
This post is the third in “How CSS Works” — a series where we dive deep into the fundamental building blocks of CSS that can sometimes feel like black magic. Regardless of how you author your CSS, it’s always good to know that your stylesheets’ “runtime” so that you can write efficient, scalable CSS.
Here’s the first two posts in the series:
Today we’re gonna dive into another one of those “black magic” parts of CSS. Toying with z-index often feels like throwing a higher number at the wall and seeing what sticks.
But if we peel back the layers on z-index (pun intended 😂) and take a look at the rules that govern it?
We’ll see that it’s not as scary as we thought it was.
At the end of the day, the screens we use in the browser are two-dimensional flat surfaces with a bunch of pixels. But if you’ve been around the web for any time it’s likely that you’ve often had a “three-dimensional” experience. For example, you can click a button and open up a modal or have a tool-tip display “above” their triggers.
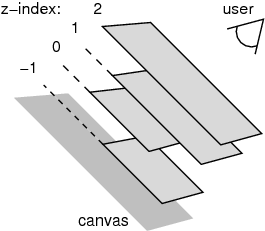
If you assume that the user is looking “into the screen” and imagine that the screen is a portal into a three-dimensional world you can start to visualize what this three-dimensional space within the browser looks like. For starters, if we visualized this space as a room, the “wall” that’s “farthest away” is known as the “canvas”.
When painting pixels onto the screen, the browser makes sure that the pixels that are closest to the canvas (or farthest from us) get painted first. Then it progressively continues to paint the elements “closer” to the user, overwriting the previously painted pixels.
The z-index property refers to an element’s paint order in this three-dimensional browser illusion. By default, all elements have a z-index of 0, and the browser paints in DOM order. However, z—index actually gives us fine-grained control over when an element is painted. By assigning a higher z-index we can make the element paint in such a way that it is “closer” to the user while assigning a lower (or negative!)z-index lets us paint the element closer to the canvas.
While digging through the CSS Position & Layout Spec, I found this helpful diagram to visualize how z-index layers look to the user.
If we only look at this behavior of z-index, it’s easy to be tempted to think that it’s 100% straightforward: higher z-index equals closer to the user, lower z-index is farther away. However, there’s a couple nuances to z-index that cause a lot of confusion.
The first caveat attached to z-index is that it must be on a positioned element in order to take effect. This means that z-index can only be used to change stacking order if you’ve set a position other than static. In any situation where you haven’t set a position on an element, z-index will have zero effect.
The waters around z-index get even muddier when we consider the second caveat of z-index: it only applies to an elements positioned within a stacking context.
A stacking context involves an HTML node and all of its children. The HTML element at the root level of the stacking context can be referred to as the stacking root.

The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
The default stacking context (or the “root stacking context”) for the document has the html tag as its’ stacking root, and all elements belong to this stacking context by default. However, any HTML node can also be the root element of a “local stacking context”.
Here are a few ways that you can designate an element as the root of a new local stacking context:
position: absolute or position: relative along with any z-index other than auto on an element.position: fixed or position: sticky on an element.opacity that is less than 1 on an element.transform or will-change on an element.If you want to see a more comprehensive list of ways to create new stacking contexts, check out this article on MDN.
As an example, let’s imagine three trees of HTML nodes, visualized as three stacks. In the diagram below, the bottom of each stack is the parent HTML node, and the child elements are stacked on top (kinda an “upside-down” representation of the HTML tree). Let’s also pretend that each of these elements are direct children of the body tag.
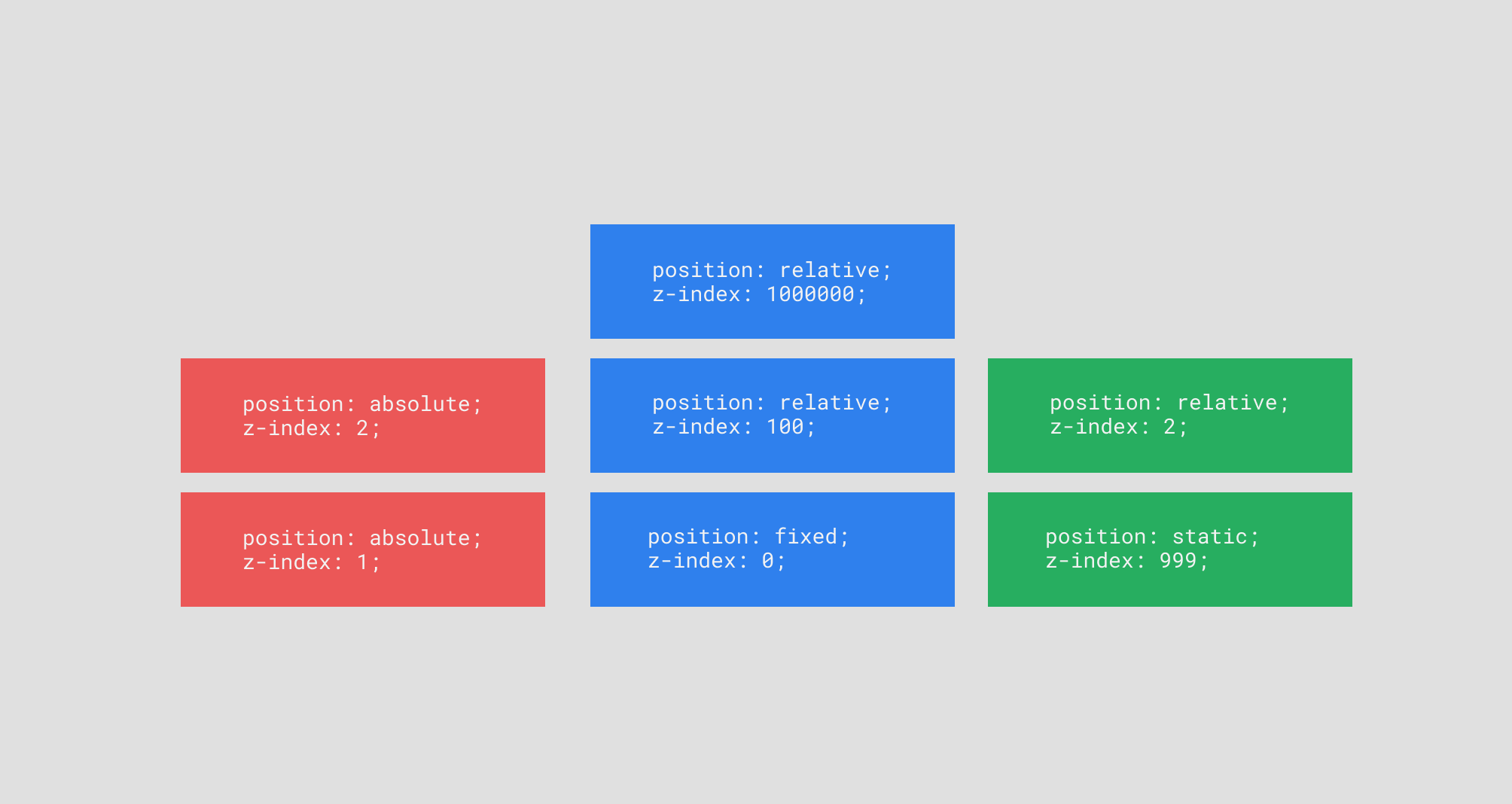
If we previewed these HTML elements in the browser, it would look something like this:
Notice anything interesting?
First off, why is blue-child-2 below anything else? It has a z-index of one million, so it should be on top, right?
In addition, why is green-child-1 showing up on top of everything, even though it has a z-index of 2? Didn’t we say that higher z-indexes “win” over lower z-indexes?
Let’s start with green-child-1. Since its’ parent element — green-parent — has a z-index of 999, we would expect green-parent to also be above everything else. But if we recall back to our first caveat of using z-index, it has no effect on statically positioned elements. This means green-child-1 is part of the root stacking context, and it is measured up against red-parent and blue-parent, the only other 2 elements in the root stacking layer. It has a higher z-index than both of those, so it shows up on top.
Understanding that red-parent and blue-parent each create their own local stacking contexts helps us also figure out why blue-child-2 shows up below red-parent even though its’ z-index is way higher. Since z-index only controls an element’s position within its local stacking context, blue-child-2 will definitely be above all of blue-parent’s children. But red-parent has a higher z-index than blue-parent, all of the elements inside of red-parent will display higher than blue-parent, regardless of what their z-index is.
In order to make blue-child-2 display above red-parent we would actually have to change our HTML structure to get blue-child-2 out of its current local stacking context & into the root stacking context (or at least to a stacking context that is above red-parent).
Extractions like this can often be tricky (even treacherous) in a larger application, especially when you’re trying to manage things like semantic HTML structure, accessibility, and modular component architectures.
You’ll often see many component libraries that implement their layer-heavy UI (stuff like tool-tips and modals) by appending elements to the body tag instead of where you included the component—this is largely to get around these stacking context “gotchas”. Doing so guarantees that z-index on components that heavily rely on layers is always in reference to the root stacking context, and thus they can set a z-index of something like 1000 and trust that it will display on top of most elements.
Using z-index can be tricky in a few scenarios, but when we know the rules of how it works under the hood we find that it actually behaves quite predictably. I would guess that 99% of the confusion around z-index stems from misunderstanding about the two caveats that we discussed.
As a quick refresher, here they are again, in TL;DR fashion.
z-index only works on elements that have a position value besides static.z-index only applies to an elements’ position within the stacking context that it belongs to.I hope that knowing the internals of z-index gives you confidence when approaching multi-layered UIs and their various pitfalls. I know that studying z-index and stacking layers has been very helpful to me in feeling systematic about the way I go about my UI development—knowing what number to assign is a big improvement over just throwing z-index values against the wall.
 Monitor failed and slow network requests in production
Monitor failed and slow network requests in productionDeploying a Node-based web app or website is the easy part. Making sure your Node instance continues to serve resources to your app is where things get tougher. If you’re interested in ensuring requests to the backend or third-party services are successful, try LogRocket.

LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.

Write agent-friendly API documentation with OpenAPI, clear schemas, workflow guidance, and llms.txt for safer AI automation.

Local AI proxy tutorial for detecting, masking, and rehydrating PII before prompts reach cloud LLMs.

Learn how Graph RAG uses connected knowledge structures to improve retrieval beyond simple text similarity.

Learn how sibling-index() enables clean, JavaScript-free stagger animations using native CSS.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now
