Editor’s note: This post was updated on 3 March 2023 to provide more detailed information about column-oriented databases, column families, and use case cases for NoSQL database management systems.

Many people believe NoSQL to be ancient technology. In the world of databases, however, NoSQL is considered a baby — even though it’s been around since the early ’70s. How’s that possible?
Well, NoSQL wasn’t really popular until the late 2000s, when both Google and Amazon put a lot of research and resources into it. Since then, its popularity and usefulness have grown exponentially, to the point where almost every big website and company utilizes NoSQL in some way.
Another common misconception is that NoSQL can be better or worse than its semantic counterpart, SQL. On the contrary, both of these database types are suited for different types of data and thus will never replace or outshine each other.
Without going into too much detail, SQL databases have a predefined schema, while NoSQL databases are dynamic and perfect for unstructured data. NoSQL databases can use a schema, although it’s not mandatory.
With that in mind, today, we’ll have a look at one of the less complex NoSQL database management systems: wide-column stores. This NoSQL model stores data in columns rather than rows. Thus, it’s perfect for queries and less than optimal for large sets of data.
We’ll also investigate the difference between column families and wide-column stores, discuss the pros and cons of different columnar relational models, and look at some real-life use cases for NoSQL database management systems.
Jump ahead:
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Let’s take a look at the four main NoSQL database management systems. This will help us get a better idea of why column families are so popular:
keyvaluestores: The simplest type are key-value stores. Redis is one example; every single item is given an attribute name/key and valuedocumentdatabases: Document databases, such as MongoDB, associate keys with a complex data schema known as a document. Nested documents and key-array/value pairs are containable inside each documentgraphdatabases: Graph databases, like Neo4j, sort network information such as social connections. The collection of nodes (or vertices, i.e., a thing, place, person, category, and so on), each reflecting data (properties), are given labels (edges) establishing the relationship between different nodesWe’ll explore the wide-column store database type in more detail, but first let’s take a closer look at column-oriented databases.
Column-oriented, or columnar, databases use the typical tables, columns, and rows. But unlike relational databases (RDBs), columnal formatting and names can vary from row to row inside the same table. Also, each column of a column-oriented database is stored separately on-disk.
Columnar databases store each column in a separate file. Consider the example below: one file stores only the key column, another only the first name, another the Zip code, and so on. Each column in a row is governed by auto-indexing. Each column functions almost as an index, meaning a scanned/queried column offset corresponds to the other columnal offsets in that row in their respective files.

Traditional row-oriented storage performs best when querying multiple columns of a single row. Of course, relational databases are structured around columns that hold very specific information, upholding that specificity for each entry. For instance, let’s take a customer table. Column values contain customer names, addresses, and contact info. Every customer has the same format.
Columnar families are different. They provide automatic vertical partitioning; storage is both column-based and organized by less restrictive attributes. RDB tables are also restricted to row-based storage and deal with tuple storage in rows, accounting for all attributes before moving forward. For example, tuple 1 attribute 1, tuple 1 attribute 2, and so on — then tuple 2 attribute 1, tuple 2 attribute 2, and so on — in that order. The opposite is columnar storage, which is why we use the term column families.
N.B., some columnar systems also have the option for horizontal partitions at a default of, say, 6 million rows. When it’s time to run a scan, this eliminates the need to partition the query.
When choosing a columnar system, selecting one that allows you to set the system to sort its horizontal partitions at default based on the most commonly used columns will minimize the number of extents containing the values you are looking for.
There are two main columnar family types:
columnarrelationalmodels: Columnar-type storage can integrate columnar relational models even though they are also considered a part of NoSQLkeyvaluestores: Key-value stores and/or BigtablesTo better understand wide-column stores, let’s explore the concept of a “column family.” Column families aren’t the same as wide-column stores. Instead, wide-column stores consist of column families. A family, or database object, contains columns of related information. The object is a tuple of a key-value pair where the key is linked to a value, and the value is a set of columns. A family can be one attribute or a set of related attributes.
Wide-column stores are column-oriented databases that use column families and are one of the types of NoSQL databases. This sort of database is built to store large amounts of data and is highly scalable.
Most often, the definitions of wide-column stores are incorrectly interchanged with columnar datastores. The major difference is that wide-column supports a column family stored together on-disk while columnar stores each column separately.
The diagram below illustrates how wide-column stores work:
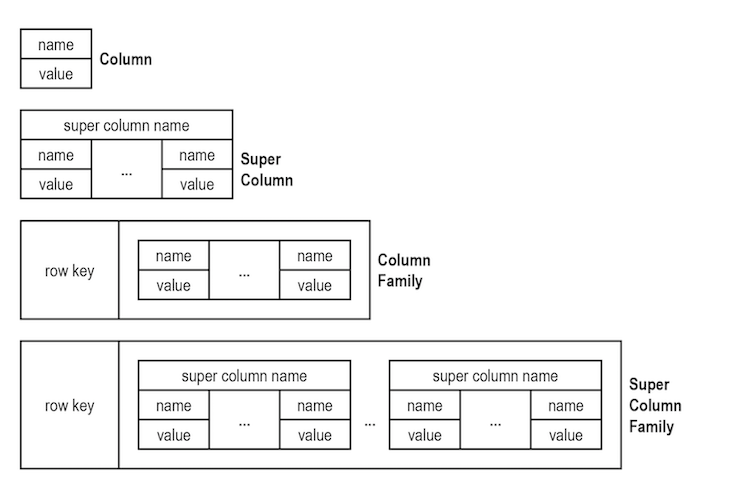
The first column model is an entity/attribute/value table. Inside each entity (column), there is a value/attribute table. For customer data, you might have the following for the first column option:
| Customer ID | Attribute | Value |
| 0001 | name | Jane Doe |
| 0001 | phone number 1 | 100200300 |
| 0001 | [email protected] |
Compared to RDBs, attribute/value tables shine when entering the more unique attributes:
| Customer ID | —————– | 0001 |
| 0001 | pet peeve | —————– |
| hobby | pop music | |
| Attribute | sewing | |
| —————– | Value |
Super columns hold the same information but formatted differently:
| Customer ID: 0001 | |
| Attribute | Value |
| —————– | —————– |
| pet peeve | pop music |
| hobby | sewing |
A super column family and super column merely add a row ID for the first two models so the data can be obtained faster. Use as many super column models as entities. Have them in individual NoSQL tables or compiled as a super column family.
Columnar relational models allow for improved compression of attributes when stored in an attribute-wise manner. All of the data in each file is of the same data file.
Let’s say you have a few dozen entries that share the same attribute. You could select all tuples through that attribute, then filter it further using an ID range (for example, only tuples with IDs 230 to 910). This compression requires less storage and — more impressively — quicker querying.
As an example, say you were looking for a collection of tuples with a value greater than x. Rather than running the search through all tuples and gathering tuples with a value over x, you simply target the value and skip over any tuples that do not qualify; as such, fewer disk blocks/bytes are checked. Generally, querying is faster if only one attribute is queried.
Each attribute is stored separately into blocks, resulting in a much greater ratio of tuples and attributes that can be searched per disk block search. The decision-making process is quicker. Another related advantage of the columnar relational model is faster joins.
It’s also much easier to add new columns each time you derive new attributes to add to your database. Rather than needing to rebuild enormous tables, columnar databases simply create another file for the new column.
As far as disadvantages go, updates can be inefficient. For example, say you want to update a specific tuple for multiple attributes. RDB models can do this faster. The fact that columnar families group attributes, as opposed to rows of tuples, works against it; it takes more blocks to update multiple attributes than RDBs would need in this case.
If multiple attributes are touched by a join or query, this may also lead to column storage experiencing slower performance (but other factors come into play as well). It’s also slower when deleting rows from columnar systems, as a record needs to be deleted from each of the record files.
Overall, columnar families work well for OLAP (Online Analytical Processing) but not well for OLTP (Online Transactional Processing). Let’s explore OLTP vs. OLAP scenarios in a bit more detail below.
Typically, in this instance, single updates are being done on a very small part of the database, such as one or a few account tuples. Nevertheless, they will need to deal with multiple attributes, which will give RDBs an advantage in speed.
John Smith calls customer services, and you can pinpoint his information through his customer ID or phone number. While the phone number might not be unique, it will narrow down which accounts to select from. This is a transactional scenario rather than an analytical one.
So columnar databases are preferable for OLTP systems? Wrong — you should not attempt to do OLTP-type (single-row operation) transactions on columnar databases. When this process is carried out via a row-oriented system, it simply adds a new entry (row) to the end of your table (the last page).
In contrast, columnar systems need to add/append new values to each respective file. The greater the number of rows you have in your database, the more of a killer this will be on performance (don’t do this: batch inserts are a possible fix for inserting lots of data quickly).
Typically, if you’re doing queries that look for metadata insights, such as averages of all account values (sum) across the table, columnar databases can access the specific column much faster, and do aggregations and summaries much faster, than our RDB models.
Perhaps you want to know the average age of your male customers. This will typically result in a sequential scan, which is a performance killer. Let’s say you have 100 million rows of entries with 100 columns each. Either you will need to create composite indexes on sex or read all entries to filter for the target data, which could be gigabytes’ or terabytes’ worth of work.
Rather than reading countless rows/columns of tuples — containing tons of data — columnar systems let you narrow down the tuples that you need to investigate by scanning only the two or three columns actually relevant to your query.
Before we conclude, let’s explore some real-world use cases of NoSQL DBMSs.
Customers expect businesses to provide a consistent and reliable online experience at all times. Another important factor in retaining and attracting customers is a company’s ability to provide a personalized experience.
Let’s say your company has 10 million+ customers across different continents with billions of data points. To provide a great customer experience, your database system need have to:
A NoSQL DBMS, like Apache Cassandra — which is a wide-column database, is an excellent option for this use case.
Content management systems (CMS) store and serve information assets and associated metadata to a website. Content can include text, images, and rich data types such as tweets, gifs, memes, etc. Traditionally, a relational database like MySQL is the data model used by most content management systems. However, this choice of DBMS will incur performance costs as the data grows.
Since the data is organized in tables, a lot of complex de-normalization has to be done in order to avoid data duplication. Content is document-based, not relation-based. One type of NoSQL DBMS is a document database. More precisely, in a JSON document store-based NoSQL database, records (content) are stored as documents.
A document-based NoSQL DBMS, like MongoDB, provides a rich query language that makes storing and searching different content types with different attributes in a single place easy.
Other use cases include:
Wide-column store databases provide improved automation with regard to vertical partitioning (filtering out irrelevant columns in your queries — ideal for analytical queries), horizontal partitioning (improving efficiency by eliminating irrelevant extents), better compression, and auto-indexing of columns.
Column-oriented systems allow the use of standard MySQL syntax for most commands. For instance: create table, select, insert, and so on. You will find some exceptions, such as the lack of cartesian products and trigger support.
And finally, integrate your knowledge of standard SQL/MySQL with frontend.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

Write agent-friendly API documentation with OpenAPI, clear schemas, workflow guidance, and llms.txt for safer AI automation.

Local AI proxy tutorial for detecting, masking, and rehydrating PII before prompts reach cloud LLMs.

Learn how Graph RAG uses connected knowledge structures to improve retrieval beyond simple text similarity.

Learn how sibling-index() enables clean, JavaScript-free stagger animations using native CSS.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

