:00',
'xmp:creatortool': 'Acrobat PDFMaker 9.0 for Word',
'xmpmm:documentid': 'uuid:4a18570c-d5bf-445d-9e0e-2efeb989eeb1',
'xmpmm:instanceid': 'uuid:813474a4-22b0-4180-9415-bb67674d2b7b',
'xmpmm:subject': '3',
'dc:format': 'application/pdf',
'dc:creator': 'Mary',
'pdf:producer': 'Adobe PDF Library 9.0',
'pdfx:sourcemodified': 'D:20110123172633'
}
},
Pages: [
{
Width: 38.25,
Height: 49.5,
HLines: [],
VLines: [],
Fills: [Array],
Texts: [Array],
Fields: [],
Boxsets: []
}
]
}
The Pages property contains the contents of the PDF, while Meta contains the PDF metadata.
To get the raw contents of the file, replace the pdfParser_dataReady listener with this:
pdfParser.on("pdfParser_dataReady", (pdfData) => {
console.log({ textContent: pdfParser.getRawTextContent() });
});
Here’s the output:
{
textContent: 'Typescript,Serverless.\r\n----------------Page (0) Break----------------\r\n'
}
Next, let’s update the sample PDF to one that has a table in it.
Replace the above code with the following:
import fs from "fs";
import PDFParser from "pdf2json";
const pdfParser = new PDFParser(this, 1);
const filename = "./uploads/table.pdf";
pdfParser.on("pdfParser_dataError", (errData) =>
console.error(errData.parserError)
);
pdfParser.on("pdfParser_dataReady", (pdfData) => {
console.log({ textContent: pdfParser.getRawTextContent() });
});
pdfParser.loadPDF(filename);
Here’s the output data in the console:
{
textContent: 'Example table \r\n' +
'This is an example of a data table. \r\n' +
'Disability \r\n' +
'Category Participants \r\n' +
'Ballots \r\n' +
'Completed \r\n' +
'Ballots \r\n' +
'Incomplete/ \r\n' +
'Terminated \r\n' +
'Results \r\n' +
'Accuracy Time to \r\n' +
'complete \r\n' +
'Blind 5 1 4 34.5%, n=1 1199 sec, n=1 \r\n' +
'Low Vision 5 2 3 98.3% n=2 \r\n' +
'(97.7%, n=3) \r\n' +
'1716 sec, n=3 \r\n' +
'(1934 sec, n=2) \r\n' +
'Dexterity 5 4 1 98.3%, n=4 1672.1 sec, n=4 \r\n' +
'Mobility 3 3 0 95.4%, n=3 1416 sec, n=3 \r\n' +
' \r\n' +
'----------------Page (0) Break----------------\r\n'
}
Using pdf2json, there is no significant difference between a PDF with tables and one without.
pdfreader is another tool that converts PDFs from binary to JSON format. Underneath, it uses pdf2json. Unlike the packages we have seen so far, which don’t support tabular data, this package does so with automatic column detection and rule-based parsing.
To install pdfreader, run the following command:
npm install pdfreader
Next, create a file called pdfreader.mjs in the root folder of the project and insert the following:
import { PdfReader } from "pdfreader";
const filename = "./uploads/test.pdf";
var rows = {}; // indexed by y-position
function printRows() {
Object.keys(rows) // => array of y-positions (type: float)
.sort((y1, y2) => parseFloat(y1) - parseFloat(y2)) // sort float positions
.forEach((y) => console.log((rows[y] || []).join("")));
}
new PdfReader().parseFileItems(filename, function (err, item) {
if (!item || item.page) {
// end of file, or page
printRows();
item?.page && console.log("PAGE:", item.page);
rows = {}; // clear rows for next page
} else if (item.text) {
// accumulate text items into rows object, per line
(rows[item.y] = rows[item.y] || []).push(item.text);
}
});
The parseFileItems method returns a callback that contains the processed file. In this code example above, we assign this file to a variable called item on line nine.
An item object can match one of the following objects:
null: This means that parsing is over or an error has occurred{file:{path:string}}. This occurs when a PDF file is being opened, and is always the first item{page:integer, width:float, height:float}. This represents that a new page is being parsed. It provides the page number starting at index 1{text:string, x:float, y:float, w:float, ...}. This contains the text property and floating 2D AABB coordinates on the pageThe result looks like this:
PAGE: 1 Typescript,Serverless.
Next, we’ll replace the PDF we used above with a PDF file that includes a table.
Replace the above code with the following:
import { PdfReader, TableParser } from "pdfreader";
const filename = "./uploads/table.pdf";
const nbCols = 2;
const cellPadding = 40;
const columnQuantitizer = (item) => parseFloat(item.x) >= 20;
// polyfill for String.prototype.padEnd()
// https://github.com/uxitten/polyfill/blob/master/string.polyfill.js
// https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/repeat
if (!String.prototype.padEnd) {
String.prototype.padEnd = function padEnd(targetLength, padString) {
targetLength = targetLength >> 0; //floor if number or convert non-number to 0;
padString = String(padString || " ");
if (this.length > targetLength) {
return String(this);
} else {
targetLength = targetLength - this.length;
if (targetLength > padString.length) {
padString += padString.repeat(targetLength / padString.length); //append to original to ensure we are longer than needed
}
return String(this) + padString.slice(0, targetLength);
}
};
}
const padColumns = (array, nb) =>
Array.apply(null, { length: nb }).map((val, i) => array[i] || []);
const mergeCells = (cells) => (cells || []).map((cell) => cell.text).join("");
const formatMergedCell = (mergedCell) =>
mergedCell.substr(0, cellPadding).padEnd(cellPadding, " ");
const renderMatrix = (matrix) =>
(matrix || [])
.map(
(row, y) =>
"| " +
padColumns(row, nbCols)
.map(mergeCells)
.map(formatMergedCell)
.join(" | ") +
" |"
)
.join("\n");
var table = new TableParser();
new PdfReader().parseFileItems(filename, function (err, item) {
if (err) console.error(err);
else if (!item || item.page) {
// end of file, or page
console.log(renderMatrix(table.getMatrix()));
item?.page && console.log("PAGE:", item.page);
table = new TableParser(); // new/clear table for next page
} else if (item.text) {
// accumulate text items into rows object, per line
table.processItem(item, columnQuantitizer(item));
}
});
Looking at the logged data in the console, this is what we see:
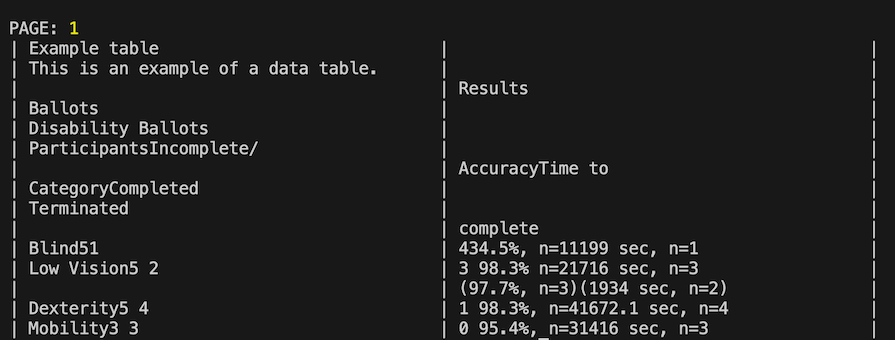
pdfreader differentiates from the other parsers we covered above by its ability to preserve table structures. While it may not achieve perfect accuracy, as we can see in the image above, it offers a more effective solution for handling complex document layouts.
Each package we covered above has its strengths and drawbacks. Let’s compare their aspects side by side so you can easily determine the most suitable choice for your project:
| Package | Functionality | Compatibility |
|---|---|---|
| pdf-parse | Enables reading from a specified file path (supports both local and external sources) and from a memory buffer | Node v14 and above |
| pdfreader | Supports password-protected files, file path and file buffer, PDFs with tables, and CLI usage | Node v14 and above. Depends on pdf2json |
| pdf2json | Facilitates reading from a file path or memory buffer, along with command-line interface capabilities | Node v14 and above. Depends on pdf.js |
Often, project requirements might call for something beyond what most packages can provide, hence the need to innovate and build a custom parser.
One example we discussed in this article is the necessity for applications to accurately parse tables within PDFs. Given that the evaluated packages fall short in this area, it might become essential to develop a custom parser for your project. Ideally, this parser would be constructed using an existing open source parser as a foundation to ensure precise table replication.
In this tutorial, we explored how to parse PDF files in Node.js using multiple npm packages. We further expanded our knowledge by comparing the packages and exploring the challenges they encounter. You could also further expand your understanding by modifying the sample codes provided to discover new applications for these packages.
Hopefully, you enjoyed this article and have learned a new way of processing your PDF file contents. Thanks for reading!
 Monitor failed and slow network requests in production
Monitor failed and slow network requests in productionDeploying a Node-based web app or website is the easy part. Making sure your Node instance continues to serve resources to your app is where things get tougher. If you’re interested in ensuring requests to the backend or third-party services are successful, try LogRocket.

LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.

AI tools generate working React code fast, but miss race conditions, empty states, debouncing, and accessibility. Here’s how to catch bugs before production.

Learn how to use Gemini CLI subagents to delegate frontend, backend, testing, and docs tasks to specialized agents with guardrails and clear ownership.

Learn how next-browser gives AI agents runtime context for debugging Next.js apps, including React props, hydration, PPR, forms, and performance.

Build dynamic LLM routing in Next.js with OpenRouter, TanStack AI, task classification, model fallbacks, and cost-aware routing.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

