Never guess about project history again

When it comes to productivity in software development, knowledge is power. The industry of project management tools — helping a development team to know where they stand — is vast. But software developers have one underused tool that can be leveraged to provide much more information — version control.
A life of a software project is punctuated by releases. In open-source, they can be publishings to a package manager. In a software shop, typically we’re talking about deployments to a production server.
Whatever they are, the knowledge that is of great use when it comes to releases is when they have happened and what they included. In a big enough project it’s common to keep a change log and tag releases, but who has time for that with when you have to release early and release often?
Usually, it looks something like this:
The last release happened a week ago, and now that we’re done with a new, necessary feature, let’s do another one.
The question of what else changed and the size/impact of how big the overall changes remains unanswered. In essence, we simply hope that we did not forget about anything important.
It all starts with a commit message. Structured commit messages will be the very basis of the automation process. Another git entity as use will be a tag — which will mark each release. Based on the information in commit messages since last release, the next one will be prepared — or not, if the changes since last release won’t call for it. Neat, right?
All that follows is available in this repository:
GitHub – adekbadek/semantic-release-demo: a minimal example of using semantic-release for release/version control
a minimal example of using semantic-release for release/version control – adekbadek/semantic-release-demo
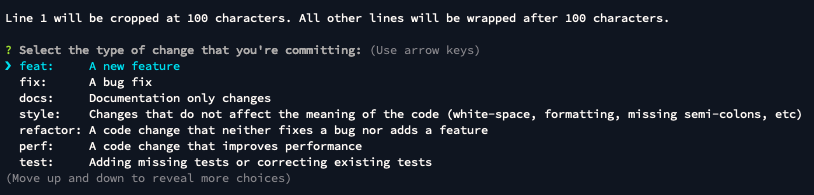
First off, a helping hand in structuring the commit messages: commitizen. Install it with $ npm i -D commitizen and then set it up to use the conventional changelog: $ npx commitizen init cz-conventional-changelog -D -E . Then add an npm script that will call git-cz (the binary for commitizen) and after staging the changes in git, run it. Now you should see this welcoming prompt:
Good. But working with other people and your future self means that someone might forget to use commitizen and wreck the whole setup. Fortunately, git provides a thing called hooks! If you look into .git/hooks of a fresh repository, you’ll see a bunch of *.sample files — hooks are simply bash scripts that will fire when certain actions occur. But who codes in bash when you have npm, right? Just $ npm i -D husky and watch that hooks folder populate with scripts that you don’t have to write. Husky is a tool that does the hooks business based on config in package.json.
Now let’s get a linter for those commit messages. Firstly, install it — $ npm i -D @commitlint/{config-conventional,cli}. Then, create the commitlint.config.js config file:
module.exports = {extends: ['@commitlint/config-conventional']}
After that, provide some information for husky in package.json:
“husky”: {
“hooks”: {
“commit-msg”: “commitlint -E HUSKY_GIT_PARAMS”
}
}
That’s it! Try to add the files to git staging and commit with a gibberish commit message — husky’s gonna bite!
Now we have a guarantee that the commit messages will be meaningful (or at least formatted). Time for the main protagonist of this tutorial: enter semantic-release: $ npm i -D semantic-release . Along with that, add an npm script that will invoke it (just “semantic-release”: “semantic-release”).
This tool is by default meant to publish on npm — if that’s not in your plans then some default-config-overriding will have to be performed. Add a “release” key in package.json with the following content:
"plugins": [ "@semantic-release/commit-analyzer", "@semantic-release/release-notes-generator", [ "@semantic-release/npm", { "npmPublish": false } ], "@semantic-release/github" ]
Semantic-release will do its work in GitHub (and npm), operating from a CI server — CircleCI in this case. It will thus need access to GitHub and npm via tokens, which have to be added to CI’s settings:

As you can see, the tokens need be available as environment variables named GITHUB_TOKEN and NPM_TOKEN. Now let’s add a config for CircleCI, called .circleci/config.yml— which is a bit bloated so you may just copy it from here.
Everything is ready now! If CI sees a commit message that should trigger a release (like those starting with feat or fix), all will happen automatically. A release and tag will be published on GitHub and — unless configured differently — a new package version on npm.
Nice.
But, there is one problem. Two, actually. After a release, the version field in package.json has remained the same, and where is that change log that will be so helpful down the road? Don’t worry, it’s all two changes away:
First, install some additional packages: $ npm i -D @semantic-release/changelog @semantic-release/git. Then, add this config in “release” section of package.json:
"prepare": [ "@semantic-release/changelog", "@semantic-release/npm", { "path": "@semantic-release/git", "assets": [ "package.json", "package-lock.json", "CHANGELOG.md" ], "message": "chore(release): ${nextRelease.version} [skip ci]nn${nextRelease.notes}" } ]
This will tell semantic-release to generate a change log and then to add a commit after it’s done with the version releasing. You can tweak many more settings in this section, visit semantic-release docs for more info.
With that setup, a release will happen not on a whim, but based on the changes in code. And when it does, a change log will be generated so everyone knows what landed in the subsequent releases and when they happened.
As you probably noticed, a release is marked by a version. With semantic-release, the numbers in the version follow a system called Semantic Versioning (aka SemVer). In short, these denote major, minor, and patch versions. A patch number is incremented when backwards-compatible bugfixes are added, minor: backwards-compatible features, and major: breaking changes (incompatible with the versions before).
Semantic versioning is important for your users (or a client) — this way they know what can they expect with a new release and what has changed since they last used/seen the project. If the last version someone used is 1.0.1 and the current version is 1.1.42 then they know that there were many more bug fixes than features added in the meantime.
Semantic versioning can be opposed to sentimental versioning, in which the version numbers are incremented in an incoherent manner, and in effect they don’t mean anything.
All that setup might seem like an overkill, and for a small project maintained by a single person it might be. But I have thanked myself many times for setting it up at the beginning and I’m sure I’ll use it again whenever I can. It’s just very reassuring to have that much information in git, where it won’t become outdated and is strictly tied to the code.
As for other qualms:
I just need a glance at the git log diff and I’m good.
Well, a log is by nature not meant to be read in entirety. It has a very weak signal to noise ratio.
Structuring commit messages is just annoying!
Having an unreadable commit history is even more. Try debugging with no information whatsoever about when a bug could have been introduced.
I’m pretty used to meaningless commit messages…
Having to specify what the commit is about makes a developer think twice about the committed changes. If you’re unsure about the type of a commit, maybe the changes aren’t so clear either?
Thanks for reading!
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

I migrated 20 production-style components from Tailwind to StyleX. Here’s what the data showed about LOC, CSS bundle size, build time, and type safety.

A guide for using JWT authentication to prevent basic security issues while understanding the shortcomings of JWTs.

Discover how to build, render, and automate product demo videos with Remotion, replacing traditional screen recordings with reusable React code.

Chrome’s Modern Web Guidance embeds modern web platform skills into AI coding agents, helping them choose native HTML, CSS, and browser APIs over legacy patterns.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

