Retrieval Augmented Generation (RAG) is often presented as a simple pipeline: split documents into chunks, embed them into vectors, and retrieve similar text when a user asks a question. This works well for many use cases, but similarity-based retrieval has limitations.

Traditional RAG treats knowledge as a flat collection of independent fragments. Each chunk exists in isolation, and retrieval relies on semantic similarity rather than explicit relationships between ideas. This can lead to:
Graph RAG introduces a different mental model. Instead of retrieving only based on similarity, we organize knowledge as a graph of connected nodes. Chunks, entities, and concepts become part of a structured network that retrieval can traverse.
In this article, we’ll build a minimal Graph RAG-style retrieval system. Importantly:
The goal is to understand how Graph RAG works at its core: structuring knowledge so retrieval follows meaningful paths instead of just matching text. Associated with this article, there is a repository with the working code: we kept it really simple and focused on the concepts we describe here.
Before writing any code, it helps to clarify what changes compared to traditional RAG (check this article for more advanced RAG techniques).
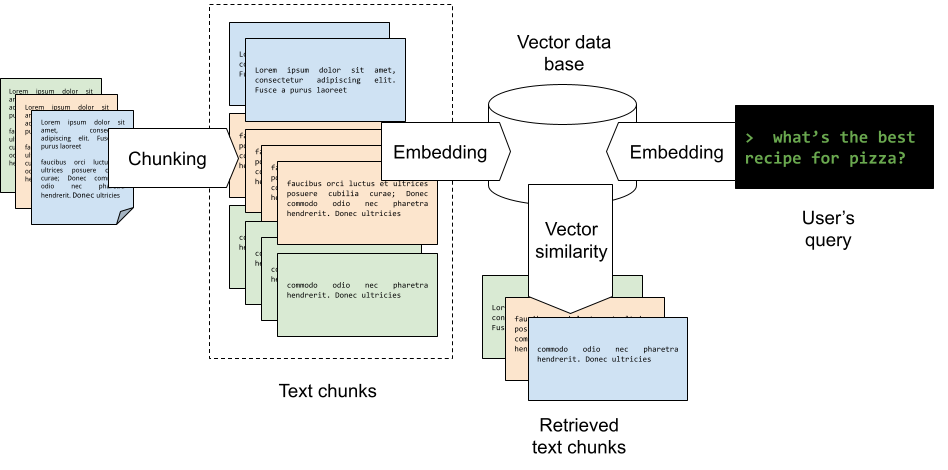
This diagram illustrates a RAG workflow where source documents are first broken into smaller text chunks through chunking, then converted into embeddings (that is a vector of floats) and stored in a vector database; when a user submits a query like “what’s the best recipe for pizza?”, the query is also turned into an embedding, compared against the stored embeddings using vector similarity to identify the most relevant matches, and the corresponding retrieved text chunks are pulled out to provide context for generating an answer.
The graph RAG pipeline has some distinctive differences: source documents are first split into text chunks through chunking, as in the original RAG, then they are processed to find the relevant entities to be extracted and become the nodes of the graph; the next step is to build the relationships between nodes, which are stored as connected nodes in a graph database; when a user query such as “what’s the best recipe for pizza?” comes in, it is converted into an embedding and matched against the graph, that is traversed finding both the nodes and the edges that connect nodes that are relevant for the user’s query.
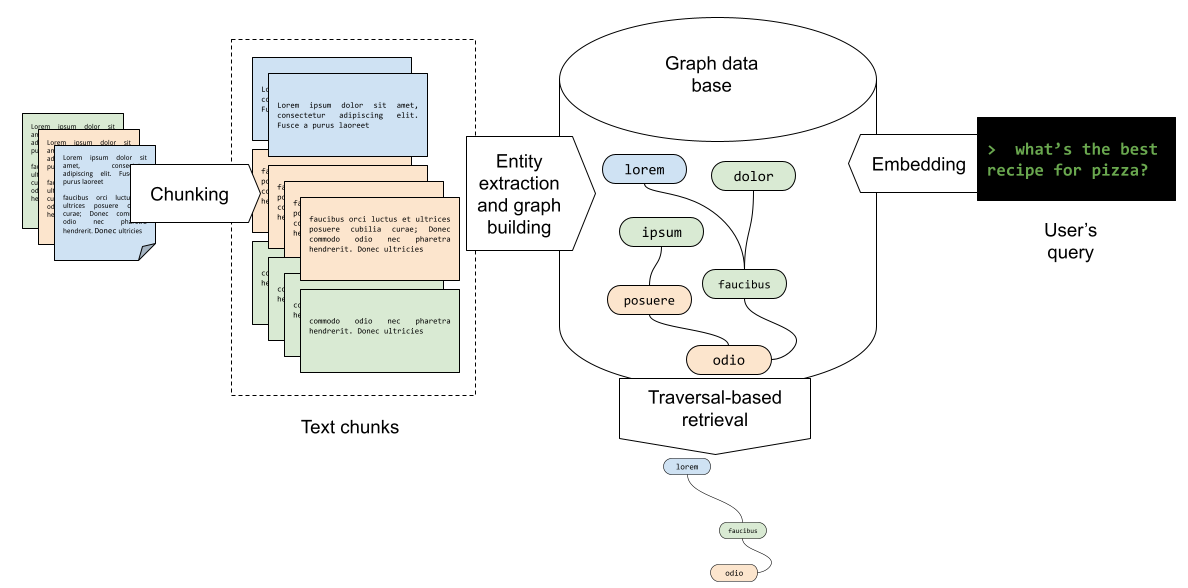
The main shift is: retrieval moves from “find similar text” to “follow relationships between knowledge units.”
A graph consists of:
In our example, we will use the following structure:
For nodes:
[Software_Component] (e.g., “My_App”, “React_Lib”, “FFmpeg”)[License] (e.g., “MIT”, “GPL_v2”, “Apache_2.0”)[Constraint] (e.g., “Must_Disclose_Source”, “Patent_Grant”, “Sublicensable”)Edges:
USES / DEPENDS_ON (Linking components)GOVERNED_BY (Linking component to license)IMPLIES / FORBIDS (Linking license to constraints)These are examples and, of course, they strongly depend on the kind of documents you intend to handle and how the concepts expressed in such documents (the nodes of the graph) are related to each other (the edges of the graph)
To make the case for Graph RAG, we need a dataset where the answer isn’t in one place, that is, a chunk of text that a traditional vector RAG is great at finding. Graph RAG is relevant when texts, and in general, concepts are as important as the links between them.
We’ll build a minimal example application that demonstrates Graph RAG on a software license compliance scenario — a domain where answers cannot be found in any single document, making it an ideal case for relationship-aware retrieval.
The application:
(Software Components, Licenses, Constraints) and relationships (USES, GOVERNED_BY, IMPLIES) using pattern matchingThis intentionally avoids production complexity. The focus is on learning the retrieval model. We’ll use Python and NetworkX for graph representation, but real systems will probably use Neo4j.
In the simple example we will describe here, the dataset consists of three short documents that together describe a license obligation chain:
documents = {
"doc1": "Our project, SuperApp, uses the Lib-X library for video processing.",
"doc2": "Lib-X is distributed under the GPL v2 license.",
"doc3": "The GPL v2 license requires that any derivative work distributed to others must have its source code made available.",
}
Each element of the array above contains a single-sentence document. We are using one-sentence documents because it is easier to track what happens by eye.
No single document answers the question “If I distribute SuperApp, must I disclose source code?” — the answer requires connecting all three. This is precisely where Graph RAG shines and where traditional keyword or vector search falls short.
Instead of generic keyword extraction, we extract typed entities and identify the explicit relationships between them.
SOFTWARE_COMPONENTS = ["SuperApp", "Lib-X", "FFmpeg", "React_Lib"] LICENSES = ["MIT", "GPL v2", "Apache 2.0", "BSD"] CONSTRAINTS = ["Must_Disclose_Source", "Patent_Grant", "Sublicensable", ...]
Relationships are extracted using regex patterns:
From the documents above, it is easy to see how the regex patterns extract the relationships.
In the most general case, this really defines the graph that is at the core of GraphRAG. For this reason, it is really important to understand which relations are present in our knowledge base that we want to track in the DB. In the code, the magic happens in the extract_entities_and_relationships function.
In the previous step, we extracted the nodes and the arcs of a graph. Now we can build it in the graph database. We construct a directed knowledge graph with four node types and five edge types. The result is a structured representation where:
This is where Graph RAG differs fundamentally from classic retrieval. Instead of asking “which chunks are similar to this query?”, we ask “what can we reach by following relationships from this starting point?”
The output of the execution is the following:
Query: 'SuperApp'
--- Vector RAG ---
1. doc1: Our project, SuperApp, uses the Lib-X library for video processing.
matched: ['SuperApp']
--- Graph RAG ---
Starting at: SuperApp
→ USES → Lib-X
→ GOVERNED_BY → GPL_v2
→ IMPLIES → Must_Disclose_Source
→ USES → FFmpeg
→ GOVERNED_BY → LGPL_v2.1
→ IMPLIES → Allow_Library_Replacement
1. doc1: Our project, SuperApp, uses the Lib-X library for video processing.
2. doc2: Lib-X is distributed under the GPL v2 license.
3. doc3: The GPL v2 license requires that any derivative work distributed to others must have its source code made available.
4. doc4: Lib-X uses FFmpeg for low-level codec operations.
5. doc5: FFmpeg is distributed under the LGPL v2.1 license.
6. doc6: The LGPL v2.1 license requires that users must be able to replace the library with a modified version.
The code in the repository shows a simple comparison between the outputs of the RAG and the graph RAG, using the same input “SuperApp” for both systems. Vector RAG returns 1 doc (the only one containing the word). Graph RAG returns 6 docs by traversing the relationship chain — no keyword overlap needed for any of them beyond the starting node. We also added a 7th document to the system with the role of “distractor”: mentions query keywords but is unrelated to “SuperApp”.
Graph-based retrieval shines when relationships matter:
If your information contains explicit conceptual relationships, modeling them directly can improve retrieval quality.
Traditional retrieval-augmented generation (RAG) follows a straightforward pipeline: a user query is embedded, matched via similarity search, and the top-k text chunks are passed directly to the language model. In contrast, Graph RAG inserts a structured reasoning layer between retrieval and generation. After interpreting the query, the system identifies relevant entities or concepts, traverses a knowledge graph to explore relationships across multiple hops, and aggregates context from both directly relevant and structurally connected information before sending it to the LLM.
This distinction is critical because similarity-based retrieval alone often overlooks context that is conceptually related but lexically different. A graph makes these relationships explicit, enabling the system to pull in supporting material, such as linked concepts, related systems, or connected documentation, that would otherwise remain isolated. As a result, the LLM operates on a richer and more coherent context, typically improving grounding, reducing hallucinations, and supporting more reliable multi-step reasoning. The core shift is that retrieval is no longer driven purely by semantic proximity, but by the structure of relationships within the underlying knowledge representation.
A useful parallel is the shift introduced by Google through its PageRank algorithm. Early search engines largely behaved like a lexical scan, effectively a “grep” over web pages, ranking results based on keyword frequency and basic matching. Google’s key innovation was to incorporate the structure of the web itself: hyperlinks became signals of authority and relevance, allowing the system to rank pages not just by what they said, but by how they were connected.
Graph RAG introduces a similar conceptual leap. Traditional RAG mirrors those early search engines: it retrieves text chunks based on semantic similarity alone. Graph RAG, like PageRank, leverages structure, in this case, relationships between entities and concepts in a knowledge graph, to guide retrieval. Instead of relying solely on surface-level similarity, it explores connections, bringing in context that is indirectly related but structurally meaningful.
In both cases, the improvement comes from moving beyond isolated content toward a network-aware perspective. Just as Google improved search quality by understanding the link topology of the web, Graph RAG enhances LLM performance by exploiting the relational topology of knowledge, enabling more comprehensive and contextually grounded results.
Graph RAG is less about new tooling and more about a shift in perspective. Instead of treating knowledge as independent chunks optimized for similarity search, we structure information as a network of connected ideas.
Notice that we never introduced embeddings or an LLM. That was intentional. Understanding Graph RAG starts with understanding structured retrieval.
LLMs can later generate answers from retrieved context, but the real power comes from how knowledge is organized. When retrieval follows relationships rather than just similarity, it becomes possible to capture deeper structure and enable more sophisticated reasoning workflows.

Learn how to protect full-stack projects from NPM supply chain attacks with a practical security checklist.

Explore 15 essential MCP servers for web developers to enhance AI workflows with tools, data, and automation.

Learn how contrast-color() automatically picks accessible text colors using native CSS, without JavaScript.

Learn how to build a harness-style AI workflow using Claude Code with specialized Dev, QE, and Ops subagents, gated handoffs, MCP telemetry, and LEARNING.md.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

