Many people tend to add a lot of mysticism around Google’s search algorithm (also known as Page Rank) because it somehow always manages to show us the result we’re looking for in the first few pages (even in those cases where there are hundreds of result pages).

How does it work? Why is it so accurate? There is no real answer to those questions unless of course, you’re part of the team inside Google working on maintaining it.
Without having to break into Google’s servers and steal their algorithm, we can work something out that’ll give us a very powerful search feature which you can easily integrate into your site/web app with very little effort and achieve a great user experience at the same time.
I’m essentially referring to what is normally known as a “full text search”. If you come from the traditional web development world, you’re probably used to having a SQL database, such as MySQL or PostgreSQL, which by default allow you to perform wildcard-based searches in your string fields, such as:
SELECT * FROM Cities WHERE name like 'new%';
Using the above query you would usually get matching results such as:
You get the pattern, and if you had more complex objects inside your database, such as blog posts with a title and a body, you might also want to do a more “interesting” search on them, such as:
SELECT * FROM BLOG_POSTS WHERE title like '%2019%' OR body like '%2019%';
Now the above query would also yield some results, but what is the best order for these results? Does it make sense that a blog post that matched because the phone number 444220192 was inside its body, would be returned before one that has the title “The best soccer team of 2019”? The latter match is definitely more relevant, but a simple wildcard match would not be capable of doing that.
And because of that, adding a full-text search on your site might be a great match (especially if you want your users to search through unstructured content, such as FAQs, or downloadable documents to name a few examples).
These are the use cases that leave basic wildcard searches behind. Granted, the most common SQL databases such as MySQL and PostgreSQL have included some form of basic full text capabilities, but if you want to take full advantage of this technique, you need a dedicated search engine, such as Elastic.
The way these engines work is by creating what is known as an “Inverted Index”. In the context of our example, where we’re trying to index text documents, they take each word from every document and record both the reference to the document they appear on and the position inside it. So instead of having to search for your substring inside each document (like you would with the above SQL examples), you only need to search for the substring inside the list of words, and those matching words will already know where they appear using the index.
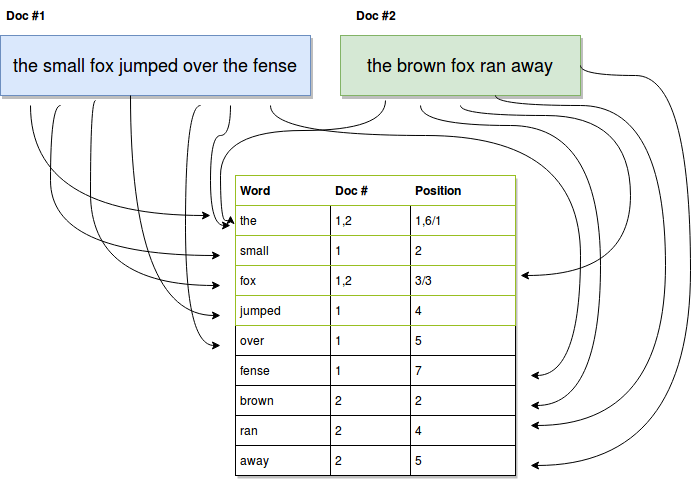
The above diagram shows in a very simplified way, how an inverted index is built:
With this information, we can simply search the index and match any coincidences between your query and the words in the index (we can even search using substrings and still return valid results).
This is still not getting us what we need since we don’t have any information about relevance. What’s more important a match on the title or the body? A full match or a partial match? These are rules our engine would need to know when searching and thankfully, the engine we’re going with today (Elastic) takes care of that and more.
So let’s take this basic inverted index and see how we can use Elastic to leverage this technique, shall we?
Installing and running a local version of Elastic is really very straightforward, especially if you follow the official instructions.
Once you have it up and running, you’ll be able to interact with it using its RESTful API and any HTTP client you have on hand (I’ll be using curl, which should be installed in most common OS by default).
Once this is set, the real work can begin and don’t worry, I’ll walk you through all the following steps down the article:
And to make things easier to understand, let’s assume we’re building a library’s API, one that’ll let you search through the content of different digital books.
For the purposes of this article, we’ll keep the metadata at a minimum, but you can add as much as you need for your particular use case. The books will be downloaded from the Gutenberg Project and will be manually indexed at first.
Every indexed document in Elastic needs to be inserted, by definition, inside an index, that way you can easily search inside the scope you need if you start indexing different and unrelated objects.
If it makes it easier, you can think of an index as a container, and once you decide to search for something, you need to pick one container.
In order to create a new index, you can simply run this:
$ curl -X PUT localhost:9200/books
With that line, you’re sending your request to your localhost (assuming, of course, you’re doing a local test) and using port 9200 which is the default port for Elastic.
The path “books” is the actual index being created. A successful execution of the command would return something like:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "books"
}
For the time being, keep that path in mind, and let’s move on to the next step, creating a map.
This step is actually optional, you can define these parameters during execution of the query, but I’ve always found it easier to maintain an external mapping rather than one that is tied to your code’s business logic.
Here is where you can set up things such as:
In order to create a mapping for a particular index, you’ll have to use the mappings endpoint and send the JSON describing the new mapping. Here is an example following the idea from above of indexing digital books:
{
"properties": {
"title": {
"type": "text",
"analyzer": "standard",
"boost": 2
},
"body": {
"type": "text",
"analyzer": "english"
}
}
}
This mapping defines two fields, the title, which needs to be analyzed with the standard analyzer and the body, which, considering these will all be English books, will use the language analyzer for English. I’m also adding a boost for matches on the title, which makes any of them twice as relevant as matches on the body of the book.
And in order to set this up on our index, all we need to do is use the following request:
$ curl -X PUT "localhost:9200/books?pretty" -H 'Content-Type: application/json' -d'
{
"properties": {
"title": {
"type": "text",
"analyzer": "standard",
"boost": 2
},
"body": {
"type": "text",
"analyzer": "english"
}
}
}
'
A successful execution would yield a result like this:
{
"acknowledged" : true
}
Now with our index and mappings ready, all we have to do is start indexing and then perform a search.
Even though technically, we can do this without coding, I’m going to create a quick script in Node.js to accelerate the process of sending the books into Elastic.
The script will be simple, it’ll read the content of the files from a particular directory, grab the first line and take it as the title, and then everything else will be indexed as part of the body.
Here’s that simple code:
const fs = require("fs")
const request = require("request-promise-native")
const util = require("util")
let files = ["60052-0.txt", "60062-0.txt", "60063-0.txt", "pg60060.txt"]
const readFile = util.promisify(fs.readFile)
async function indexBook(fid, title, body) {
let url = "http://localhost:9200/books/_doc/" + fid
let payload = {
url: url,
body: {
title: title,
body: body.join("\n")
},
json: true
}
return request.put(payload)
}
( _ => {
files.forEach( async f => {
let book = await readFile("./books/" + f);
[title, ...body] = book.toString().split("\n");
try {
let result = await indexBook(f, title, body);
console.log("Indexing result: ", result);
} catch (err) {
console.log("ERROR: ", err)
}
})
})();
All I’m doing is going through the list of books I have on my array, and sending their content to Elastic. The method used to index is PUT, and the path is your-host:your-port/index-name/_doc/a-doc-ID.
This essentially leaves us with a single thing to do, query our data.
In order to query the index, we can use Elastic’s REST API the same way we’ve been using it so far, or we can move on to using Elastic’s official Node.js library.
In order to show something different, I’ll show you how to perform a search query using Elastic’s NPM module, feel free to check out their documentation if you want to start using it.
A quick example that should be enough to put into practice everything I’ve been discussing so far, would perform a full text search on the indexed documents and return a sorted list of results, based on relevancy (which is the default criteria Elastic uses).
The following code does exactly that, let me show you:
var elasticsearch = require('elasticsearch');
var client = new elasticsearch.Client({
host: 'localhost:9200/books'
});
let q = process.argv[2];
( async query => {
try {
const response = await client.search({
q: query
});
console.log("Results found:", response.hits.hits.length)
response.hits.hits.forEach( h => {
let {_source, ...params } = h;
console.log("Result found in file: ", params._id, " with score: ", params._score)
})
} catch (error) {
console.trace(error.message)
}
})(q)
The above code takes the first word you use as a CLI argument when executing the script and uses it as part of the query.
If you’re following along, you should be able to download and index some of the books from the Guterberng project and edit two of them. In one of them add the word “testing” as part of the first line, and in another one, add the same word, but in the middle of the text. That way you can see how relevancy works based on the mapping we setup.
In my case, these are the results I get:
Results found: 2
Result found in file: 60052-0.txt with score: 2.365865
Result found in file: pg60060.txt with score: 1.7539438
Thanks to the fact I used the filename as the document index, I can re-use that piece of information to show relevant results.
Essentially you can now download as many books as you like, and index them using the code from before. You have yourself a search engine, capable of quickly doing a search and returning the relevant filenames for you to open. The speed here is one of the benefits of using the inverted indexed I mentioned before since instead of having to comb through the entire body of each document every time, it’ll just search for the word you enter inside its internal index and return the list of references it made during indexing.
As a direct conclusion of this, you could safely say that indexing a document is far more expensive (computationally speaking) than searching. And since normally, most search engines spend most of their time searching instead of indexing, that is a completely fine trade-off.
That is it for my introduction to Elastic, I hope you found it as interesting as I do. Personally, this NoSQL database (as it is also known) is one of my favorites, thanks to the power you gain with very little code.
You can expand the above code with very little effort by categorizing the books and saving that information as part of the indexed metadata. After that, you can keep records of the types of books your users search for, and then adapt individual mappings with different boost values based on their preferences (i.e favoring sci-fi books for some users, while boosting history-based books for others). That would give you an even closer behavior to that of Google’s. Imagination is the limit!
Let me know down in the comments if you’ve used Elastic in the past and what kind of crazy search engine you have implemented!
Otherwise, see you on the next one!
 Monitor failed and slow network requests in production
Monitor failed and slow network requests in productionDeploying a Node-based web app or website is the easy part. Making sure your Node instance continues to serve resources to your app is where things get tougher. If you’re interested in ensuring requests to the backend or third-party services are successful, try LogRocket.

LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now
Not sure if low-code is right for your next project? This guide breaks down when to use it, when to avoid it, and how to make the right call.

Compare Firebase Studio, Lovable, and Replit for AI-powered app building. Find the best tool for your project needs.

Discover how to use Gemini CLI, Google’s new open-source AI agent that brings Gemini directly to your terminal.

This article explores several proven patterns for writing safer, cleaner, and more readable code in React and TypeScript.



3 Replies to "How to write your own search engine using Node.js and Elastic"
Hello,
I am desperately wanting to develop my own search engine (for personal and private reasons….mostly because my site is so censored due to the bulk of it speaking out against monopoly control and capitalism and polity becoming one-and-the-same).
So I came across your post here: https://blog.logrocket.com/write-your-own-search-engine-using-node-js-and-elastic/
I see that this was recently written which makes it more appealing to me.
Thanks for the time you took to write this.
I’m glad you found it then! Good luck with your custom search engine and do let me know if you run into any issues! I’ll be happy to help as much as I can. Cheers!
This blog has the information that enterprise search tool enthusiasts need to get started with building their own search engine like the ones available today, like 3RDi Search, Algolia, Commvault, etc.