Editor’s Note: This post was updated in August 2021 to include the latest version of Node and additional benefits to going serverless.

Most web applications run on high-maintenance servers. Nowadays, software engineering teams have dedicated DevOps/infrastructure engineers to help manage, provision, and maintain these servers. Due to the associated challenges with this setup, the need to drive alternative solutions became necessary. The serverless stack shines in this regard.
As a framework, we can build both microservice and full-stack applications, freeing organizations at any scale from the process of provisioning for huge server setup, maintenance, and configuration.
How does paying for the exact resources you consume sound? The beauty of serverless as a framework is that you only have to pay an equivalent amount for the resources needed to run your entire infrastructure, indeed with radically less overhead and cost.
Serverless code is a stateless function triggered or run by the occurrence of events — for example, network events (HTTP request/response cycle). For serverless applications, function contexts bound to specific events must run before the completion of those events.
The idea here is that the state is not persisted across multiple or different function calls or contexts. Furthermore, every other new event triggered by a function call is handled in a new container instance, automatically triggered.
Not to worry, we will get to understand this later on as we flesh out our application.
For serverless applications, a piece of code — usually a lambda function — is executed based on the kind of events triggered. When this happens, resources are allocated on the fly to serve these events.
Resource allocation, in this case, is mostly relative to the amount of incoming or concurrent events or requests. This is solely determined and subsequently handled/provided by cloud providers (AWS, GCP, Azure, etc.) that offer these services.
Note: The serverless framework is vendor-agnostic, as it supports most of the popular cloud service providers.
Some of the advantages of serverless applications include:
sls deployFor other benefits for Pro accounts, we can check the link to this reference here.
For developers, the serverless framework allows them to focus less on administrative tasks and more on driving business value for their users. For organizations, the serverless stack will enable new innovations to go to market more quickly.
Due to the stateless nature of serverless applications, they may encounter cold starts leading to timeout issues. This is because functions are run inside isolated containers (spurned off or triggered by events) with different or varying contexts or environments. As such, applications may initially experience low response times, throughput, and latency.
Cold starts are analogous to starting a vehicle after staying idly parked on a spot for a long time. Issues with cold starts are related to delays by the network used to serve requests, the cloud service provider, the size of the function bundles needed to execute or run a piece of code (even poorly optimized code), and so on.
To solve these problems, there are ways to keep our functions warm. For example, we can cache event calls, usually by keeping our container instance running for some time. Additionally, we can leverage open-source libraries like serverless-webpack to handle these kinds of challenges. webpack helps in bundling and optimizing our functions, making them lightweight.
In this tutorial, we’ll be building a serverless, microservice-based application. Before we begin, though, let’s take a look at the requirements or tools we need to have installed on our machines.
To easily follow along with this tutorial, we should:
To begin developing with serverless, we have to install the CLI so we can run serverless-specific commands. To install it, we can run:
$ npm install serverless -g
Earlier in this tutorial, we explained how serverless code is executed as stateless functions. Take a look at the example below:
const handlerFunction = (event, context, callback) => {
// handle business logic code here based on the kind of request
// handle callback here
callback(error, result)
}
module.exports = handlerFunction;
Let’s review how the above serverless function is executed. The handlerFunction const is the name of our serverless function.
The event object, which is one of our function arguments, represents the information about the kind of event that would trigger our function and cause it to start executing a piece of our code.
The context object contains information about the environment our function is to be executed on (note that this is usually handled by cloud providers on our behalf).
Lastly, the callback function takes care of returning a response or an error object, usually based on the request made by user events.
Note that in this tutorial, there are other important procedures and setup processes we are not going to cover, simply because they are not our main focus. However, they are pretty important for us to be aware of when handling deployments for our serverless-based applications. They include:
As we can see above, we are specifically making reference to AWS as our cloud service provider, which subsequently means that we will be making use of AWS lambda functions and the API gateway to create our backend API.
Also note that we could likewise make use of either Azure or GCP for our use case above.
As we mentioned earlier, let us get started by setting up for local development. If we have not previously installed the serverless CLI globally, we can do so now:
$ npm i serverless -g
We can install serverless as a standalone binary for both windows and macOS/Linux.
Serverless helps in handling the hard parts for us as engineers. All we have to do is write well-architected code as stateless functions in any language that has support for serverless implementation.
Now to begin, we can create a new directory and call it serveless-example:
$ mkdir serverless-example $ cd serverless-example
We can also set up other services provided by the cloud providers in question, like databases, storage mechanisms, and other necessary configurations. In this tutorial, we will be making use of MongoDB since we’re likely familiar with it already.
Additionally, we would be setting up our API using the serverless-http package. This package acts as a middleware that handles the interface between our Node.js application and the specifics of API Gateway, so our API can look similar to an Express app.
Moving on, let’s bootstrap a serverless boilerplate application. We can do so by running the following simple command on our terminal:
serverless create --template aws-nodejs
We will get the following output with template files shown below:
Taking a look at the files generated by the starter, the serverless.yml file is used to configure our entire application — the kind of services we intend to add and how to configure the path to our routes and controllers for our application. The handler.js file contains the actual functions that would be deployed to our cloud provider to run our code logic.
Tip: We can run the
serverless helpcommand to see a list of available commands with their respective descriptions from the command line.
Moving on, let’s start fleshing out our application. Run the npm init command to generate a package.json file, then we’ll start adding other dependencies.
We will begin by installing the serverless-offline plugin. This package mirrors the environment of the API gateway locally and will help us quickly test our application as we work on it. It’s important to make sure it’s installed and listed in the “plugins” section of our serverless config file.
We should also go ahead and install the serverless-dotenv plugin, which we will be using to set up our environment variable.
To install them as dev dependencies, we can run:
npm i serverless-offline serverless-dotenv --save-dev
After the installation is complete, we can go ahead and add them to our serverless.yml file.
Plugins:
- serverless-offline
- serverless-dotenv-plugin
Now let’s install the other packages we need for our app. We will be installing body-parser, Mongoose, Express, serverless-http, and UUID. We can do so by running:
npm i body-parser mongoose express uuid serverless-http --save
After the installation process, our package.json file should look like this:
{
"name": "serverless-example",
"version": "1.0.0",
"description": "Serverless Example for LogRocket Blog",
"main": "handler.js",
"scripts": {
"start": "serverless offline start --skipCacheInvalidation",
"deploy": "sls deploy -v"
},
"dependencies": {
"body-parser": "^1.19.0",
"express": "^4.17.1",
"mongoose": "^5.7.9",
"serverless-http": "^2.3.0",
"uuid": "^3.3.3"
},
"author": "Alexander Nnakwue",
"license": "MIT",
"devDependencies": {
"serverless-offline": "^5.12.0",
"serverless-dotenv-plugin": "^2.1.1"
}
}
Now let’s create all the folders and files we need. For a microservice-based application, we can create the Model, Controller, and Services directories. After that, we can create the respective files in those directories. Note that we will be building a product API to demonstrate how to build a serverless microservice-based application in Node.js.
To create these folders we can run the following command:
mkdir Controller Services Model
After that, we can navigate the directories and create the respective files with the name products.js. After that, we can create our .env file to store our environment variables. Finally, we can go ahead and create the database config file, which will contain our database connection to a local mongo instance running on our machine. In this tutorial, we are using Mongoose as our ORM to connect to MongoDB.
Here is how our folder structure should look after we are done:
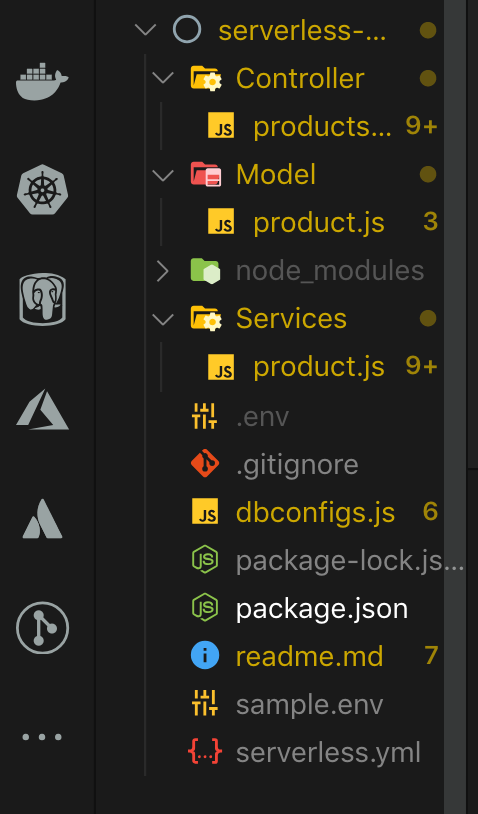
Now we can start writing some code. Inside the dbConfigs.js file, we will show how we are connecting to our database instance locally.
const mongoose = require('mongoose');
require("dotenv").config();
mongoose.Promise = global.Promise;
const connectToDatabase = async () => {
let isConnected;
if (isConnected) {
console.log('using existing database connection');
return Promise.resolve();
}
console.log('using new database connection');
const database = await mongoose.connect(process.env.MONGODB_URL, {useNewUrlParser: true});
isConnected = database.connections[0].readyState;
// return isConnected;
};
module.exports = connectToDatabase;
As we mentioned earlier, we’re using mongoose to connect to our MongoDB locally. Also, we are getting access to the MongoDB connection string by using the dotenv package. To have a look at the format of our MONGODB_URL, we can check the sample.env file.
After that, we can go ahead and set up our product schema inside the Model directory. Let us take a look at the product.js file:
const mongoose = require("mongoose");
const ProductSchema = new mongoose.Schema (
{
name: {type: String},
type: {type: String},
cost: {type: Number},
description: {type: String},
productId: { type: String },
},
{timestamps: true}
);
const ProductModel = mongoose.model("product", ProductSchema);
module.exports = ProductModel;
After that, we can go ahead and create the product.js file in the Services directory. The logic here will contain how our Model talks to the database — basically, how it handles CRUD operations. Let’s take a closer look at the file’s content:
const Product = require('../Model/product');
module.exports = {
async createProduct (product) {
let result = await Product.create(product);
if(result) {
return {
data: product,
message: "Product successfully created!"
};
}
return "Error creating new product"
},
async getAllProduct() {
let product = await Product.find();
if(product) return product;
return "Error fetching products from db"
},
async getProductById(productId) {
let product = await Product.findOne(productId);
if(product) return product;
return "Error fetching product from db";
},
};
In the file above, we have handled all interactions with the database. We called the create, find, and findOne MongoDB methods to interact with it.
And finally, we can then get to the most important part: the Controller file, which handles the core logic of our app. It basically handles how our functions are called. Here are the contents of the Controller/product.js file:
const serverless = require('serverless-http');
const express = require('express');
const app = express();
const bodyParser = require('body-parser');
const uuid = require('uuid/v4');
const dbConnection = require('../dbConfigs');
const ProductService = require('../Services/product');
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: true }));
// base url to test our API
app.get('/index', async (req, res) => {
await res.send("<h3>Welcome to the Product API for LogRocket Blog serverless Example!!</h3>")
})
// function for creating a new product
app.post('/', async (req, res) => {
try {
await dbConnection();
const data = req.body;
const {name, type, description, cost} = data;
if(!data) {
return "Please pass all required fields!"
}
const dataToSave = {name,type,description,cost,productId:uuid()};
let createProduct = await ProductService.createProduct(dataToSave);
if (createProduct) {
return res.status(200).send(
createProduct
)
}
} catch (error) {
// handle errors here
console.log(error, "error!!");
}
})
// function for getting all products
app.get('/', async (req, res) => {
try {
await dbConnection();
const allProducts = await ProductService.getAllProduct();
if (allProducts) {
return res.status(200).send({
data: allProducts
})
}
} catch (error) {
// handle errors here
console.log(error, "error!!");
}
})
// function for getting a product by Id
app.get('/:productId/', async (req, res) => {
try {
await dbConnection();
const {productId} = req.params;
const getProduct = await ProductService.getProductById({productId});
if(getProduct) {
return res.status(200).send({
data: getProduct
})
}
} catch (error) {
// handle errors here
console.log(error, "error!!");
}
});
module.exports.handler = serverless(app);
We import all necessary dependencies like the serverless-http package, which allows us to set up our serverless application like a regular Express application. Of course, we also imported our Express package and started an Express app.
After that, we import our database connection and our Services file. This file handles creating a new product, fetching all products from the database, and fetching a product by its Id. In the last line, we can see how we are wrapping our Express app with the serverless-http package.
Finally, our serverless.yml file should look like this after are done:
# Welcome to Serverless!
service: serverless-example
app: product-api
provider:
name: aws
runtime: nodejs14.17.4
stage: dev
region: us-east-1
functions:
productAPI:
handler: Controller/products.handler
events:
- http:
path: /index
method: get
- http:
path: /
method: post
- http:
path: /
method: get
- http:
path: /{productId}
method: get
plugins:
- serverless-offline
- serverless-dotenv-plugin
We have configured our app and the required services or plugins, but note that in larger applications, there may be other additional services we might have to consider adding. Looking at the functions config, we can see how we have been able to get the reference to our controller file and also set all the correct routing paths.
Note: To leverage the Serverless architecture, we can set up each route to be handled by a different lambda function. In this case, we can have a visual of how many times each route is invoked, the errors peculiar to each route, the time it takes for them to run, and how much we could save by making these routes faster.
Now that we are done with the entire setup, let’s start our app and test our APIs. To do so, we can run npm start in our terminal. When we do so, we get the following output:
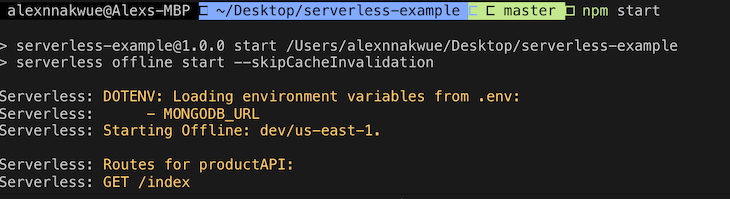

Here, we can see that all our routes and env variables are displayed for us on our terminal. Now we can go ahead and test our API. In this tutorial, we will be using POSTMAN to test. Let’s create a new product.
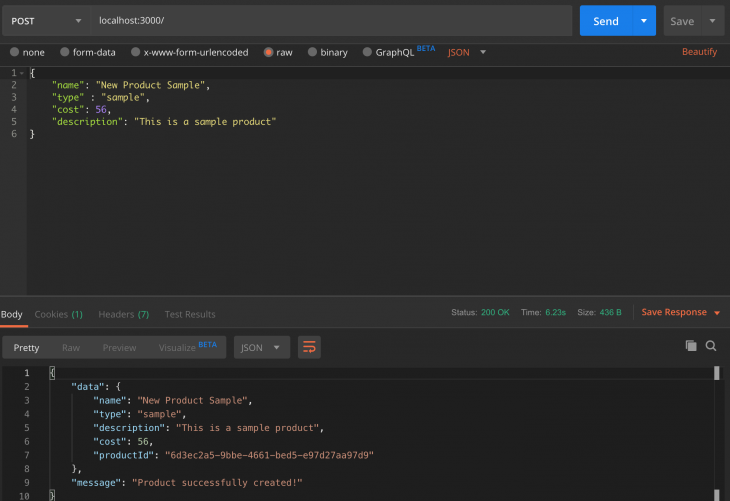
As an aside, we can go ahead and create more products and try out the other endpoints as well. The code repository for the above tutorial can be found here on GitHub.
Serverless applications have come to stay. All we have to do is write and deploy our functions with a single command, and they are live. Although there are some other pre-configuration options we didn’t cover in this tutorial, we have been able to successfully build a minimal, scalable microservice-based application leveraging serverless technologies.
While there are other ways of building serverless applications, the beauty of our approach here is that we can quickly convert an old express application to a serverless application as we are quite familiar with the current structure of our project.
Do try this setup out and let me know If you have any questions or feedback in the comments section below. Thank you!
 Monitor failed and slow network requests in production
Monitor failed and slow network requests in productionDeploying a Node-based web app or website is the easy part. Making sure your Node instance continues to serve resources to your app is where things get tougher. If you’re interested in ensuring requests to the backend or third-party services are successful, try LogRocket.

LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.

Learn how to build smooth staggered animations in CSS using modern features like sibling-index(), complete with practical examples, fallbacks, and accessibility tips.

Compare the top AI development tools and models of July 2026. View updated rankings, feature breakdowns, and find the best fit for you.

Learn how to detect unused and ghost dependencies in JavaScript projects using Knip, a project-level linter that keeps your dependency graph accurate.

Learn how Storybook MCP enables AI agents to understand your component library, generate accurate UI, and validate code using documentation, stories, and automated tests.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

