The most interesting applications are those in which users interact with vast amounts of data. One example is Facebook, where users are continuously scrolling newsfeeds. Users have numerous friends and many items in their feed, such as shared posts, liked photos, etc. It’s not practical for the web app or mobile app to ask the API server for all of the new items at once. The HTTP response payload would be very large, resulting in slow page loading.

Pagination is a strategy for addressing this issue; it involves slicing the data a client asks for into “pages”. The resulting payloads are small and quick to resolve, translating to big performance gains for the client. Cursor-based pagination is a popular variant in which the server will send “cursors” representing the position of each item in the dataset. The client uses these cursors to request data from the server and to specify a limit on the amount.
There are a couple of constraints when using cursor-based pagination, compared to simple page based. For example, clients cannot pass in a random page number in the middle of the dataset. In contrast, it offers big advantages like supporting new data insertions into the dataset during paging. Going back to the Facebook example, when a user scrolls through a newsfeed, new items — like a new reaction to a post — could enter the feed at any time. This makes the API schema more complex compared to what would be needed for a simple list.
In this article, we’ll explore the features and benefits of cursor-based pagination. Then, we’ll demonstrate how to implement a basic Node.js GraphQL server which provides a paginated dataset using the Apollo Server package and a simple database access layer. GraphQL is a standardized API format that enables clients to explicitly ask for specific data.
Jump ahead:
To provide cursor-based pagination, there are some factors that must hold true. One of the most important aspects is that your data must contain a unique sequential column to base cursors on. Without one, ordering won’t be guaranteed for the API so your client could receive different results with each request!
For example, a username property could work as a unique sequential column since this property is likely to be marked as unique in your database schema and can be easily ordered alphabetically. An example of another property that might work is the created_at timestamp:

Our paginated API operation will accept arguments for how many items to return, first, and the cursor to start querying the dataset with, after:
friendsConnection(first: Int!, after: Cursor): FriendsConnection!
Every API response payload will hold “metadata” of the current page, aptly named pageInfo. Several properties exist such as:
hasNextPage: if there is a next pagehasPreviousPage: if there is a previous page (optional)totalCount: total count of pages (optional)Taking these properties of cursor-based pagination into consideration, let’s begin setting up our development environment.
To start, let’s set up our workspace by installing Node.js. Next, we’ll create a new directory for our project:
mkdir graphql-cursor-pagination-node-js-server
Now, move into the new directory, like so:
cd graphql-cursor-pagination-node-js-server
Our Node.js server will use the Apollo Server and LokiJS npm packages. Since these are both external packages, we’ll use the npm CLI and require a package.json file:
# Create an npm package.json file npm init -y # Download the required npm packages npm i @apollo/[email protected] [email protected] [email protected] # Create the file our code will go touch index.js
Then, we’ll add a start script to our package.json file:
...
"scripts": {
"start": "node index.js"
},
...
Now that our project is set up, let’s take care of the data.
We’ll create a simple NOSQL database collection containing Luke Skywalker’s contacts (his friends and foes). Along with this “Star Wars friends” collection, we’ll include a function to query the data and make it accept the parameters that our API server will eventually use.
Our sample dataset has 10 items and a unique sequential column, Username:
| Name | Username | | --------- | -------------------- | | Han Solo | a-shot-first-2000 | | R2D2 | b-robot-master-3000 | | Leia | c-rope-swinger-9000 | | Yoda | d-little-green-2000 | | Chewbacca | e-furry-monster-3000 | | C-P30 | f-robot-villain-9000 | | Vadar | g-dark-helmet-2000 | | Maul | h-red-guy-3000 | | Obiwan | i-hood-man-9000 |
For our cursor-based pagination demo, we’ll use the LokiJS in-memory database because it requires zero setup. The getFriends function includes the usernameCursor argument, which the client will use to ask for additional items besides just the Username.
To get the list of Luke’s friends during pagination, we’ll need to set up a function to query the LokiJS database.
Let’s write a function to seed the database:
import loki from "lokijs";
// Initial setup
function createDatabaseAndCollection() {
const db = new loki("sandbox.db");
const friends = db.addCollection("friends");
return friends;
}
// Seed the database with 10 friends
function seedData(collection) {
collection.insert({ name: "Han Solo", username: "a-shot-first-2000" });
collection.insert({ name: "R2D2", username: "b-robot-master-3000" });
collection.insert({ name: "Leia", username: "c-rope-swinger-9000" });
collection.insert({ name: "Yoda", username: "d-little-green-2000" });
collection.insert({
name: "Chewbacca",
username: "e-furry-monster-3000",
});
collection.insert({ name: "C-P30", username: "f-robot-villain-9000" });
collection.insert({ name: "Vadar", username: "g-dark-helmet-2000" });
collection.insert({ name: "Maul", username: "h-red-guy-3000" });
collection.insert({ name: "Obiwan", username: "i-hood-man-9000" });
}
// Returns friends starting at `usernameCursor`
export function getFriendsByUsername(collection, usernameCursor, desc = false) {
return collection
.chain()
.simplesort("username", { desc })
.find({ username: { $gt: usernameCursor } })
.data();
}
// Get the total count of the friends collection
export function getFriendsTotalCount(collection) {
return collection.count();
}
const friendsCollection = createDatabaseAndCollection();
seedData(friendsCollection);
console.debug(getFriendsByUsername(friendsCollection, "b-robot-master-3000"));
Now, let’s test the new function works by logging the debug function call:
❯ npm start > [email protected] start > node index.js [ { name: 'Maul', username: 'h-red-guy-3000', meta: { revision: 0, created: 1683111281089, version: 0 }, '$loki': 8 }, { name: 'Obiwan', username: 'i-hood-man-9000', meta: { revision: 0, created: 1683111281089, version: 0 }, '$loki': 9 } ]
Servers offering a GraphQL API can support cursor-based pagination. There are different ways to implement this in GraphQL but the most popular option is the Relay GraphQL Cursor Connections Specification. This specification comes with benefits. Namely, clients can easily make their way around your GraphQL API and learn how to paginate through the API server data quickly.
N.B., here’s a basic introduction to GraphQL
During GraphQL development, we have the benefit of a shared schema between the server and client. Designing the schema first helps us get buy-in from the client and is also useful for establishing what we need to build.
The Relay pagination specification will help us create the GraphQL schema. This is known as “schema-first” design; this development pattern is also referred to as the “Dream Query”.
Let’s define our GraphQL schema inside the typeDefs variable. Later, we’ll use this in the GraphQL server bootstrap:
# #graphql will help IDEs recognize this as a GraphQL schema
export const typeDefs = `#graphql
scalar Cursor
type PageInfo {
hasNextPage: Boolean!
}
type Friend {
name: String!
username: String!
}
type FriendEdge {
cursor: Cursor!
node: Friend!
}
type FriendsConnection {
edges: [FriendEdge!]!
pageInfo: PageInfo!
}
type LukeSkywalker {
name: String!
username: String!
friendsConnection(first: Int!, after: Cursor): FriendsConnection!
}
type Query {
lukeSkywalker: LukeSkywalker!
}
`;
In order for our schema to follow the Relay pagination specification it must meet the following criteria:
first and after and return a Connection objectConnection objects contain edges and pageInfoedges contain the datum in question, node, and its cursorPageInfo contains metadata related to the current page like if there is a next page, hasNextPageWith the function to query the database and our GraphQL schema now implemented, the final piece is the server itself. We need to bootstrap the Apollo Server, give it our schema, and implement the resolver. Our resolver will pass the arguments sent to the server to the database accessor, returning the list of friends needed for the response:
import { ApolloServer } from "@apollo/server";
import { startStandaloneServer } from "@apollo/server/standalone";
const resolvers = {
Query: {
lukeSkywalker: () => {
return {
name: "Luke Skywalker",
username: "luke-skywalker-1000",
// Implement the algorithm listed on the Relay specification page
// <https://relay.dev/graphql/connections.htm#sec-Pagination-algorithm>
friendsConnection: (args) => {
const { first, after } = args;
if (first < 0) throw new Error("first must be positive");
// Get the friends using the given cursor
const friendsByUsername = getFriendsByUsername(
friendsCollection,
after
);
// calculate edges based on the given limit
const edges = friendsByUsername.slice(0, first);
// map the data needed for the response
return {
edges: edges.map((friend) => ({
cursor: friend.username,
node: friend,
})),
pageInfo: {
hasNextPage: friendsByUsername.length > first,
},
};
},
};
},
},
};
const server = new ApolloServer({
typeDefs,
resolvers,
});
const { url } = await startStandaloneServer(server, {
listen: { port: 4000 },
});
console.log(`🚀 Server ready at: ${url}`);
N.B., for more information about the Apollo Server, see the official docs
Now, test that everything works by running the server using the start command:
❯ npm start > [email protected] start > node index.js 🚀 Server ready at: <http://localhost:4000/>
With our server implemented, let’s query it with some sample queries that a client would send.
First, open the link to localhost:4000; this will open the Apollo Sandbox:
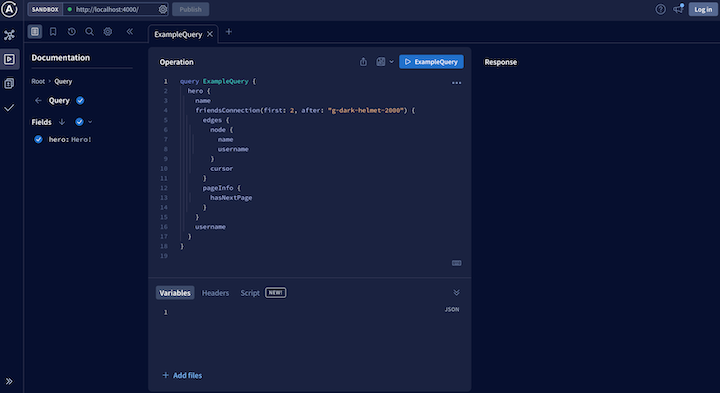
Next, copy and paste the example query into the “Operation” field:
query ExampleQuery {
hero {
name
friendsConnection(first: 2, after: "g-dark-helmet-2000") {
edges {
node {
name
username
}
cursor
}
pageInfo {
hasNextPage
}
}
username
}
}
Click ExampleQuery to get the paginated friend data from the server; you should see the last two items:
{
"data": {
"hero": {
"name": "Luke",
"friendsConnection": {
"edges": [
{
"node": {
"name": "Maul",
"username": "h-red-guy-3000"
},
"cursor": "h-red-guy-3000"
},
{
"node": {
"name": "Obiwan",
"username": "i-hood-man-9000"
},
"cursor": "i-hood-man-9000"
}
],
"pageInfo": {
"hasNextPage": false
}
},
"username": "luke-skywalker-1000"
}
}
}
Voila! It works.
Cursor-based pagination is helpful for slicing data into “pages” and improving the performance of your application. It allows you to send cursors with each item in the dataset, representing its position, and then use these cursors to ask the server for the data you want.
When comparing cursor-based pagination to simple page-based pagination, there are a few more constraints and complexities. For example, the client needs to keep track of the “cursor” and be able to use it (instead of relying on page numbers, which may be easier to derive) when querying the server. However, one big advantage of using cursor-based pagination is that it supports new data being inserted into the dataset during paging.
If you want to learn more about GraphQL and cursor-based pagination, there are several resources available. Check out this StackBlitz project where you can run the entire example in your browser, the GitHub repository, or the GraphQL and Relay pagination docs. You can also refer to the Apollo docs for more information on the Apollo Server package.
Happy coding!
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.


LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly aggregating and reporting on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.

Learn how to protect full-stack projects from NPM supply chain attacks with a practical security checklist.

Explore 15 essential MCP servers for web developers to enhance AI workflows with tools, data, and automation.

Learn how contrast-color() automatically picks accessible text colors using native CSS, without JavaScript.

Learn how to build a harness-style AI workflow using Claude Code with specialized Dev, QE, and Ops subagents, gated handoffs, MCP telemetry, and LEARNING.md.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

