Having a good feedback loop is extremely important for developers. A properly configured project has a CI/CD pipeline that ensures the code will not break anything in the application’s logic or codebase itself by running the necessary checks, such as static code analysis and tests.

The problem here is that the errors resulting from the checks will only be seen once the code is in the repository, probably after opening a pull request. After seeing a failing pipeline, the developer has to fix the code locally and push the code to the repository once more, which ends up consuming way more time than is actually needed.
Many of the checks performed on the pipeline can be run locally on developers’ computers. However, no sane person would expect developers to execute a set of commands each time they are about to commit something.
Instead, the process should be automated so as not to disrupt the developers’ workflow and ensure that each developer runs the same checks on their machines.
Automating this process could be easily achieved if we had some mechanism that would notify us when a commit is being made. Thankfully, the mechanism already exists and is called Git hooks.
Git hooks are preconfigured custom scripts that get executed before an action is performed in Git. By default, all the installed hooks are available in the .git/hooks directory with each filename being a hook name.
There are many hooks, such as post-merge and pre-rebase, which can be used to configure really advanced setups. However, in our case, we are only interested in the pre-commit hook. All the available hooks can be found here.
The demo repository for this tutorial can be found here on GitHub.
Hooks can be added to a project by adding a properly named file in the .git/hooks directory. However, instead of installing them manually, we can automate the process by using a library called Husky.
Husky will make sure that each time the project’s dependencies are installed, the hooks are properly configured in accordance to the package.json config. This way, developers don’t have to take care of configuring the hooks on their machines by themselves.
In order to install Husky, run the following:
npm install --save-dev husky
And then add the following config to package.json:
{
// ...
"husky": {
"hooks": {
"pre-commit": "<command>",
}
}
}
With that configuration in place, Husky will execute the provided <command> every time a commit takes place.
We will also be using a library called lint-staged that lets us execute commands on the staged files. So, for example, if we had a big project with hundreds or thousands of files, but only changed one small file, it would be redundant and time-consuming to run checks on every file. Instead, only the changed files will be checked.
npm install --save-dev lint-staged
And modify the package.json to look like this:
{
// ...
"husky": {
"hooks": {
"pre-commit": "lint-staged"
}
},
"lint-staged": {
"*.ts": "<command>"
}
}
So now we have Husky configured to run the lint-staged command on the pre-commit hook.
Lint-staged configuration supports glob patterns as keys, so, as an example, we have provided the glob pattern to match all the TypeScript files by using the "*.ts" glob pattern.
Now, before a commit is performed, Husky will execute the lint-staged command, which in turn will execute the specified <command> on all the Typescript files. Once it finishes with a positive result, it will let the commit go through. Otherwise it will fail and log the error message to the console.
Assuming we have the following config:
{
// ...
"husky": {
"hooks": {
"pre-commit": "lint-staged"
}
},
"lint-staged": {
"*.ts": "eslint"
}
}
One might wonder how lint-staged makes sure that ESLint is only run on staged files when the configuration is nothing more than the eslint command itself.
ESLint, as with many other CLI tools, is invoked in the following format:
eslint [options] [file|dir|glob]*
Lint-staged makes an assumption that the provided command expects a list of space-separated absolute file paths at the end. So it takes all the absolute paths of the staged files and executes the command by appending the paths at the end.
So if we changed two files — main.ts and app.ts — lint-staged would execute the following script:
eslint project/main.ts project/app.ts
Assuming that both files are in the root directory and our project’s name is “project”.
This way, ESLint, or any other tool with similar command format, doesn’t need any additional configuration in order to work nicely with lint-staged.
After installing the necessary tools and understanding how they work, let’s add the three most popular tools and see how they integrate with lint-staged.
A linter is the most useful tool when it comes to signaling anything from code style guide inconsistencies to security issues. It is good to have it run before each commit to check one last time if everything’s as it should be. The most popular linter for JavaScript/Node.js projects is ESLint, so let’s take a look how to integrate it with lint-staged.
Since there are many ways to add ESLint to a project depending on used technologies and languages, we won’t focus on how to install ESLint itself. If you want to learn how to set it up yourself, please refer to this article.
ESLint was used in the example above, so hopefully it’s clear how to add it to the configuration.
"lint-staged": {
"*.ts": [
"eslint --fix",
]
}
The only thing that differs from the example above is that we have added the --fix parameter to allow ESLint to automatically fix any rule validation it encounters while checking the files. If the fix is not possible, the command will be aborted.
Note that the glob pattern now accepts an array of commands; this way, we can add more commands later on. The commands are executed in sequence, so it is a good practice to first provide those that have the highest chance of failing.
The importance of the consistency in code formatting can’t be overstated. It is extremely important, so it is a good idea to configure it as a pre-commit hook.
If you want to set up Prettier in your project, please refer to this article.
With Prettier configured, let’s add it to the hook.
"lint-staged": {
"*.ts": [
"eslint --fix",
"prettier --write"
]
}
Prettier’s command closely resembles the behavior of ESLint. It accepts a list of files to be executed on. By providing the --write parameters, we can be sure that Prettier will overwrite any inconsistencies found in the staged files.
Unit tests are perfect to be run before each commit. They are fast and require no specific setup. Integration and end-to-end tests should be run on a dedicated CI/CD pipeline, since they require a specific environment to be set up beforehand and usually take a long time to run.
There are many libraries that we can use to write unit tests with. Here, we use Jest. Here’s an article on how to configure Jest.
In order to make integrate Jest’s command with lint-staged, we have to provide a few parameters:
"lint-staged": {
"*.ts": [
"npm run lint -- --cache",
"jest --bail --passWithNoTests --findRelatedTests",
"prettier --write"
]
}
First, we set the --bail parameter, which makes Jest quit instantly after finding an error.
Then we provide the --passWithNoTests parameter, because some commits may actually contain no changes related to unit tests. Jest expects at least one test to be run, otherwise it throws an error.
The last parameter, --findRelatedTests, is the most important one. It accepts a list of space-separated files that will be supplied by lint-staged. So, if we changed the main.ts file, all the tests depending on the code coming from this file would be executed.
Please note that the --findRelatedTests parameter has to be last because lint-staged will supply the staged files’ paths at the end of the command.
Also note that executing unit tests is actually a second executed command in the sequence since it is unnecessary to run Prettier when we are not sure that the code passes the tests.
Commit messages are the description of changes the commit consists of. It is always a good idea to have them written in a unified fashion for many reasons, which are explained here.
There’s a tool called commitlint that does all the heavy lifting for us; all we have to do is integrate it into our existing setup.
In order to install the package, run:
npm install --save-dev @commitlint/config-conventional @commitlint/cli
And after installation, create a config file named commitlint.config.js with the following content:
module.exports = {
extends: ['@commitlint/config-conventional']
};
This time, we are going to use the commit-msg Git hook. We have to edit the Husky config in our package.json file, like so:
{
// ...
"husky": {
"hooks": {
"pre-commit": "lint-staged",
"commit-msg": "commitlint -E HUSKY_GIT_PARAMS"
}
},
}
There are many rules available for teams to choose their commit message patterns. With this config in place, each time we commit something, the commit’s message will be validated.
After setting everything up, we can commit our changes to see if everything’s working as it is supposed to.
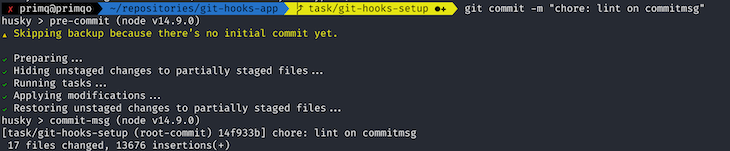
Since every check was successful, the commit has passed and is now ready to be pushed to the remote repository.
If, for whatever reason, you need to skip the checks, there’s an option --no-verify that does exactly that. An example:
git commit -m "Quick fix" --no-verify
By setting up Git hooks, we can be sure that the code pushed to the repository meets the expected standard. There is, of course, a way to skip all the locally run checks, so Git hooks can’t be dependent upon when it comes to code quality. They are not a replacement for CI/CD pipelines, but rather a way to receive feedback about the code before it is committed, significantly reducing the time needed to fix the discovered issues.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now
This guide walks you through creating a web UI for an AI agent that browses, clicks, and extracts info from websites powered by Stagehand and Gemini.

This guide explores how to use Anthropic’s Claude 4 models, including Opus 4 and Sonnet 4, to build AI-powered applications.

Which AI frontend dev tool reigns supreme in July 2025? Check out our power rankings and use our interactive comparison tool to find out.

Learn how OpenAPI can automate API client generation to save time, reduce bugs, and streamline how your frontend app talks to backend APIs.


