It’s safe to assume that the average human understands how infrastructure like a traffic light works. However, we mostly underestimate infrastrcuture’s importance. Roads without traffic systems would be in complete chaos as the average driver lacks lane discipline, and in many cities, the road network can’t even keep up with population growth.

This analogy extends to API design. Just as undisciplined drivers can cause havoc on the roads, malicious users can threaten your application. Plus, as your user base grows, managing traffic surges becomes essential. One effective method to handle this, like traffic lights for roads, is rate limiting.
In this tutorial, we’ll explore rate limiting vs. throttling and other API traffic management techniques. We’ll cover how they work, how to implement them, when to use each strategy, and provide a comparison table to help you decide which approach suits your needs best.
Rate limiting is a technique for controlling the amount of incoming and outgoing traffic on an API by setting a predefined limit on how many requests an API user can make within a given timeframe. This way, you can prevent a single user from monopolizing your API infrastructure resources and simultaneously prevent malicious attacks such as denial-of-service (DoS) and brute-force attacks.
Behind the scenes, rate limiting is implemented with a rate limiter that constantly checks each user’s request to see if it is within their request limit or in excess:
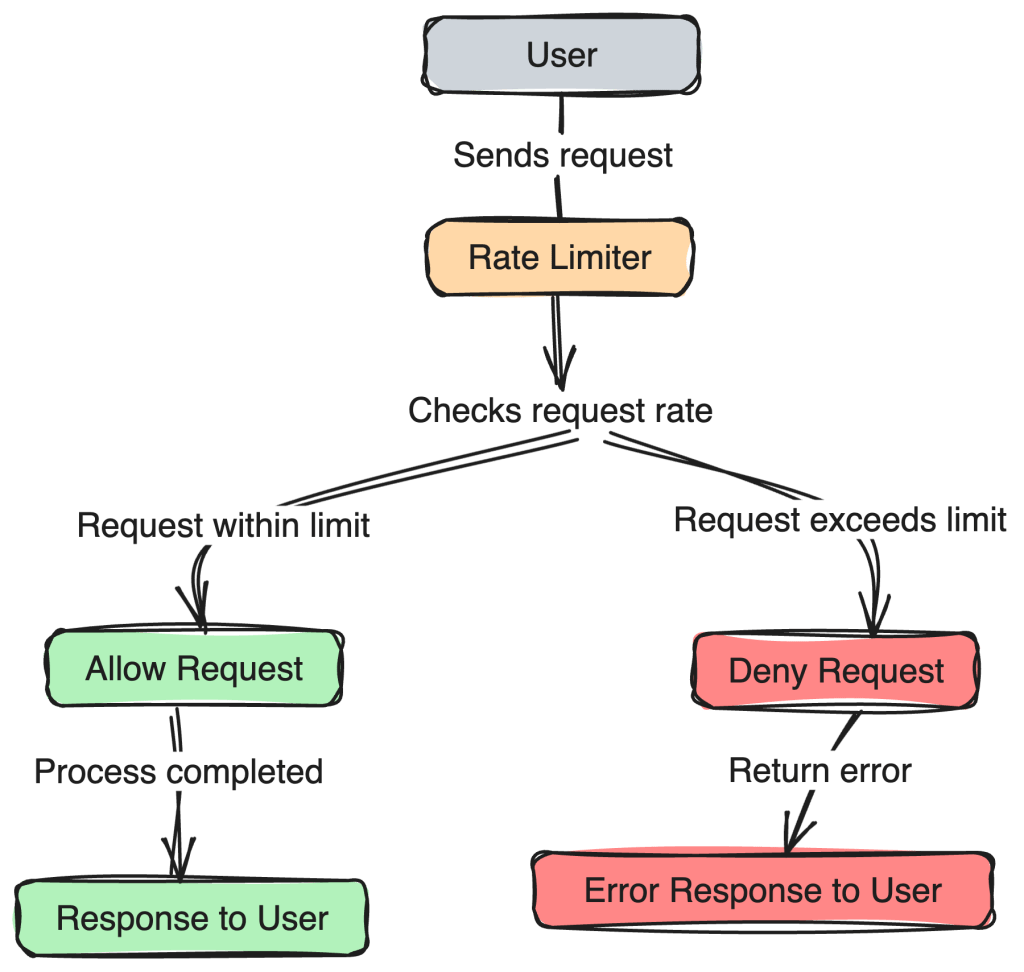
Like in the image above, the request is processed if the user is within their limit, and their new limit is updated. However, the request is denied if they have already exceeded their limit. Furthermore, how these limits are capped and how often they are replenished depend on your organization’s preferences, which are, in turn, influenced by your system capacity and business requirements.
In practice, rate limiting can be implemented using various algorithms, each with its own method for managing request rates. Some popular ones include the following:
For example, we can utilize the pattern shown in the code below to implement rate limiting using the token bucket algorithm:
class TokenBucket {
constructor(rate, capacity) {
this.rate = rate;
this.capacity = capacity;
this.tokens = capacity;
this.lastRequestTime = Date.now();
}
addTokens() {
const now = Date.now();
const elapsed = (now - this.lastRequestTime) / 1000; // Convert to seconds
const addedTokens = elapsed * this.rate;
this.tokens = Math.min(this.capacity, this.tokens + addedTokens);
this.lastRequestTime = now;
}
allowRequest(tokensNeeded = 1) {
this.addTokens();
if (this.tokens >= tokensNeeded) {
this.tokens -= tokensNeeded;
return true;
} else {
return false;
}
}
}
In this code sample, we define a TokenBucket class that sets the token generation rate and capacity and records the last request time; we then create an addTokens() method that calculates the number of tokens to add based on the time since the last request and additionally updates the user’s current token count. Finally, we define an allowRequest() method that checks whether there are enough tokens for a request, deducts any necessary tokens, and returns whether the request is allowed.
Applying this implementation in our application would be something like below:
const bucket = new TokenBucket(1, 10); // 1 token per second, max 10 tokens
function handleRequest(userRequest) {
if (bucket.allowRequest()) {
// Request allowed
userRequest();
} else {
console.log("Too many requests, please try again later");
}
}
function getPosts() {
fetch('/path/to/api')
}
handleRequest(getPosts);
In this usage example, we initialize a new TokenBucket instance with a rate of one token per second and a capacity of 10 tokens. We then create a handleRequest() function that checks if a request is allowed and prints the appropriate message. We also test our request handler with a hypothetical getPosts() function.
This example, while written in JavaScript, should be able to help you get started with implementing rate limiting, or using the token bucket algorithm, in any language. For another practical implementation with Node.js, you can check out this article.
Almost all languages and frameworks also have libraries with which you can easily implement rate limiting without reinventing the wheel; some popular ones in the JavaScript ecosystem include the express-rate-limit package for Express.js and @nestjs/throttler for NestJS applications.
API traffic management is not limited to rate limiting; there are other alternatives to controlling your application’s usage and managing traffic surges. Let’s quickly explore them below.
Throttling is another technique for controlling the rate at which users can make requests to an API. Unlike rate limiting, which blocks requests once a limit is exceeded, throttling slows down the request rate by introducing delays:
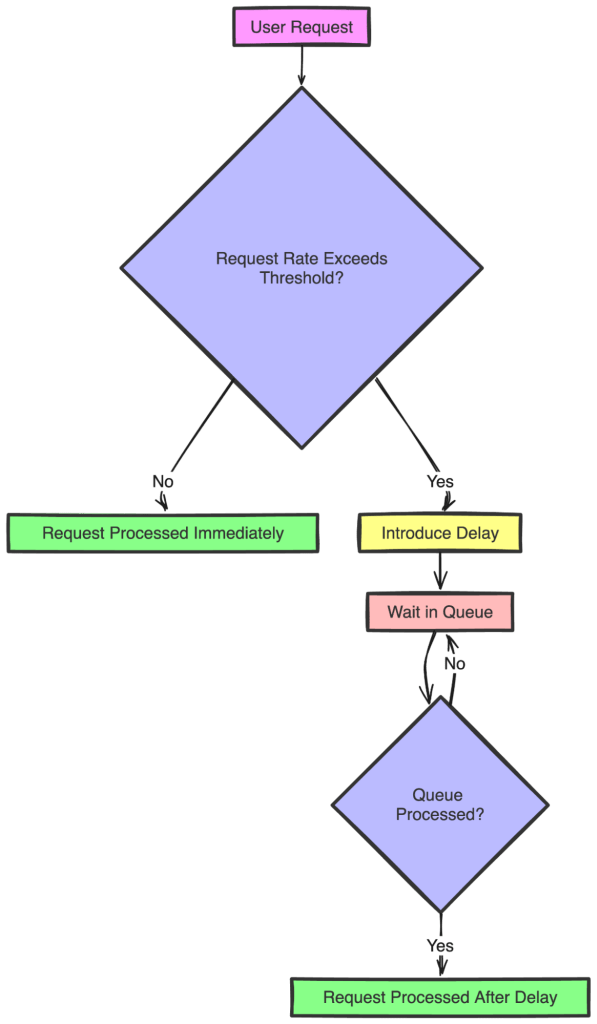
With this design nature, throttling can smooth out traffic spikes while users only experience fewer denials and delayed requests. However, one downside is that these deliberate delays can also increase latency and make the system slower, as each request waits in a queue for processing. Additionally, implementing throttling logic can be more complex compared to simple rate limiting, and in extreme cases, throttling alone may not protect the system from overload.
Throttling can be implemented by keeping a queue of request timestamps, counting the number of requests during a given time period, and introducing delays if the request rate exceeds the permitted limit. An example is shown below:
class Throttler {
constructor(maxRequests, period) {
this.maxRequests = maxRequests;
this.period = period;
this.requestTimes = [];
}
addTokens() {
// Filter out old request timestamps
}
allowRequest() {
// Check if current requests are below maxRequests
// If yes, log the current timestamp and allow the request
// If no, deny the request
}
delayRequest() {
// Calculate delay needed until the next request can be allowed
}
}
In this pseudo-code example, the Throttler class manages the request rate by keeping a queue of request timestamps. Then, an addTokens() method removes request timestamps that are older than the set period. Furthermore, an allowRequest() method determines whether the amount of requests within the period is less than the maximum allowed; if so, it logs the current timestamp and permits the request. Otherwise, it denies the request. Finally, a delayRequest method estimates the time until the next request can be allowed. You can also see the complete JavaScript implementation for this example here.
Spike control is another popular technique for managing sudden surges in traffic that can overwhelm an API or service. It works by monitoring the request rate over short intervals and implementing measures such as temporarily blocking requests, redirecting traffic, or scaling resources to accommodate the increased load.
For example, imagine a scenario where your API can normally handle 100 requests per minute. With spike control, you set a threshold to detect if the number of requests suddenly jumps to 150 per minute:
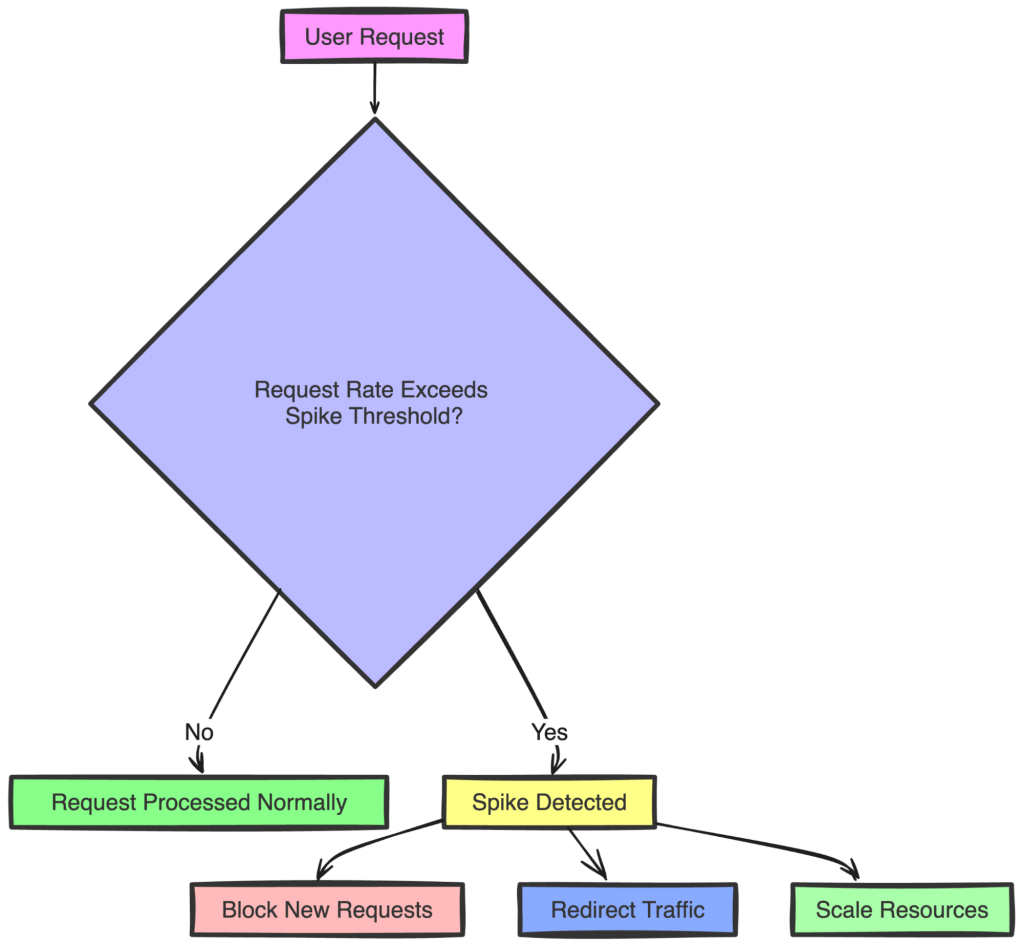
As demonstrated above, when such a spike is detected, you can configure your system to respond by temporarily blocking new requests to prevent overload, redirect traffic to additional servers to balance the load, or quickly scale up resources to manage the increased demand.
Circuit breaking is also an effective technique for managing the resilience of an API or service, especially in the face of failures or performance degradation. It works by monitoring the health of service interactions and temporarily halting requests to a failing service to prevent cascading failures. The usage of the word “service” here should have also hinted that circuit breaking is more popular and useful in microservices architecture than in monolithic or simple API systems, unlike the previous techniques we’ve covered.
Imagine a scenario where your service interacts with a third-party API. If the third-party API starts failing or responding slowly, your system can use a circuit breaker to detect this issue and stop making further requests to the failing service for a set period.
When the circuit breaker detects multiple consecutive failures or timeouts, it “trips” the circuit, temporarily blocking new requests to the problematic service. During this time, the system can return a fallback response or an error message to the user. Then, after a specified timeout period, the circuit breaker allows limited test requests to check if the service has recovered. If the service responds successfully, the circuit is closed, and normal operations resume. If failures continue, the circuit remains open, and requests are blocked again.
Deciding which technique to use mostly depends on your application niche and requirements. However, considering all we’ve covered so far, rate limiting is more ideal for applications that need to enforce strict request quotas, such as public APIs or APIs with tiered access levels. Throttling is more suited for applications where maintaining performance and user experience is critical, such as e-commerce sites or social media platforms, as it introduces delays rather than outright blocking requests, thereby smoothing out traffic spikes:
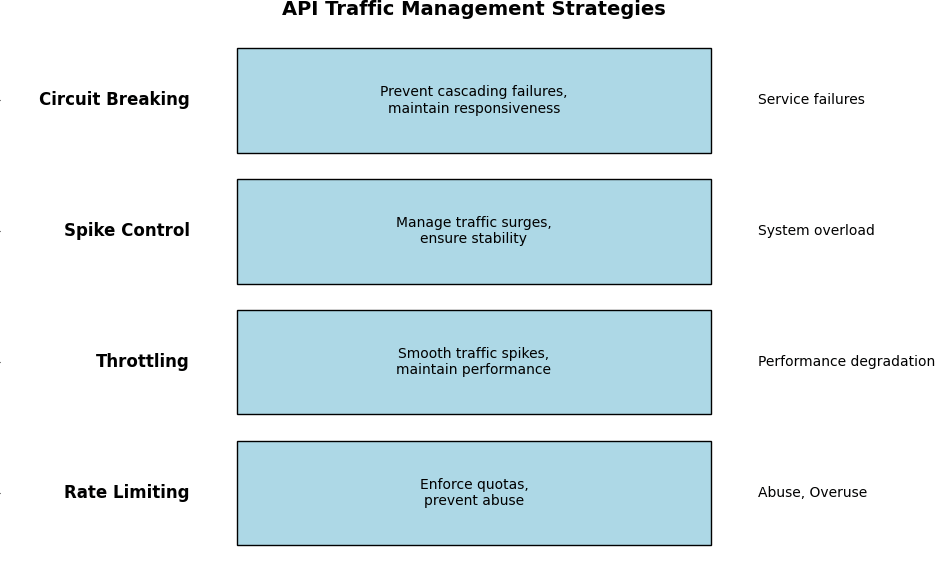
Spike control would be key for applications that experience unpredictable surges in traffic, for example, ticketing websites during high-demand events or news sites during breaking news. Circuit breaking is particularly useful for applications that depend on multiple external services, like microservices architectures or SaaS platforms, as it prevents cascading failures by stopping requests to a failing service while simultaneously allowing the system to remain responsive.
It’s also possible to combine multiple strategies for even more effective traffic management. In some cases, you can further apply load balancing to distribute traffic across servers.
The table below highlights the major differences between the different API traffic management techniques we covered to help you quickly decide which might be best for you.
| Strategy | Description | Best for | Protection against | Example application | Suitable architecture |
|---|---|---|---|---|---|
| Rate limiting | Limits the number of requests a user can make in a given time period. | Enforcing quotas, preventing abuse | Abuse, overuse | Public APIs, SaaS applications | Monolithic, microservices |
| Throttling | Slows down the request rate by introducing delays. | Smoothing traffic spikes, maintaining performance | Performance degradation | Ecommerce, social Media | Monolithic, microservices |
| Spike control | Manages sudden traffic surges by temporarily blocking or redirecting requests. | Managing traffic surges, ensuring stability | System overload | Ticketing systems, news websites | Microservices, serverless |
| Circuit breaking | Temporarily halts requests to a failing service to prevent cascading failures. | Preventing cascading failures, maintaining responsiveness | Service failures | Payment gateways, SaaS platforms | Microservices, distributed |
In this tutorial, we’ve explored rate limiting and other API traffic management techniques such as throttling, spike control, and circuit breaking. We covered how they work, their basic implementation, as well as their ideal application areas. It’s important to take certain traffic management measures to ensure your API can serve its users as intended, and this article provides a quick guide to quickly help you decide how and when to use which technique.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now
Not sure if low-code is right for your next project? This guide breaks down when to use it, when to avoid it, and how to make the right call.

Compare Firebase Studio, Lovable, and Replit for AI-powered app building. Find the best tool for your project needs.

Discover how to use Gemini CLI, Google’s new open-source AI agent that brings Gemini directly to your terminal.

This article explores several proven patterns for writing safer, cleaner, and more readable code in React and TypeScript.


