Editor’s note: This Node.js web scraping tutorial was last updated by Alexander Godwin on 29 May 2023 to include a comparison about web crawler tools. For more information, check out “The best Node.js web scrapers for your use case.”

In this Node.js web scraping tutorial, we’ll demonstrate how to build a web crawler in Node.js to scrape websites and store the retrieved data in a Firebase database. Our web crawler will perform the web scraping and data transfer using Node.js worker threads.
Jump ahead:
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
A web crawler, often shortened to crawler or referred to as a spiderbot, is a bot that systematically browses the internet typically for the purpose of web indexing. These internet bots can be used by search engines to improve the quality of search results for users.
In addition to indexing the world wide web, crawling can also gather data. This is known as web scraping. Web scraping includes examples like collecting prices from a retailer’s site or hotel listings from a travel site, scraping email directories for sales leads, and gathering information to train machine-learning models.
The process of web scraping can be quite taxing on the CPU depending on the site’s structure and complexity of data being extracted. You can use worker threads to optimize the CPU-intensive operations required to perform web scraping in Node.js.
Launch a terminal and create a new directory for this tutorial:
$ mkdir worker-tutorial $ cd worker-tutorial
Initialize the directory by running the following command:
$ yarn init -y
We also need the following packages to build the crawler:
If you’re not familiar with setting up a Firebase database, check out the documentation and follow steps 1 through 3 to get started.
Now, let’s install the packages listed above with the following command:
$ yarn add axios cheerio firebase-admin
Before we start building the crawler using workers, let’s go over some basics. You can create a test file, hello.js, in the root of the project to run the following snippets.
A worker can be initialized (registered) by importing the worker class from the worker_threads module like this:
// hello.js
const { Worker } = require('worker_threads');
new Worker("./worker.js");
Hello World with workers in Node.jsPrinting out Hello World with workers is as simple as running the snippet below:
// hello.js
const { Worker, isMainThread } = require('worker_threads');
if(isMainThread){
new Worker(__filename);
} else{
console.log("Worker says: Hello World"); // prints 'Worker says: Hello World'
}
This snippet pulls in the worker class and the isMainThread object from the worker_threads module:
isMainThread helps us know when we run either inside the main thread or a worker threadnew Worker(__filename) registers a new worker with the __filename variable which, in this case, is hello.jsWhen a new worker thread spawns, there is a messaging port that allows inter-thread communications. Below is a snippet that shows how to pass messages between workers (threads):
// hello.js
const { Worker, isMainThread, parentPort } = require('worker_threads');
if (isMainThread) {
const worker = new Worker(__filename);
worker.once('message', (message) => {
console.log(message); // prints 'Worker thread: Hello!'
});
worker.postMessage('Main Thread: Hi!');
} else {
parentPort.once('message', (message) => {
console.log(message) // prints 'Main Thread: Hi!'
parentPort.postMessage("Worker thread: Hello!");
});
}
In the snippet above, we send a message to the parent thread using parentPort.postMessage() after initializing a worker thread. Then, we listen for a message from the parent thread using parentPort.once().
We also send a message to the worker thread using worker.postMessage() and listen for a message from the worker thread using worker.once().
Running the code produces the following output:
Main Thread: Hi! Worker thread: Hello!
Let’s build a basic web crawler that uses Node workers to crawl and write to a database. The crawler will complete its task in the following order:
tbody, tr, and td) and extract exchange rate valuesworker.postMessage()parentPort.on()Let’s create two new files in our project directory:
main.js for the main threaddbWorker.js for the worker threadThe source code for this tutorial is available here on GitHub. Feel free to clone it, fork it, or submit an issue.
In this section, we’ll look at two important tools for web scraping: Axios and Cheerio.
Axios allows us to make network requests. In this case, we’ll use Axios to fetch the HTML from a site of our choice the pass the resulting HTML to Cheerio. To get started with Axios, run the following npm command:
npm install axios
Next, require the Axios package in your JavaScript code:
const axios = require("axios")
//usage
await axios.get("https://www.iban.com/exchange-rates")
await axios({
method: "get",
url: "https://www.iban.com/exchange-rates"
})
In addition to the get method shown above, Axios supports all REST methods such as post, put, and delete. Axios also allows you to set important properties by providing additional object arguments as follows:
await axios.post("https://www.iban.com/exchange-rates", {
firstName: "John",
lastName: "Doe"
}, {
headers: {
Content-Type: "Application/json",
authorization: "Bearer token"
}
//additional properties
})
Axios works well both on the frontend and backend of applications with the same implementation — nothing needs to be changed. It is robust and provides a wide range of features.
Meanwhile, Cheerio enables us to work with the DOM (Document Object Model). It allows us to extract elements from HTML using the jQuery selector syntax($).
To install Cheerio, run the npm command below:
npm install cheerio
Then, add Cheerio to your JavaScript code:
const cheerio = require("cheerio")
Cheerio provides multiple functionalities that make web scraping easier. Some of these functionalities include:
Loading a document: This is the first step when working with Cheerio. A document has to be loaded before its properties can be accessed or manipulated. To load a document, run the following code:
const $ = cheerio.load('<h3 class="heading">lorem ipsum</h3>');
Selecting elements: This can be done after the document has been loaded:
$('h3.heading').text(); // "lorem ipsum"
Traversing the DOM: This functionality allows you to employ elaborate methods to find elements in the DOM:
$('h3.heading').find('.subtitle').text();
Cheerio is much faster than other web scraping solutions, as it only parses markup in order to provide an API for traversing or manipulating, Cheerio does not interpret the result as a web browser does.
In the main thread, main.js, we will scrape the IBAN website for the current exchange rates of popular currencies against the US dollar. We will then import Avios and use it to fetch the HTML from the site using a simple GET request.
We will also use Cheerio to traverse the DOM and extract data from the table element. To know the exact elements to extract, we will open the IBAN website in our browser and load dev tools:
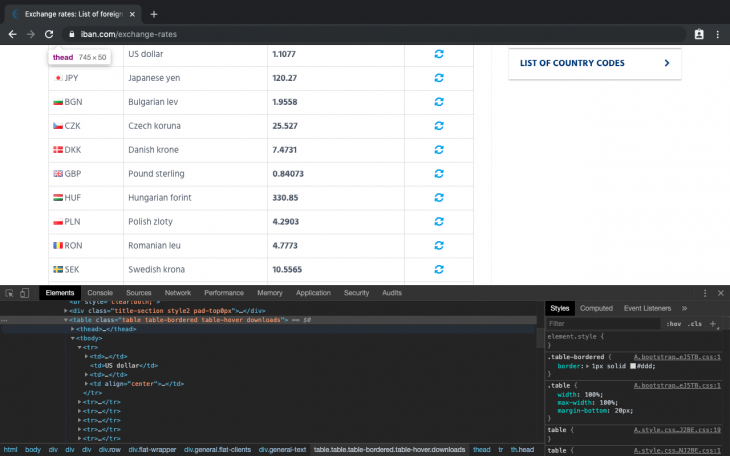
From the image above, we can see the table element with the classes:
table table-bordered table-hover downloads.
This will be a great starting point and we can feed that into our cheerio root element selector:
// main.js
const axios = require('axios');
const cheerio = require('cheerio');
const url = "https://www.iban.com/exchange-rates";
fetchData(url).then( (res) => {
const html = res.data;
const $ = cheerio.load(html);
const statsTable = $('.table.table-bordered.table-hover.downloads > tbody > tr');
statsTable.each(function() {
let title = $(this).find('td').text();
console.log(title);
});
})
async function fetchData(url){
console.log("Crawling data...")
// make http call to url
let response = await axios(url).catch((err) => console.log(err));
if(response.status !== 200){
console.log("Error occurred while fetching data");
return;
}
return response;
}
Running the code above with Node will give the following output:

Going forward, we will update the main.js file so we can properly format our output and send it to our worker thread.
To properly format our output, we must get rid of white space and tabs because we will store the final output in JSON. Let’s update the main.js file accordingly:
// main.js
[...]
let workDir = __dirname+"/dbWorker.js";
const mainFunc = async () => {
const url = "https://www.iban.com/exchange-rates";
// fetch html data from iban website
let res = await fetchData(url);
if(!res.data){
console.log("Invalid data Obj");
return;
}
const html = res.data;
let dataObj = new Object();
// mount html page to the root element
const $ = cheerio.load(html);
let dataObj = new Object();
const statsTable = $('.table.table-bordered.table-hover.downloads > tbody > tr');
//loop through all table rows and get table data
statsTable.each(function() {
let title = $(this).find('td').text(); // get the text in all the td elements
let newStr = title.split("\t"); // convert text (string) into an array
newStr.shift(); // strip off empty array element at index 0
formatStr(newStr, dataObj); // format array string and store in an object
});
return dataObj;
}
mainFunc().then((res) => {
// start worker
const worker = new Worker(workDir);
console.log("Sending crawled data to dbWorker...");
// send formatted data to worker thread
worker.postMessage(res);
// listen to message from worker thread
worker.on("message", (message) => {
console.log(message)
});
});
[...]
function formatStr(arr, dataObj){
// regex to match all the words before the first digit
let regExp = /[^A-Z]*(^\D+)/
let newArr = arr[0].split(regExp); // split array element 0 using the regExp rule
dataObj[newArr[1]] = newArr[2]; // store object
}
In the code block above, we are doing more than data formatting; after the mainFunc() resolves, we pass the formatted data to the worker thread for storage.
In this worker thread, we will initialize Firebase and listen for the crawled data from the main thread. When the data arrives, we will store it in the database and send a message back to the main thread to confirm that data storage was successful.
The snippet that takes care of the aforementioned operations can be seen below:
// dbWorker.js
const { parentPort } = require('worker_threads');
const admin = require("firebase-admin");
//firebase credentials
let firebaseConfig = {
apiKey: "XXXXXXXXXXXX-XXX-XXX",
authDomain: "XXXXXXXXXXXX-XXX-XXX",
databaseURL: "XXXXXXXXXXXX-XXX-XXX",
projectId: "XXXXXXXXXXXX-XXX-XXX",
storageBucket: "XXXXXXXXXXXX-XXX-XXX",
messagingSenderId: "XXXXXXXXXXXX-XXX-XXX",
appId: "XXXXXXXXXXXX-XXX-XXX"
};
// Initialize Firebase
admin.initializeApp(firebaseConfig);
let db = admin.firestore();
// get current data in DD-MM-YYYY format
let date = new Date();
let currDate = `${date.getDate()}-${date.getMonth()}-${date.getFullYear()}`;
// recieve crawled data from main thread
parentPort.once("message", (message) => {
console.log("Recieved data from mainWorker...");
// store data gotten from main thread in database
db.collection("Rates").doc(currDate).set({
rates: JSON.stringify(message)
}).then(() => {
// send data back to main thread if operation was successful
parentPort.postMessage("Data saved successfully");
})
.catch((err) => console.log(err))
});
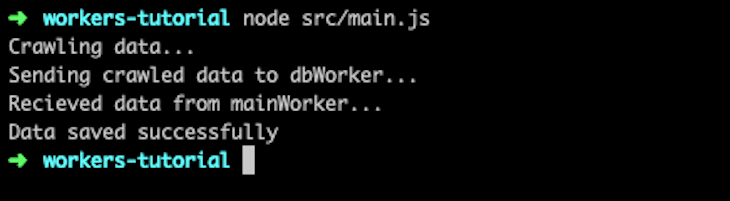
Running main.js, which encompasses dbWorker.js, with Node will give the following output:
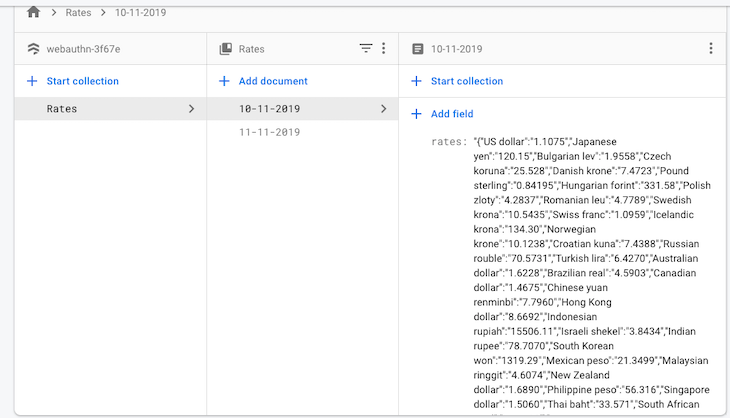
You can now check your Firebase database and see the following crawled data:
The method we implemented above uses two different packages, Axios and Cheerios, to fetch and traverse webpages. An alternative web crawler we can use is node-crawler, which uses Cheerio under the hood and comes with extra functionalities that allow you to customize the way you crawl and scrape websites.
With node-crawler, you can specify options like the maximum number of requests that can be carried out at a time (maxConnections), the minimum time allowed between requests (rateLimit), the number of retries allowed if a request fails, and the priority of each request.
Let’s take a look at how node-crawler’s code works.
In your project directory, run the following command:
npm install crawler
In a file named crawler.js, add the following code:
const Crawler = require('crawler');
const crawlerInstance = new Crawler({
maxConnections: 10,
callback: (error, res, done) => {
if (error) {
console.log(error);
} else {
const $ = res.$;
const statsTable =
$('.table.table-bordered.table-hover.downloads > tbody > tr');
statsTable.each(function() {
let title = $(this).find('td').text();
console.log(title);
});
}
done();
}
});
crawlerInstance.queue('https://www.iban.com/exchange-rates');
Here, we use one package, node-crawler, to fetch a webpage and traverse its DOM. We import its package into our project and create an instance of it named crawlerInstance.
The maxConnection option specifies the number of tasks to perform at a time. In this case, we set it to 10. Next, we create a callback function that carries out after a web page is fetched. The line const $ = res.$ makes Cheerio available in the newly fetched webpage.
Next, similar to what we did before, we traverse the IBAN exchange rate page, grab the data on the table, and display them in our console.
The queue function is responsible for fetching the data of webpages, a task performed by Axios in our previous example:

To fetch data from multiple webpages at once, add all the URLs to queue like this:
crawlerInstance.queue(['https://www.iban.com/exchange-rates','http://www.facebook.com']);
By default, node-crawler uses the callback function created when instantiating it (the global callback). To create a custom callback function for a particular task, simply add it to the queue request:
crawlerInstance.queue([{
uri: 'http://www.facebook.com',
callback: (error, res, done) => {
if (error) {
console.log(error);
} else {
console.log('res.body.length');
}
done();
}
}]);
As mentioned above, one of the advantages of using node-crawler is that it lets you customize your web-scraping tasks and add bottlenecks to them.
You might be wondering why you need to purposefully add bottlenecks to your tasks. This is because websites tend to have anti-crawler mechanisms that can detect and block your requests if they all execute at once. With node-crawler’s rateLimit, time gaps can be added between requests, to ensure that they don’t execute at the same time.
As mentioned earlier, maxConnection can also add bottlenecks to your tasks by limiting the number of queries that can happen at the same time. Here’s how to use both options:
const crawlerInstance = new Crawler({
rateLimit: 2000,
maxConnections: 1,
callback: (error, res, done) => {
if (error) {
console.log(error);
} else {
const $ = res.$;
console.log($('body').text());
}
done();
}
});
With rateLimit set to 2000, there will be a two second gap between requests.
| node-crawler | Our scraper | |
|---|---|---|
| Rate-limiting | yes | no |
| Maximum connections | yes | no |
| Queue | yes | no |
| HTTP scraping | yes | yes |
Besides node-crawler, there are a few other open source crawlers available to make web crawling better and more efficient. Each of these web crawlers has features that set them apart from the rest.
Crawlee is an open source crawling and automation library that helps you build reliable scrapers. It has an inbuilt anti-blocking system that allows your crawlers to fly under the radar of modern bot protections.
Crawlee is written in Typescript, and it also uses Playwright and Puppeteer. Because Playwright and Puppeteer provide headless-browser functionalities, this means that you can scrape dynamic web pages. Crawlee also integrates well with Cheerio and JSDOM.
This is how Crawlee compares to the web scraper we built in this tutorial, and node-crawler:
| Crawlee | Our scraper | node-crawler | |
|---|---|---|---|
| Headless browsers | yes | no | yes |
| Queues | yes | no | yes |
| Proxy | yes | no | yes |
| HTTP scraping | yes | yes | yes |
Scrapy is an open source web scraping library written in Python. It is a fast, high-level web scraping framework, and it is also the most popular open source web scraper you’ll find on the internet.
Web Magic is another open source scraper that is written in Java. It covers the whole lifecycle of a crawler: downloading, URL management, content extraction, and persistent. It has the following features:
- Simple core with high flexibility - Simple API for HTML extracting - Annotation with POJO to customize a crawler, with no configuration - Multi-thread and distribution support - Easily integrated
Here’s a comparison between Web Magic, our web scraper, and node-crawler:
| Web Magic | Our scraper | node-crawler | |
|---|---|---|---|
| Language | Java | Javascript | Javascript |
| Multi-thread support | yes | no | no |
| HTTP scraping | yes | yes | yes |
Written in Python, pyspider is a powerful open source web crawler system that can crawl static sites and also integrate with the PhantomJS headless browser to crawl dynamic web pages:
| pyspider | Our scraper | node-crawler | |
|---|---|---|---|
| Language | Python | Javascript | Javascript |
| Headless browser | yes | no | yes |
| HTTP scraping | yes | yes | yes |
| Queues | yes | no | yes |
From the simple comparisons above, we can see that an open source web crawler allows us to implement features that would have taken quite some time to do on our own. We might not need all of the features provided by an open source crawler, but it’s nice to know that they are readily available to us whenever we need them.
Proxies are intermediary servers that stand between a client and other servers. Proxies can be used to make requests, and hide the details of requests made. When making a request for you, proxies don’t give out your IP address.
This is helpful because some websites implement anti-scraping mechanisms. This means that if we have multiple proxies, we can use them to make multiple requests without having a website detecting and blocking our IP address.
The code below shows how to make requests with proxies using Axios:
const res = await axios.get('https://api.ipify.org/?format=json',
{
proxy: {
protocol: 'http',
host: '46.4.96.137',
port: 1080
}
}
)
console.log(res.data)
Although web scraping can be fun, it can also be against the law if you use data to commit copyright infringement. It is generally advised that you read the terms and conditions of the site you intend to crawl to know their data crawling policy beforehand. You can learn more about web crawling policy before undertaking your own Node.js web scraping project.
The use of worker threads does not guarantee your application will be faster but it can look that way if used efficiently. This is because it frees up the main thread by making CPU-intensive tasks less cumbersome on the main thread.
In this tutorial, we learned how to build a web crawler that scrapes currency exchange rates and saves them to a database. We also learned how to use worker threads to run these operations. The source code for each of the following snippetsx is available on GitHub. Feel free to clone it, fork it, or submit an issue.
 Monitor failed and slow network requests in production
Monitor failed and slow network requests in productionDeploying a Node-based web app or website is the easy part. Making sure your Node instance continues to serve resources to your app is where things get tougher. If you’re interested in ensuring requests to the backend or third-party services are successful, try LogRocket.

LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.

Learn how AI-assisted development governance uses rules, agents, hooks, and protocols to help AI coding tools produce safer, more consistent code.

A step-by-step guide to building your first MCP server using Node.js, covering core concepts, tool design, and upgrading from file storage to MySQL.

Using security headers in your Next.js apps is a highly effective way to secure websites from common security threats.

A deep dive into May 2026’s AI model and tool rankings. We break down performance, usability, pricing, and real-world capabilities across 50+ features to help you pick the right tools for your development workflow.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

