On some level, all applications are just nifty interfaces for databases. Just think about it — a tweet, a facebook post, an instagram comment — each of these is just a row in a database somewhere.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
For me as a front-end developer, learning a bit of SQL (the language used for database management) resulted in a small revelation: so this is where it ends. Each user’s journey from a login screen, through a search bar, smooth animations, dismissing a nasty popup, looking at an ad, until finally arriving at the piece of information they needed.
In the end it’s just a line like this one:
sql SELECT * FROM movies WHERE id='42';
It says: “Select all fields, from table called movies, where the field called id has value of 42”.
So what’s the result of this whole endeavor? A movie, a user, a book* We simply call it… an entity. It’s quite philosophical, isn’t it?
An entity is “a thing with distinct and independent existence”, according to a dictionary. And the management of entities, in a general form, is called CRUD.
CRUD stands for Create, Read, Update, Delete. It’s the basic set of operations needed to manage any collection of data.
Let’s have a look at how a simple set of CRUD functions might be implemented.
The data will be an array, and there’s just one requirement which every item in this array must meet — a unique id. The array might look like this:
const data = [
{id: 1, name: 'Foo'},
{id: 2, name: 'Bar'},
]
Let’s tackle creation first. That’s simple — it’s just adding an entity (a “row”, in database language) to the array (a “table”):
const createEntity = (entity, data) => [entity, ...data]
Nice. Next up — reading a single entity, by a given id:
const getEntity = (idToFind, data) => data.find(
({ id }) => id === idToFind
)
Updating an item is the most complicated of the lot:
const updateEntity = ({ id, changes }, data) => {
const entity = getEntity(id, data)
if (entity) {
const dataCopy = data.slice() // in order to keep the original array intact
const itemIndex = dataCopy.findIndex(({ id: _id }) => _id === id)
dataCopy[itemIndex] = { ...dataCopy, ...changes }
return dataCopy
}
return data
}
And lastly, deletion:
const deleteEntity = (id, data) => data.filter(
({ id: _id }) => _id !== id
)
The function above might seem unnatural — why is the action of removing accomplished by filtering? These examples follow a functional style in programming — they are not mutating the original data array, but returning a copy of it. Such an approach is less error-prone and more modular — each function is a self-contained operation, not relying on any external state.
This set of functions is okay, but not complete for a real-world use. There are no functions for handling multiple items in a single operation. Also, what about a function that is like updateEntity, but which will create an entity if one is not found?
Lastly, storing the data as an array is suboptimal performance-wise at larger scale. It’s as if you had all your stuff in unlabelled boxes and had to open (at most) all of them when searching for something. It’s way easier to just label the boxes — which means using an associative array, aka: an object.
Surely, someone somewhere must’ve already written an optimized functional-style CRUD toolset?
createEntityAdapterIt so happens that in an (arguably) recent release of the amazing redux-toolkit, a new API was added, called createEntityAdapter.
This is great, because entity management is an area of much wheel-reinvention in frontend development. The simplification that redux-toolkit brought with this new API is like a breath of fresh air.
And if the experience of repetitively writing CRUD code is not something you relate to, then a future without it is worth installing from NPM.
As every developer knows, the best way to learn something is to build something.
The project here will be very simple, yet it will represent the core of most web apps.
The result will look like a nice and fairly complicated web app that met a sandblaster on the way to work, but fell into a pool of fresh water so it doesn’t look too gruesome (you’ll see what I mean).
Bare-bones, pure-business-logic, brutalist learning material. Or what we might call an internal company tool in some cases.
Here’s how it looks like:
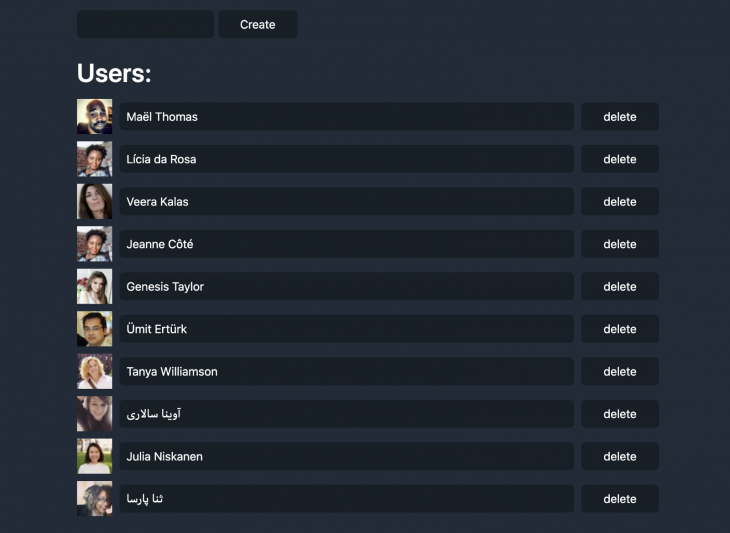
It displays a list of users (read), allows for new user creation, as well as deletion and update Simples.
The following assumes basic familiarity with Redux and React. If the former is completely new to you, it might be worth to read this part of the official docs. I’ll link to specific commits on Github, but the most relevant bits will be reprinted in this post, if cloning git repositories isn’t your thing.
Here’s the repository. For a quick start just clone it, install all that we’ll need on this short journey, and start the server:
$ git clone [email protected]:adekbadek/crude.git $ cd crude $ npm install $ npm start
After this set of spells is complete, you should be able to marvel at the site at http://localhost:1234.
We’re going to go commit by commit here, so this list is as good as a table of contents.
Apart from our obvious friends Redux & React, parcel is used for bundling code, and water is added so that our eyes don’t fall out from looking at an un-styled website.
All this boiler-platey code is added in this commit.
Now onto the important parts, which are in here. The store.js file is super small, because all the heavy lifting is outsourced to @reduxjs/toolkit — all the developer has to bring to the table are understanding and copy-pasting skills:
const usersAdapter = createEntityAdapter()
Notice that createEntityAdapter does not require any arguments.
It does not even care how how the entity’s named.
The result of calling this function is a toolbelt of CRUD functions, of which there are more than four — though in this app only the most basic will be used.
const usersSlice = createSlice({
name: 'users',
initialState: usersAdapter.getInitialState(),
reducers: {
usersAddOne: usersAdapter.addOne,
usersAddMany: usersAdapter.addMany,
userUpdate: usersAdapter.updateOne,
userRemove: usersAdapter.removeOne,
},
})
The call to createSlice is a little piece of added complexity which does not directly relate to entities. This is because createEntityAdapter returns multiple “case reducers” — which are single-action-handling reducers.
In the classic form of redux there’s usually a single reducer, with a switch statement handling multiple cases. The slices-based flavor of redux is arguably a bit simpler than classic one, and more akin to the functional paradigm in programming.
In order to create a user, the usersAddOne action has to be dispatched:
dispatch(
actions.usersAddOne({
id: String(Math.random()),
name: newUserName,
})
)
As you can see, a random id is assigned.
This is okay as long as the data is stored locally (not sent to a server). The implications of having a server and, in general, writing CRUD for a real-world application, are described in the last section of this post.
Reading data is often called selecting it — remember the SQL snippet at the beginning of this post?
The entity adapter has a method called getSelectors, which has an optional argument — a function that will point it to a specific slice of the state. In our case, the state will look like this:
{
users: {ids: [], entities: {}}
}
Hinting the selector-getting logic at the whereabouts of the users slice is quite simple. Then:
const selectors = usersAdapter.getSelectors(state => state.users)
The getSelectors method returns five selectors, most important of which, and pretty self-explanatory, are selectAll and selectById.
Our app will only make use of the former. The remaining three are selectEntities, selectTotal, selectIds, which are all pretty self-explanatory.
Updating an entity is very similar to creating one. So similar in fact, that there’s a word for “update or insert if does not exist” — upsert. In theory, you can live through your whole live without ever creating entities, and instead just upserting them.But this is one of the cases where a little less brevity adds a lot of clarity. When you read code that creates an entity, you know that the entity is considered new, which might mean a lot. If there’s upserting all around, it’s harder to tell an entity’s journey in the code, and good code is readable code.
In our app, we’ll just handle the update of a single field on a single user (have a look at it here) via updateOne function, which has been mapped to the userUpdate case reducer:
dispatch(
actions.userUpdate({
id: user.id,
changes: { name: newName },
}),
)
Note the special shape of the action payload: {id, changes}.
Hey, but what if the id of entity A would be part of the changes to entity B? In this odd case, there will still be two entities, but A’s properties will be replaced by B’s. Keep in mind that updateOne performs a shallow update, which means that any nested property of the entity would have to be passed in full.This can be addressed when creating the particular case reducers — remember that you don’t have to use the CRUD functions 1:1.
There’s space for some additional logic, e.g. preventing updates under some conditions:
reducers: {
updateUser(state, action) {
if (!state.isDisabled) {
usersAdapter.updateOne(state, action.payload)
}
}
}
The simplest operation of them all. Just one line:
dispatch(actions.userRemove(user.id))
In this simple app we don’t care about the anything that deleting a user might entail — but in larger applications in which there are relations between entities, there’s more to it. For example, when removing a user in a blogging app, what should happen to their posts? And what about posts co-created with other users?
Obviously, the subject this post started with — communication with a database! All the code shown so far deals with updates to data stored only in the browser memory. And mind you, this can be perfectly all right — be it for reasons of privacy or simplicity.
Most web applications though follow a client-server model, in which the client (a browser in this case) synchronizes the data with a database stored on a server.When a user updates the data, the application sends a request to the server to update the data there.
One implication of such a flow is that there’s usually a lag between the updating action (e.g. clicking a button) and rendering the updated data on the screen.A popular approach is to disable the UI during this lag, but in this day and age Internet users expect instantaneous feedback.
For this reason many applications implement an optimistic update strategy, which is precisely what we’ve done in this example application — assuming that we know how the data will look like after the update.
Let’s render the updated data instantaneously. Then we deal with any errors and discrepancies after the response from the server comes back.
I hope this post explains the concept of entities and their management in web development, and that the CRUD acronym is clear as the water by now.
Thanks!
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

Learn how to build advanced Next.js forms with rule engines, client-side previews, Server Actions, and server-validated form logic.

AI is reshaping engineering teams emotionally as well as technically. A CTO shares insights on fear, trust, burnout, identity, and leading through AI change.

Learn what context rot is, why AI agent sessions degrade over time, and how to fix it with compaction, prompt anchoring, context files, plan files, and RAG.

Learn about TypeScript v6’s breaking changes, new ES2025 features, and deprecated options. A complete migration guide from v5 to prepare for v7.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

