In any enterprise application, user-provided data is often messy and incomplete. A user might sign up with a “company name,” but turning that raw string into a verified domain, enriched with key technical or business contacts, is a common and challenging data engineering problem.

For many development teams, this challenge often begins as a seemingly simple request from sales or marketing. It quickly evolves from a one-off task into a recurring source of technical debt.
The initial solution is often a brittle, hastily written script run manually by an engineer. When it inevitably fails on an edge case or the API it relies on changes, it becomes another fire for the on-call developer to extinguish: a costly distraction from core product development.
From an engineering leader’s perspective, this creates a classic dilemma. Dedicating focused engineering cycles to build a robust internal tool for data enrichment can be hard to justify against a product roadmap packed with customer-facing features.
Yet, ignoring the problem leads to inaccurate data, frustrated business teams, and a drain on engineering resources from unplanned, interrupt-driven work. The ideal solution is a scalable, resilient system that can be built and maintained with minimal overhead, turning a persistent operational headache into a reliable, automated internal service.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it’s your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Solving this at scale requires a robust, fault-tolerant, and cost-effective pipeline.
This post will guide you through building such a data enrichment workflow. We’ll move beyond simple lead generation and frame this as a powerful internal tool for enterprise use cases like:
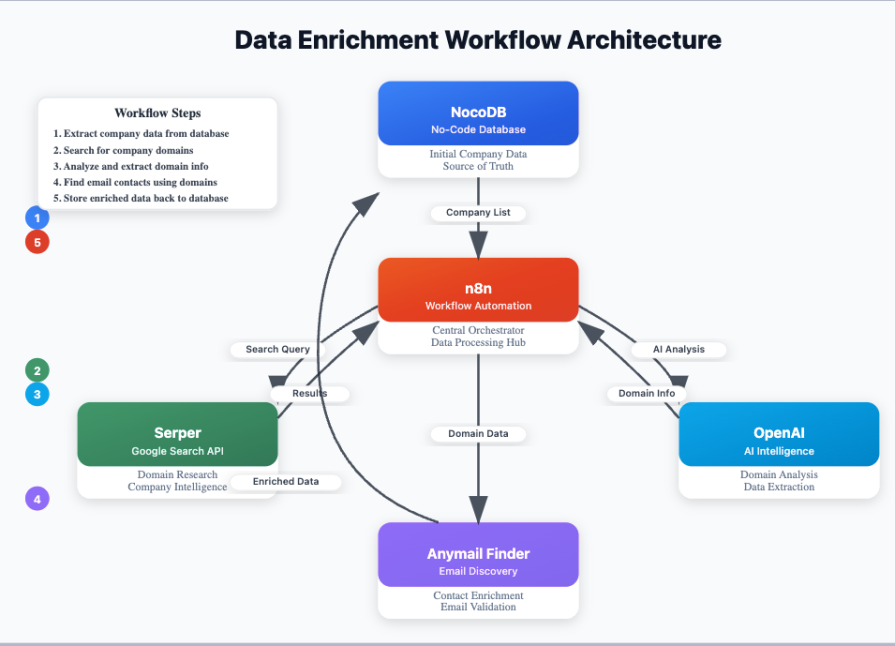
We’ll orchestrate this entire process using n8n, a workflow automation tool that shines in complex, multi-step API integrations. Our backend will be NocoDB, an open-source Airtable alternative that provides a proper relational database structure. Here’s the entire workflow if you’d like to see.
Let’s first dive into the architecture.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
A scalable pipeline relies on specialized tools for each part of the process. Here’s our stack:
Before building the workflow, we need a solid data model. In NocoDB, we’ll set up two tables:
Companies table: This table holds the initial list of company names and will be enriched with the data we find:
company_name (Text)location (Text)url (Text): The final, validated URL.domain (Text): The extracted domainfallback_emails (Text): For generic company emailsstatus (Text): A state field to track progress (e.g., Domain Found, Emails Found (Risky), Completed): This is crucial for making the workflow resumablecontacts (Link to contacts table): A “Has Many” relationshipContacts table: This will store the individual decision-makers we find:
name (Text)position (Text)email (Text)email_status (Text) – e.g., valid or risky.linkedin_url (Text)company (Link to Companies table) – The “Belongs To” side of the relationshipThis relational structure is far superior to a flat file or spreadsheet, as it correctly models the one-to-many relationship between a company and its contacts, preventing data duplication and inconsistencies: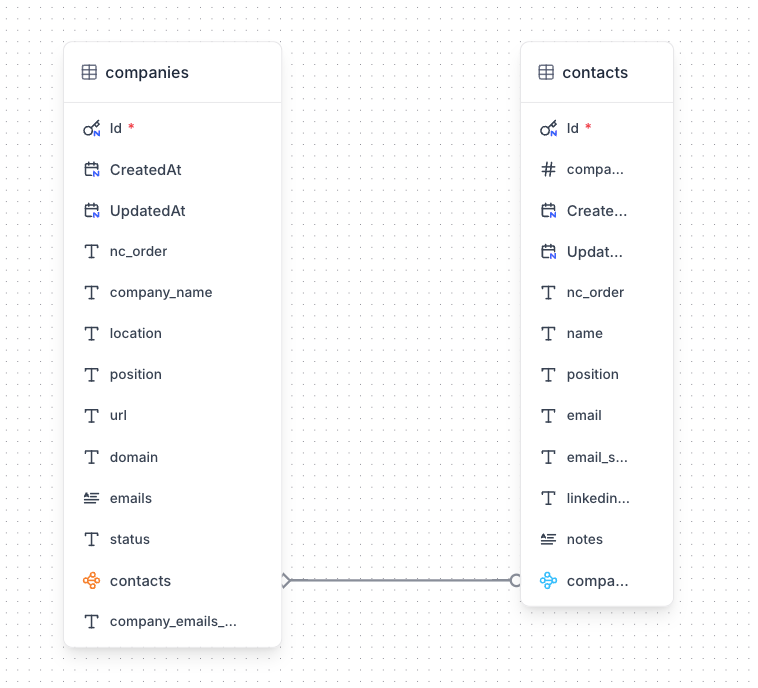
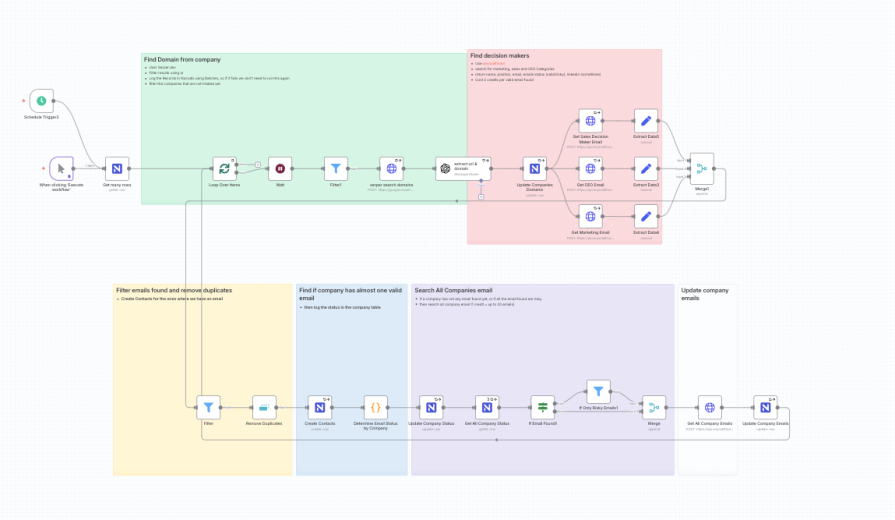
Our n8n workflow processes data in logical phases, designed for resilience and scalability.
The workflow starts by fetching unprocessed companies from our NocoDB database.
Start node), scheduled, or triggered by a webhook for real-time processing.NocoDB node): The first step is a Get Many operation on the Companies table. We add a filter to only retrieve records where the status field is empty. This simple check makes the entire workflow idempotent and resumable. If it fails midway, we can restart it without reprocessing completed entries.Loop Over Items node): To handle a large volume (e.g., 8,000+ companies) without overwhelming downstream APIs, we wrap the core logic in a loop that processes records in batches (e.g., 500 at a time) with a Wait node between iterations to respect rate limits: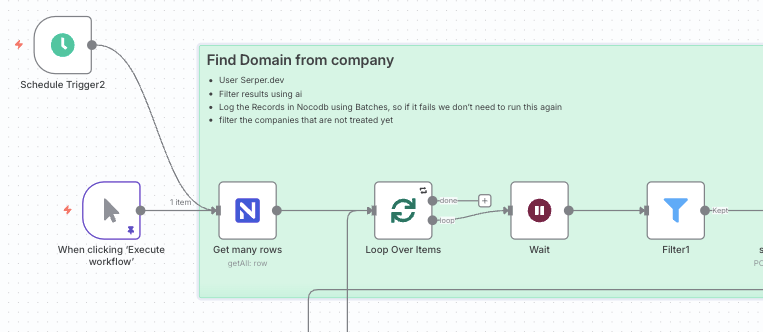
This is where we turn a simple company name into a verified website domain.
HTTP Request node): For each company, we make a POST request to the Serper.dev API. The query combines the company_name and location to get relevant Google Search results. This returns an array of potential URLs (organic results).NocoDB node): We then perform an Update operation in our Companies table using the company’s ID. We populate the url and domain fields from the OpenAI output. We also update the status field using a ternary expression: $domain ? 'Domain Found' : 'Domain Not Found':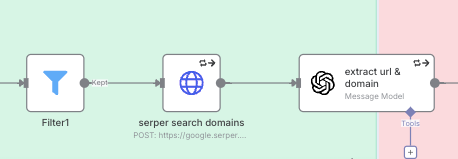
With a verified domain, we can now find key personnel:
HTTP Request nodes): We want to find contacts in several departments (e.g., Sales, Marketing, and CEO). Instead of running these searches sequentially, we branch the workflow to run three Anymail Finder API calls in parallel for maximum efficiency. Each node searches for a different decision-maker category. The API is queried using the domain if available; otherwise, it falls back to the company name.Merge and Remove Duplicates nodes): The results from the three parallel branches are combined using a Merge node. It’s possible for one person to fit multiple categories (e.g., a CEO at a startup might also be the head of sales), so we use a Remove Duplicates node to ensure each contact is unique.NocoDB node): We iterate through the cleaned list of contacts and execute a Create operation on our Contacts table in NocoDB. For each contact, we map the fields (name, position, email, etc.). Critically, we link this new contact back to its parent company by setting the company_id field. This populates the relational link we defined in our data model: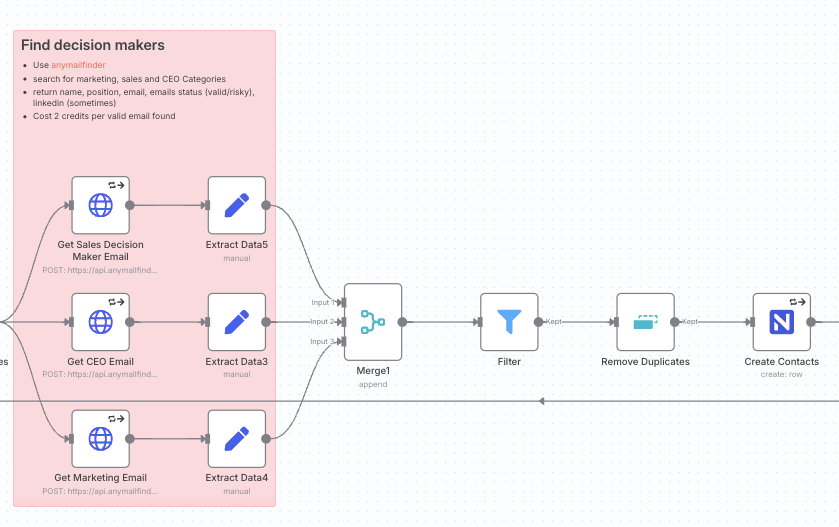
What if no decision-makers are found, or their emails are all “risky”? We need a fallback plan.
Code node): After the contact creation step, a small JavaScript snippet in a Code node analyzes the results for the current company. It checks if at least one contact with a valid email status was found and outputs a simple boolean flag, has_valid_email.If node): An If node routes the workflow based on the results. If no emails were found, or if all found emails were risky, we proceed to the fallback branch. Otherwise, the job for this company is done.HTTP Request node): For companies needing a fallback, we make one final call to a different Anymail Finder endpoint (/v2/company/all-emails/json). This fetches up to 20 generic and personal emails associated with the domain (e.g., contact@, sales@). This ensures we always get some contact information.NocoDB node): We update the Companies table one last time, populating the fallback_emails field with a comma-separated list of the emails found in the previous step and setting the final status: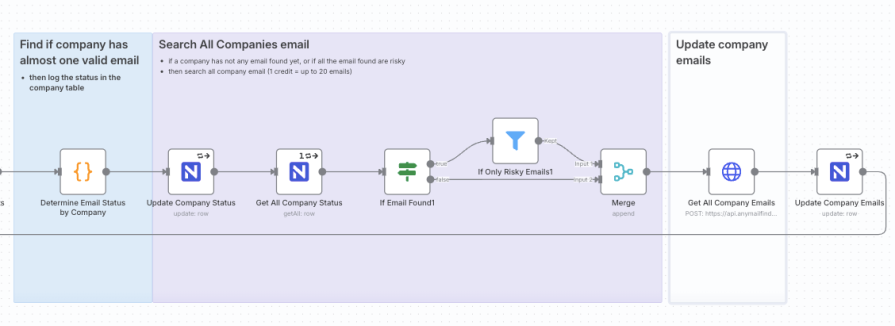
This workflow isn’t just a script; it’s engineered for production use. Here are the key principles that make it robust:
Wait node in the loop and the built-in batching options in the HTTP Request nodes ensure we don’t violate API rate limits, which is critical for cost management and stability.Building a system like this is more than just a data-cleaning exercise; it’s an investment in your team’s efficiency and a strategic asset for the business. Here are the key takeaways for engineering leaders considering a similar project:
By adopting this service-oriented mindset, you can solve a persistent business problem while building a resilient, scalable asset that frees up your most valuable resource: your engineering team’s time.
Alexandra Spalato runs the AI Alchemists community, where developers and AI enthusiasts swap automation workflows, share business insights, and grow. Join the community here.

AI-generated tests can speed up React testing, but they also create hidden risks. Here’s what broke in a real app.re

Why the future of DX might come from the web platform itself, not more tools or frameworks.

A hands-on test of Claude Code Review across real PRs, breaking down what it flagged, what slipped through, and how the pipeline actually performs in practice.

CSS art once made frontend feel playful and accessible. Here’s why it faded as the web became more practical and prestige-driven.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

