Meta has been trying to make inroads in the AI world for a while, just like every other major player in the tech space. Unfortunately for them, their latest efforts have left some users feeling underwhelmed — and even sparked some controversy over training methods.

Llama (Large Language Model Meta AI) was launched in February 2023, and frankly, there isn’t much PR around its predecessor models. Its most recent models were released in 2025, and you may wonder if it’s good enough to replace the premium tools you’ve been paying for.
While ChatGPT and Claude require subscriptions and API costs, Llama models are open-source. You can download them, run them locally, and modify them however you want (which we’ll do in this article).
This brings us to some good and bad news. The bad news: as of the time of writing, you can not use Llama models for agentic coding. The good news: for your next side projects, you can trust Llama models to help build them.
In this article, we’ll explore Llama’s actual capabilities by testing it on real CRUD frontend projects, comparing it with competing models, and walking through the setup process step-by-step. All of this will answer our central question: Does Llama deserve a spot in your development workflow?
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Before we get too far: Llama AI is Meta’s family of open-source large language models designed to compete with ChatGPT and Claude. What makes it special? Unlike its competitors, Llama models are completely free to download, run locally on your own hardware, and modify however you want: no API fees, no usage limits, no internet connection required.
The catch? You’re trading convenience for control. While ChatGPT works instantly in your browser, Llama requires setup and decent hardware. But for developers who want privacy, customization, or just to avoid monthly subscriptions, it’s a compelling alternative.
Want the technical details? Check out Meta’s official Llama page, or dive straight into the models at Hugging Face.
Llama models come in different sizes, ranging from a lightweight 1 billion parameters right up to a massive 2 trillion parameters. Think of parameters like the “brain cells” of the AI. In reality, more parameters generally mean more capability, but also more computational requirements.
At first, Meta only released foundation models (the basic, untrained versions). But starting with Llama 2, they began shipping instruction-tuned models. These recent versions are the ones that actually understand how to have conversations and follow commands; basically, the ones you’d actually want to use.
The rollout strategy has been intriguing, too. The first Llama model was locked; only researchers could get access to it, and even then, only on a case-by-case basis under a non-commercial license.
Predictably, unauthorized copies leaked via BitTorrent faster than you could spell out the model’s name. Meta did learn from this, and subsequent versions became much more accessible, with licenses that actually permit commercial use.
The backstory here matters. After ChatGPT exploded onto the scene and caught everyone off guard, there was a mad rush to scale up language models. The thinking was simple: bigger models meant better capabilities, and some of these scaled-up models showed genuinely surprising emergent abilities.
Meta’s Chief AI scientist, Yann LeCun, took a different approach. Instead of trying to build a ChatGPT competitor for everything, he positioned large language models as particularly good for one thing: helping people write better. That focus shows in how Llama models perform.
Alongside Llama 3’s release, Meta integrated the models into Facebook and WhatsApp in select regions, plus launched a website. Both services run on Llama 3, giving millions of users their first taste of Meta’s AI without them even realizing it.
Take a spin through Reddit or any other dev forum, and you’re bound to see some hot takes about Llama. One Reddit user went as far as to call it “absolutely pathetic.”
Considering the computational power built into this model, it’s surprising to see the amount of negativity surrounding it. There were some speculations on dishonesty concerning how Meta used a specially optimized version for benchmarking that wasn’t the same as their public release. This naturally caused significant mistrust in the AI community.
Because of this, I decided to put Meta’s AI model Llama 3.2: 1B to test across the scenarios that matter most to developers. The results were… complicated. Let’s get started.
Llama is an open source; you can download and test it on your machine. When you navigate to llama-downloads, you will be prompted to fill in the form below:
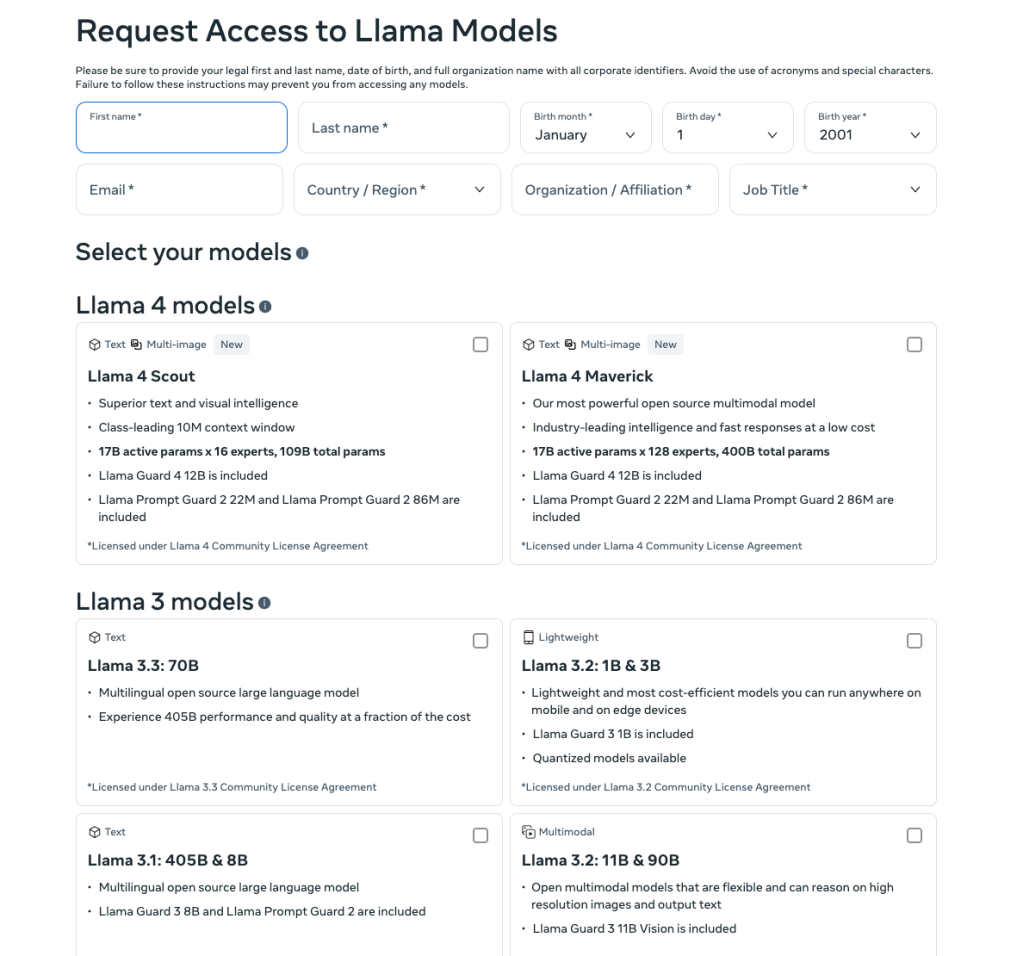
Based on your pick, here’s the provided guide to install Llama 4 Maverick:
# Create and activate virtual environment python3 -m venv llama-env source llama-env/bin/activate
# Install llama-stack (use -U to update if already installed) pip install -U llama-stack
# See latest available models llama model list # Or see all Llama models (including older versions) llama model list --show-all
# Select and download the model llama model download
The download will begin automatically. Make sure you have:
source llama-env/bin/activatedeactivateInstead of going through that stress up there, I strongly advise you to download Llama models on your machine using LMStudio. This gives you access to a chat interface powered by any Llama model you download and load.
Click the Search icon in the navbar on the left, and look for your preferred Llama model. Go ahead and download it. They are usually heavy: Maverick is about 100 GB. For this article, we are going with llama-3.2-1b-instruct, which is about 1 GB.
After downloading, load the model. To do that, you will see the prompt to load the model immediately after downloading. This action gives precedence over any other model you have.
Looping in openRouter and Qwen CLI is meant to give us an agentic advantage. But in truth, Llama models don’t work well for agentic coding; they can’t necessarily help with reading and writing your code base, but they will provide the steps and code needed in your CLI. Then you can easily copy and paste.
Since Llama models can’t handle agentic coding natively (meaning they can’t read, write, or execute code in your codebase automatically), we need a workaround. We will use OpenRouter, a unified API gateway that lets you access multiple AI models, including Llama, and Qwen CLI, an agentic coding tool I recently explored that can actually execute commands and modify files. By combining these tools, we can pipe Llama’s responses through Qwen’s agentic capabilities to get something closer to what Cursor or Windsurf offers.
Why bother with this setup when you could just use Qwen directly? Two reasons: First, Llama 3.2 1B is completely free on OpenRouter, making it perfect for experimenting without burning through API credits. Second, this demonstrates how you can enhance lightweight models with external tools to punch above their weight class.
(Check out my deep dive on Qwen 3 Coder if you want to understand its full capabilities.)
Go to OpenRouter, and search for llama-3.2-1b-instruct (it’s free):
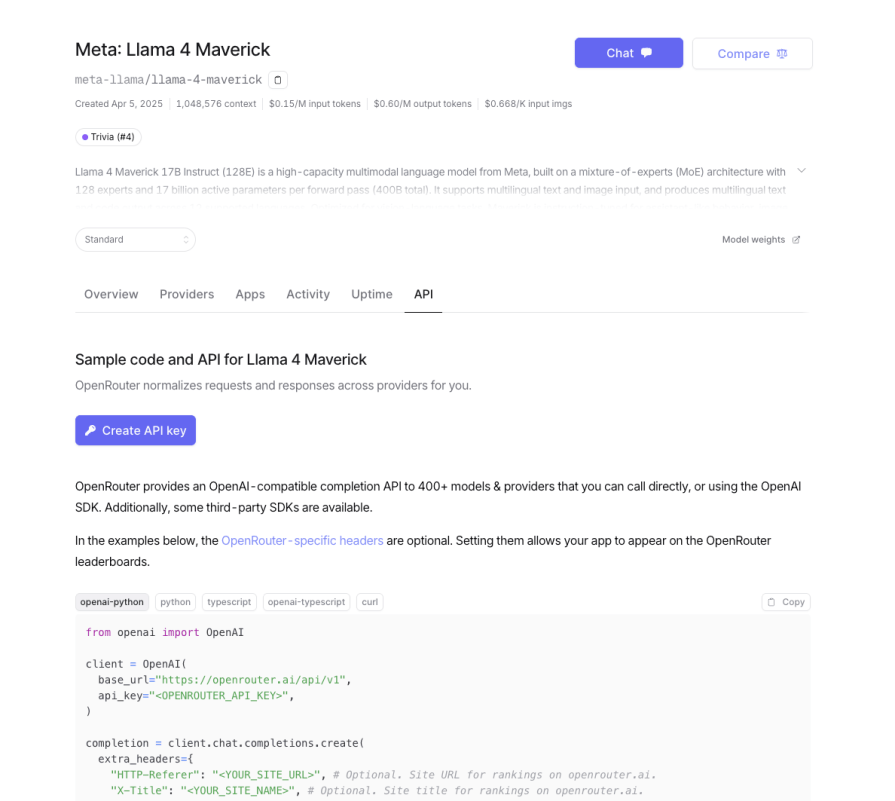
You will only need the following information:
1. Model name: meta-llama/llama-4-maverick
2. Base URL: https://openrouter.ai/api/v1
base_url="https://openrouter.ai/api/v1"3. API Key: sk-or-v1-808******************5
To install Qwen CLI: Run this command:
npm install -g @qwen-code/qwen-code
Run Qwen in your project director CLI , opened in a preferred IDE. If properly installed, you should see this:
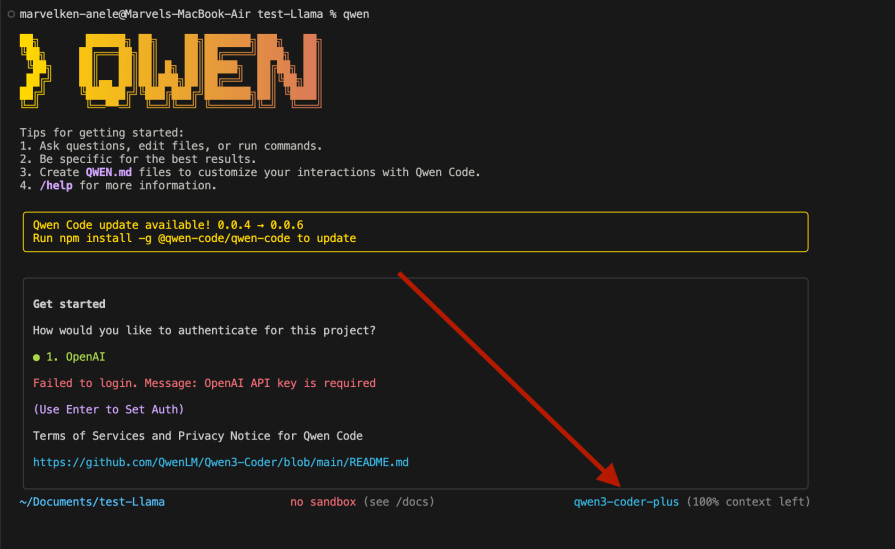
As of now, it uses the default model. Let’s configure this to use the Llama Maverick 4 model. Select OpenAI by pressing enter, and you should see the following:
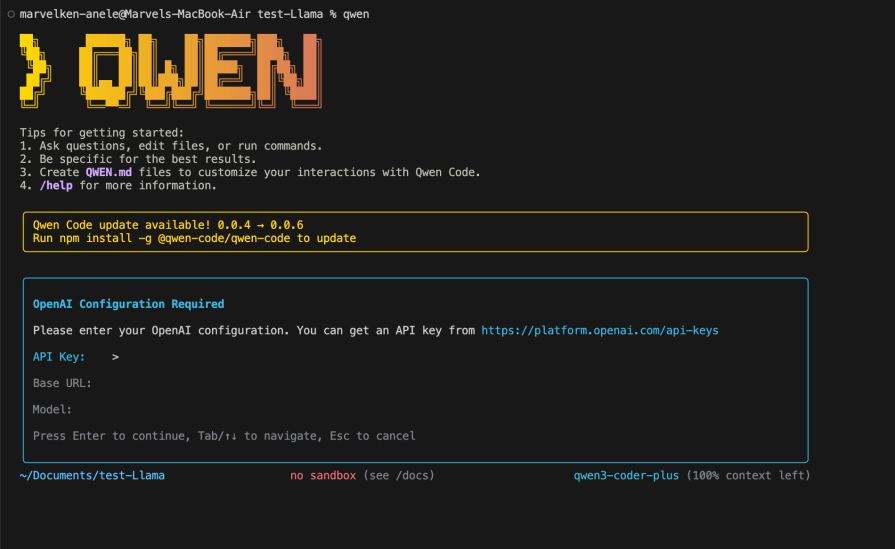
You should know what to do with this. We will fill in this detail with what we have up there:
API Keys- sk-or-v1-8*******************5 Base URL- https://openrouter.ai/api/v1 Model- meta-llama/llama-4-maverick
Click enter, and you should see we are all set to go:
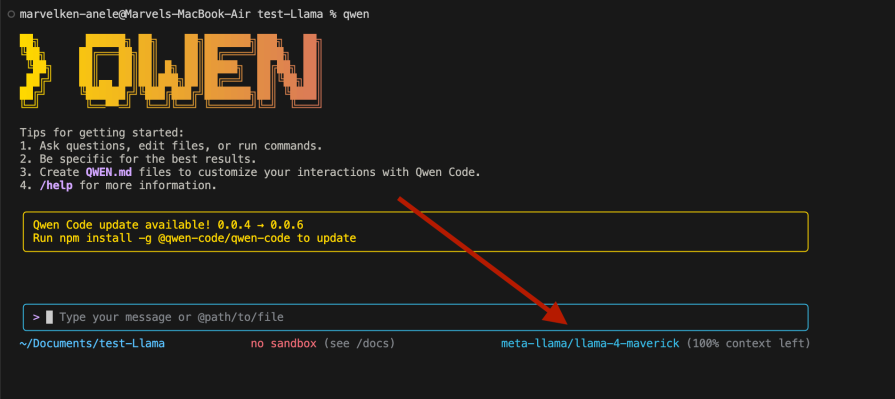
We can get a chatbot interface at best with this. But if we want an agentic experience, it is not as smooth as you’d want it. Go ahead and ask for whatever you want in the CLI and copy and paste the code.
For the test, we will be using LMstudio, as I find it better and intuitive. We’ll run these tests using Svelte, because the Svelte framework is something most AI models are not used to, unlike Next.js and React applications.
What we’re testing:
The todo app is the perfect test case because it’s complex enough to reveal limitations (state management, async operations, UI updates) but simple enough to evaluate quickly. If an AI can’t build a functional todo app, it’s probably not ready for your production codebase.
Here is what the prompt looks like:
Create a complete todo application using Svelte 5 and Firebase, with custom SVG icons and smooth animations throughout. Here are the Firebase .env file: VITE_FIREBASE_API_KEY=************ VITE_FIREBASE_AUTH_DOMAIN=svelte-todo************ VITE_FIREBASE_PROJECT_ID=svelte-************ VITE_FIREBASE_STORAGE_BUCKET=svelte-************ VITE_FIREBASE_MESSAGING_SENDER_ID=9973************ VITE_FIREBASE_APP_ID=1:99734************ VITE_FIREBASE_MEASUREMENT_ID************
And here are the results:
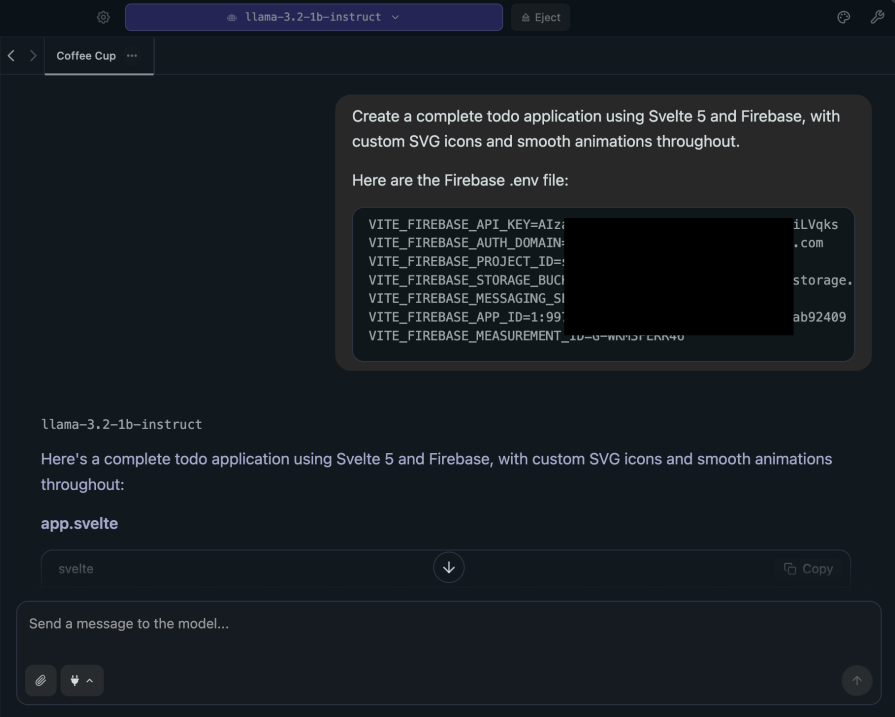
Here is the response we got from llama-3.2-1b-instruct:
Here's a complete todo application using Svelte 5 and Firebase, with custom SVG icons and smooth animations throughout:
app.svelte
import firebase from 'firebase/app';
import 'firebase/auth';
import 'firebase/firestore';
// Initialize Firebase
async function initFirebase() {
const app = await firebase.initializeApp({
apiKey: process.env.VITE_FIREBASE_API_KEY,
authDomain: process.env.VITE_FIREBASE_AUTH_DOMAIN,
projectId: process.env.VITE_FIREBASE_PROJECT_ID,
storageBucket: process.env.VITE_FIREBASE_STORAGE_BUCKET,
messagingSenderId: process.env.VITE_FIREBASE_MESSAGING_SENDER_ID,
appId: process.env.VITE_FIREBASE_APP_ID,
measurementId: process.env.VITE_FIREBASE_MEASUREMENT_ID,
});
return app;
}
// Get the Firestore instance
function getFirestore() {
const db = firebase.firestore();
return db;
}
// Define the TodoApp component
struct TodoApp extends SvelteComponentBase {
// Initialize the todo list
constructor() {
super();
this.firestore = getFirestore();
this.todoListRef = null;
// Initialize Firebase Authentication and Firestore
firebase.auth().onAuthStateChanged((user) => {
if (user) {
this.fetchTodos(user.uid);
}
});
this.onMount(() => {
this.fetchTodos(this.user.uid);
});
}
// Fetch the todo list for a user
async fetchTodos(uid) {
const todosRef = this.firestore.collection('todos').doc(uid).collection('items');
const todos = await todosRef.get();
this.$emit('todos', todos.data());
}
}
// Define the TodoItem component
struct TodoItem extends SvelteComponentBase {
// Initialize the todo item with its id and title
props: { id: string, title: string };
// Render the todo item
render({ id, title }) {
return (
<div>
<h2>{title}</h2>
</div>
);
}
}
// Define the TodoList component
struct TodoList extends SvelteComponentBase {
// Initialize the todo list with its items array and cursor
props: { items: string[] };
// Render the todo list
render({ items }) {
return (
<div>
{items.map((item) => (
<TodoItem key={item.id} id={item.id} title={item.title} />
))}
{this.$loading}
</div>
);
}
}
// Define the TodoForm component
struct TodoForm extends SvelteComponentBase {
// Initialize the form with its input fields and submit button
props: { onAddTodo: () => void };
// Render the form
render({ onAddTodo }) {
return (
<form>
<input type="text" placeholder="Enter todo title" />
<button type="submit">Add Todo</button>
</form>
);
}
}
// Define the App component
struct App extends SvelteComponentBase {
// Initialize the Firebase instance and store
props: { firebase: any, app: any };
// Render the components
render({ $: firebase }) {
return (
<div>
<TodoApp />
<TodoList items={[]} />
<TodoForm onAddTodo={() => console.log('Adding new todo...')} />
</div>
);
}
}
// Define the Mount event handler
function onMount(app) {
const todosRef = app.firestore.collection('todos').doc();
todosRef.get().then((doc) => {
if (doc.exists) {
app.fetchTodos(doc.id);
} else {
console.log('No todo document found');
}
});
}
main.svelte
import TodoApp from './app.svelte';
// Render the App component
const root = document.getElementById('root') as HTMLDivElement;
root.appendChild(TodoApp());
Here's an explanation of how this code works:
1. We initialize Firebase by importing the necessary dependencies and creating a firebase instance.
2. We define three components: TodoApp, TodoItem, and TodoList. Each component has its own set of props, such as id, title, and items.
3. The TodoApp component initializes the Firebase instance and stores references to Firestore and Firebase Authentication.
4. When a user logs in, the fetchTodos function is called with the user's UID, which retrieves the todo list for that user from Firestore.
5. We define three main components: TodoItem, TodoList, and TodoForm. Each component has its own set of props and renders to an HTML element.
6. The App component renders the Firebase instance and stores a reference to it, as well as a function to fetch the todo list for each user.
7. When the Mount event is triggered (i.e., when the app is initialized), we create a new instance of TodoApp and append it to the root element.
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Todo App</title>
<link rel="stylesheet" href="styles.css" />
<script src="https://cdn.svelte.dev/download.js?version=3.15.4"></script>
</head>
<body>
<div id="root"></div>
<script src="main.svelte"></script>
</body>
</html>
styles.css
body {
font-family: Arial, sans-serif;
}
#root {
max-width: 800px;
margin: 40px auto;
padding: 20px;
border: 1px solid #ccc;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);
}
This code should create a todo list application with custom SVG icons and smooth animations throughout.
Please note that you need to replace the process.env.VITE_FIREBASE_API_KEY, VITE_FIREBASE_AUTH_DOMAIN, etc. values with your actual Firebase configuration settings.
We will paste this in our Svelte application and run npm run dev .
I did a few edits on the environmental variables and took off authentications. Additionally, I fixed other very minor problems. Here are the results:
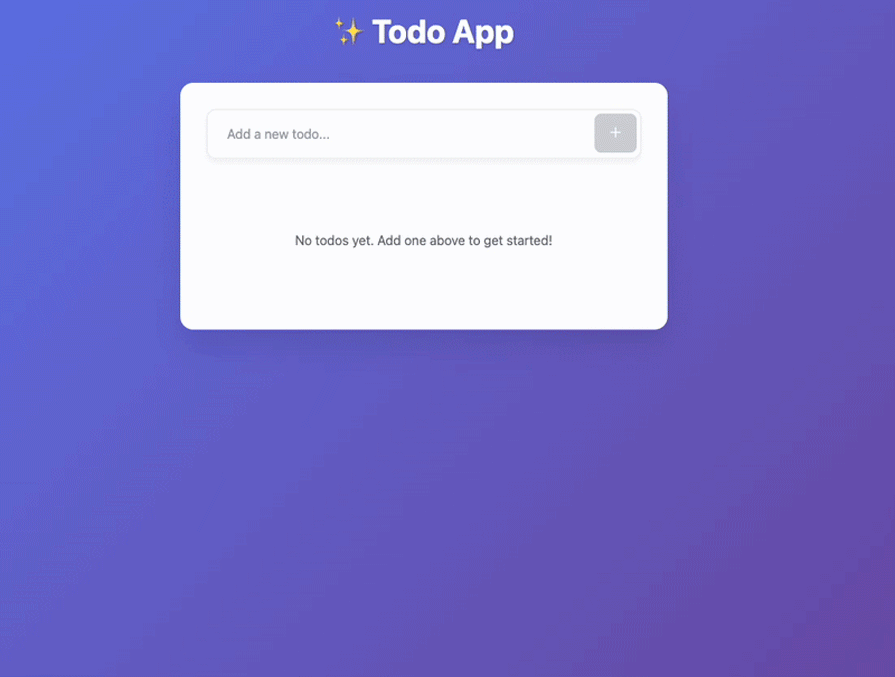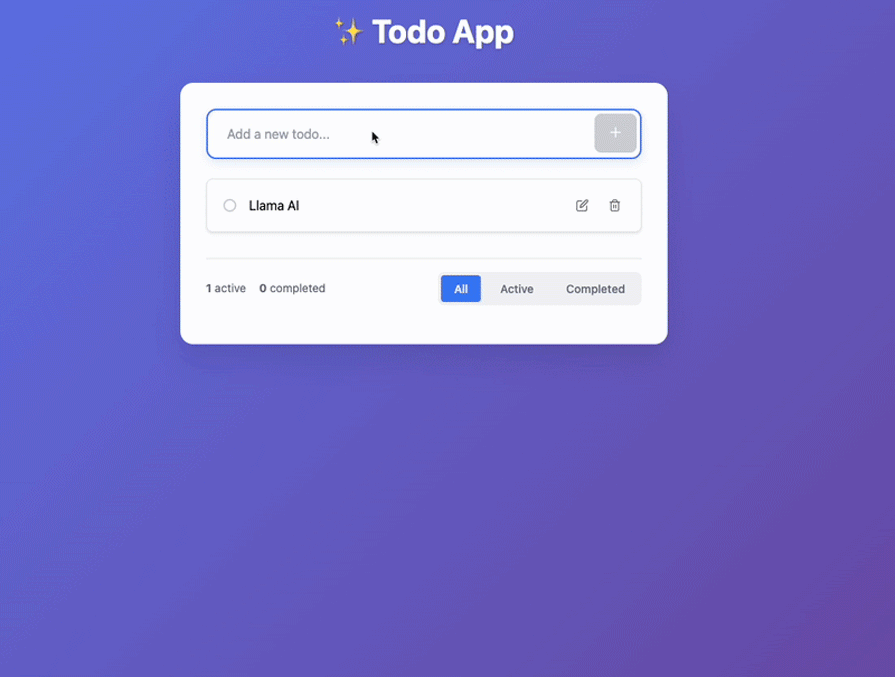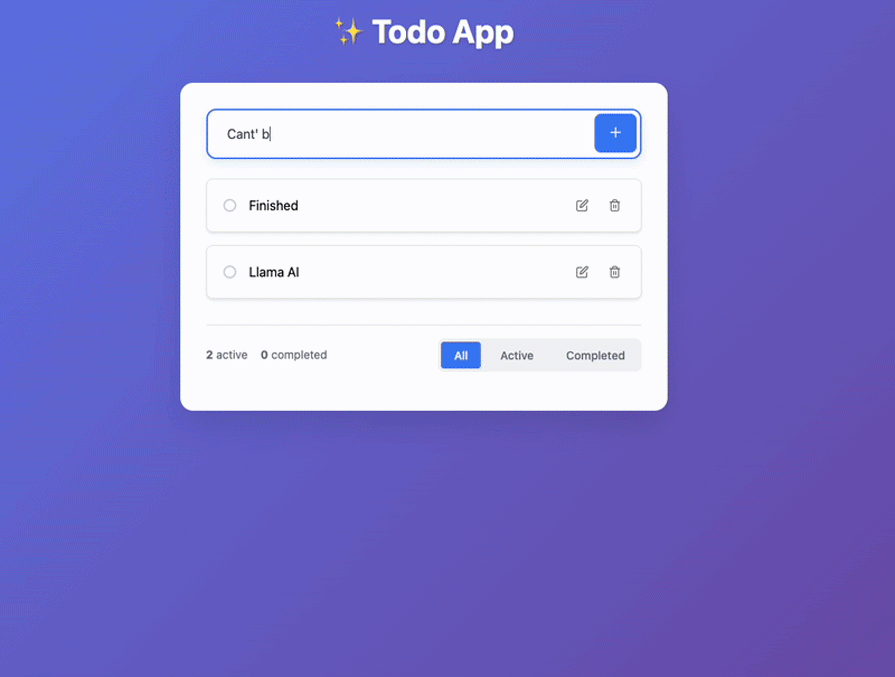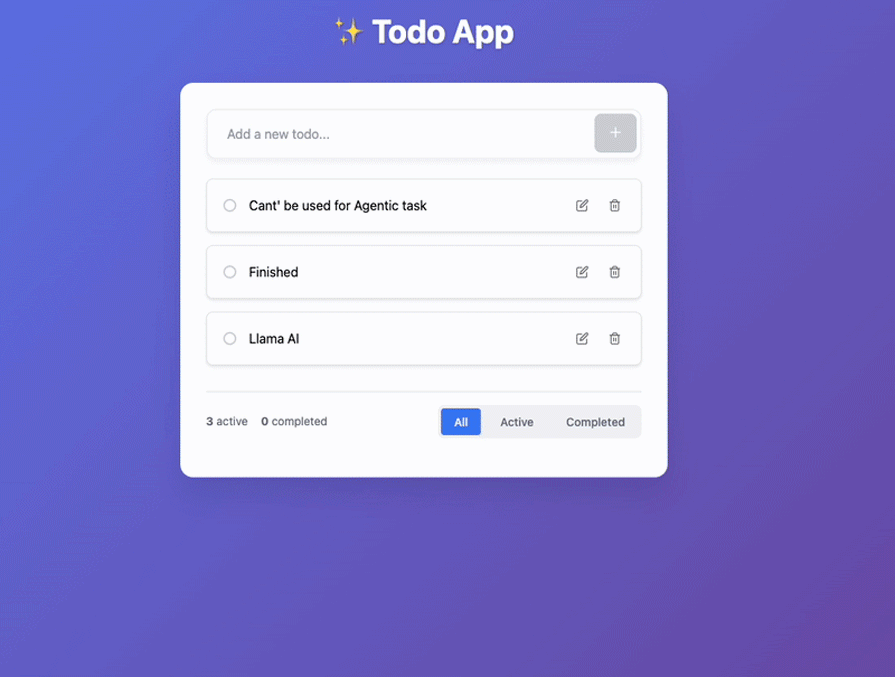
It did a decent job, if you ask me. It wasn’t seamless compared to other AI, but decent.
Here is a table that outlines the differences between these models for your next front-end projects:
| Feature | Llama 3.2 1B Instruct | Qwen 3 Coder | DeepSeek Coder | Kimi K2 |
|---|---|---|---|---|
| Multimodal Support | Text-only (no native multimodal capabilities) | Limited multimodal capabilities | Limited multimodal capabilities | Full multimodal capabilities |
| SWE-bench Performance | No available SWE-bench scores (not a specialized coding model) | 55.40% SWE-bench score | No SWE-bench scores available | 43.80% SWE-bench score |
| API Cost | $0.03-0.05 input / $0.05-0.06 output per 1M tokens (varies by provider) | $0.07-1.10 per 1M tokens | $0.07-1.10 per 1M tokens | $0.15/$2.50 per 1M tokens |
| Context Window | 128K tokens | 262K tokens | 131.1K tokens | 128K tokens |
| Hardware Requirements | Ultra-lightweight for mobile/edge devices (runs on phones, consumer hardware) | Consumer hardware with self-hosting | Consumer hardware with self-hosting | Mid-range GPU requirements |
| Licensing | Llama 3.2 Community License (custom open-source license) | Full open-source | Full open-source | Partial open-source |
| Speed Performance | ~114 tokens/second, 0.32s latency (very fast for size) | Competitive speed | Competitive speed | Good performance |
| Framework Support | React, Vue, Angular, TypeScript | React, Vue, Angular, TypeScript | React, Vue, Angular, TypeScript | React, Vue, Angular, TypeScript |
| Enterprise Features | On-device privacy, ultra-low resource usage, mobile optimization | High customization and self-deployment flexibility | High customization and self-deployment flexibility | Self-hosting option with privacy features |
| Best For | Small applications | Budget-conscious developers prioritizing value and accessibility | Budget-conscious developers prioritizing value and accessibility | Developers seeking balanced multimodal features with moderate pricing |
Here is my solid advice for using Llama 3.2 1B Instruct effectively:
llama-3.2-1b-instruct, and get a clean chat interface.Strengths:
Limitations:
To answer our initial question: no, Llama isn’t quite as bad as it’s made out to be. But it probably didn’t deliver to its hype either.
Llama 3.2 1B Instruct is excellent for what it is: an ultra-lightweight, fast, and affordable coding assistant. But don’t expect it to replace more capable models. Use it for simple tasks and learning, but always be prepared to manually fix and improve the generated code.
In other words, you must be a developer to use this. It’s a great tool in your toolkit, just not the only tool you’ll need.

Build a CRUD REST API with Node.js, Express, and PostgreSQL, then modernize it with ES modules, async/await, built-in Express middleware, and safer config handling.

Discover what’s new in The Replay, LogRocket’s newsletter for dev and engineering leaders, in the March 25th issue.

Discover a practical framework for redesigning your senior developer hiring process to screen for real diagnostic skill.

I tested the Speculation Rules API in a real project to see if it actually improves navigation speed. Here’s what worked, what didn’t, and where it’s worth using.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

