Over the years, there’s been a gradual shift in the way we build and ship web apps. We’ve gone from monolithic apps running on a server to flexible units running on ephemeral instances.

You only need to look at the trends data for the term “aws serverless” to see how popular serverless has gotten over the years. So why the trend? What does the term serverless mean? How can there be no server?
All serverless means is that you can ship code to your users without having to worry about the underlying architecture required to run it. There is still a server running your code somewhere, but you don’t have to worry about setting it up or managing it.
Serverless in a nutshell: “Let someone else be your DevOps team.”
Before we go any further, I’ll come right out and say that I’m an advocate for serverless. If the use case is right, it can carry massive reductions in hosting costs, among a whole host of other benefits.
There’s a caveat, though — notice that I used the phrase “if the use case is right.” That’s because not every app should be built on a serverless architecture. You might end up paying more for hosting and still end up delivering a subpar experience to your users.
This is why you have to weigh the pros and cons of going serverless on a case-by-case basis. In this article, we’ll look at how to determine whether serverless is a good fit for your project.
Firstly, let’s see what servers are before we move on to serverless.
“Learn the rules like a pro, so you can break them like an artist.” – Pablo Picasso
A server, in the context of web apps, is hardware or software dedicated to running and serving your code to your users. You need a server to run your HTML, CSS, and JavaScript as well as your backend environment like Node.js. Even your database runs on a server.
All requests made by your browser are eventually handled by a server somewhere, so you can see how important a server is in software development.
OK, so what’s wrong with the way we use them right now? Well, a traditional server is like a 24/7 restaurant: it’s always open and ready to serve requests. This is how it has always been since Tim Berners Lee invented the web in 1989.
But the problem with being on all the time is that when there’s nothing to do, you’ll start wasting resources. If your restaurant is open for 10 hours but is filled for only three, you’ve wasted time and power for four hours. Do this long enough and the costs begin to accumulate. It eats into your revenue and causes adverse effects on the environment.
Let’s look at a fictional case study to show how inefficient it is to run a traditional web server in a specific case.
Trakkr is a young startup trying to make package tracking and delivery easy and convenient.
They have an API endpoint that enables you to track the location of your package through a unique tracking number. You put in the tracking number and it tells you the location of your package.
Let’s imagine that they host this API on a traditional server, and it takes approximately 200ms to process a single tracking request. We’ll assume that they process an average of 10,000 requests every day.
10,000 requests per day * 200ms per request = 2,000,000ms of work done by the server in a day or 33 minutes of work done by the server in a day
From multiplying the number of requests by the time it takes to process each request, we can see that they need the server to be on for only 33 minutes per day.
The average cost to run a server for a whole day is approximately $3. Running that same server for 33 minutes is approximately $0.07.
Scale that up to a month and Trakkr is shelling out $90 for a server that is idle for 97 percent of the time instead of paying only $2 for the 33 minutes they need.
This brings us to the major selling point of serverless architectures: you only pay for what you use.
Unlike a traditional architecture, where your server is always on regardless of whether it is being utilized, a serverless “server” is only on whenever there’s something to do. This means that you only pay for the time and resources used within a given period. How does this work?
If you decide to build on a serverless architecture, you’ll have to make some major changes to the way you structure your code. Instead of a single server that handles all requests, your app will be composed of smaller functions that are spun up each time when called.
Let’s look at our previous example with the Trakkr API. In a traditional approach, the API would be hosted on a single, always-on server (this is simplified, as you could implement load balancing), and the server would stay on, waiting for tracking requests to process.
In a serverless architecture, the API would be modularized. All the endpoints would be split up into smaller functions that live on the cloud. These functions can access a file system, a database, talk to each other, or use third-party services.
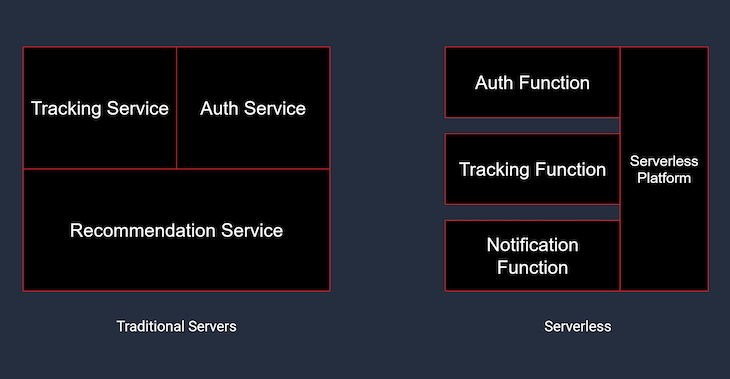
So the Trakkr API, in this case, would consist of these functions hosted on a service like AWS Lambda or Google Cloud Functions. Each request can then be routed to the corresponding function through an API gateway. So what happens when a user makes a request to track a package?
When a tracking request is made, an API gateway intercepts the request and calls the appropriate function to handle the request. An ephemeral instance of the function is then spun up in an isolated container. The function does its job, passes the response back to the user like a normal REST endpoint would, and then the instance is destroyed.
So, to recap:
* In some cases, instances are reused for faster load-up times.
** Up to 15 minutes for AWS Lambda, and 9 minutes for Google Cloud Functions.
The major strength of a serverless architecture is that you’re only charged for the resources you use in a period. If the function runs for 10 minutes in one day and uses 128MB of memory, you will be charged for only those 10 minutes and 128MB of memory.
What if Trakkr switched to a serverless platform like AWS?
Well, we already know that their tracking service handles approximately 10,000 requests per day and that each request takes 200ms to be processed.
We also know that Trakkr is paying $90 to host the server that powers the service. How much would they pay if they switched to AWS?
AWS charges by the number of requests and the duration of each request, and their free tier offers you 1 million requests and 400,000s of compute time. With these freebies, Trakkr’s monthly hosting costs would effectively drop to $0.
What if they decided not to opt for the free tier for some reason? Well, AWS charges $0.20 per 1 million requests, and $0.0000002083 per 100ms of compute time. Let’s revisit the calculations we made before.
Since Trakkr requires just 2,000,000ms of compute time in a day, they’d be spending:
2,000,000ms x $0.0000002083 / 100ms = $0.004166 per day, or $0.125 per month
That’s a reduction of more than 860 percent in server costs for the same service. You can begin to see how, in some cases, switching to a serverless architecture can help you cut down on infrastructure costs massively. This is just one example with one serverless provider, but most offer similar savings.
Apart from the financial benefits that could be gained from switching to a serverless architecture, there are other advantages of building your app this way:
You may have noticed some issues with the way serverless functions are run. Most times, they have to be spun up from scratch when called — a cold start. This includes some overhead like setting up a file system, allocating memory, pulling in dependencies, etc.
This extra work that has to be done before a function is ready can lead to slow startup times, which, in turn, can lead to a bad user experience. This is why providers like AWS and Google Cloud Platform will sometimes reuse an instance of a function to reduce latency (warm starts).
Apart from slow startup times, a serverless function is also constrained in other ways.
Because each function is ephemeral (i.e., short-lived), a new function can’t depend on the data from a previous function — that is, unless the data is stored in a separate, persistent layer, like a Postgres database somewhere. But this isn’t ideal, as you’ll incur more latency in communicating with a separate server to retrieve this data.
There are many other drawbacks to using a serverless architecture. Martin Fowler has gone much more in-depth about these drawbacks in his blog.
If you’re interested in seeing whether serverless would be the right option for you, read along.
The decision to adopt an architecture should not be based on a single article. However, the aim of this section is to provide you some of the questions you should be asking if you’re considering adopting a serverless architecture.
These questions can guide your research to enable you to make informed decisions that will lead to the best outcome for your particular use case.
Maybe have a chat with your CTO or your team lead to answer the questions above (this is by no means an exhaustive list). You should have a much better idea if serverless would be right for a project at the other end of the conversation.
I’ll leave you with a quote from Martin Fowler that bests summarizes the decision to switch to a serverless architecture:
“While there are riches — of scaling and saved deployment effort — to be plundered, there also be dragons — of debugging and monitoring — lurking right around the next corner.”
The webinar features the CTO of Branch insurance and explores how Branch innovates to drive a more efficient frontend and better user experience. Find out how Branch uses serverless to focus more time on iterating and enhancing the Branch platform, and how they get the user insights to do this better than ever.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now
Get to know RxJS features, benefits, and more to help you understand what it is, how it works, and why you should use it.

Explore how to effectively break down a monolithic application into microservices using feature flags and Flagsmith.

Native dialog and popover elements have their own well-defined roles in modern-day frontend web development. Dialog elements are known to […]

LlamaIndex provides tools for ingesting, processing, and implementing complex query workflows that combine data access with LLM prompting.


