Modern technology increasingly integrates artificial intelligence and machine learning, enhancing application contextual awareness for users. AI and ML are at the core of this innovation, from recommending a movie you might enjoy on a streaming platform to enabling voice-assistant devices to understand and respond to your commands.

A fundamental element of many AI and ML systems is handling and manipulating vectors and embeddings, which represent complex, high-dimensional data in a format that machines can understand and process efficiently.
In this article, we investigate how to work with vectors and embeddings in the context of databases, focusing on Supabase, an open source alternative to Firebase. Supabase, with its sleek design and comprehensive suite of features, has been winning hearts among developers who are looking for easy-to-use, scalable backend solutions.
We explore how to manage vector data in a PostgreSQL database using Supabase, taking advantage of its robust data handling capabilities. We also dive deeper into the creation of embeddings using OpenAI, which offers an efficient way to transform complex data into meaningful numerical representations, enabling us to leverage the power of AI in our applications.
Jump ahead:
At a high level, a vector can be considered a container holding an ordered set of numbers. In mathematics, vectors often represent a point in space, where each number corresponds to the position along a different dimension. In computer science and, more specifically, in machine learning, vectors play an even more pivotal role: they act as a mathematical representation of data.
Consider a simple example where we want to represent different types of fruits in a machine learning model. We can create a vector that describes each fruit, with each element or number in the vector representing a distinct attribute or feature of the fruit.
Let’s take an apple as an example. A vector for an apple might look like this: [1, 150, 8.5, 10]. In this vector the four numbers could represent the following:
1, could represent the type of fruit (1 for apple, 2 for banana, etc.)150, might indicate the weight of the fruit in grams8.5, could represent the fruit’s sweetness on a scale of 1 to 1010, might indicate the fruit’s redness on a scale of 1 to 10This way, the vector [1, 150, 8.5, 10] in our model uniquely represents an apple with specific attributes.
Vectors are a straightforward method of representing numeric data, but many data types, like text or images, need help translating into numbers. This is where embeddings come in. An embedding is a type of vector that is designed to represent more complex, high-dimensional data in a lower-dimensional, dense vector space.
For instance, imagine we want to represent the word “apple” so that a computer can understand and relate it to similar words. We could use an algorithm to translate the word “apple” into a list of 300 numbers that form an embedding vector.
This embedding vector captures not just the word itself but also its relationship with other words. For example, the embedding for “apple” would be closer in terms of distance to the embedding for “fruit” than it would be to the embedding for “car,” reflecting the closer semantic relationship between “apple” and “fruit”.
Embeddings are potent tools for representing high-dimensional data, especially in text form, in lower-dimensional space. Their ability to capture data semantics makes them valuable in various applications, including search, clustering, recommendations, anomaly detection, diversity measurement, and classification. Let’s take a closer look at these use cases.
When a user types in a query, we want to show results that are most relevant to the query string. With embeddings, each item in the search index and the query string can be converted into vectors. The items most relevant to the query are those whose vectors are closest to the query vector, enabling a more contextually relevant search experience.
Clustering involves grouping text strings based on their similarity. We can calculate the distance between each pair of embeddings by representing each text string as an embedding. Semantically similar text strings will have closer embeddings and can thus be grouped together. This can be particularly useful for tasks like topic modeling or customer segmentation.
In recommendation systems, if items (e.g., books or movies) are represented by embeddings, we can recommend items to a user similar to the ones they’ve interacted with before. This similarity is determined by the distance between the embeddings of different items, providing more personalized recommendations.
Anomalies are data points that are significantly different from the majority. By converting text strings into embeddings, we can spot anomalies as vectors farthest from the rest in the vector space. This can be used in applications like fraud detection or error detection in text data.
Embeddings can help measure the diversity of a set of text strings. By analyzing the distribution of embeddings, we can quantify the diversity of the dataset. For example, a tightly clustered set of vectors indicates low diversity, while a more spread-out set suggests higher diversity. This has several useful applications, like ensuring diversity in content recommendations or understanding the variety of opinions in social media data.
To classify text strings, we can use embeddings to convert the text into vectors and then train a machine learning model on these vectors. We generate an embedding for a new text string, and the model predicts the class based on its proximity to the embeddings of different classes. This can be used for tasks like spam detection, sentiment analysis, and document categorization.
pgvector is a PostgreSQL extension that enables storing and querying vector embeddings directly in our database.
The first step involves activating the Vector extension. We can do this through Supabase’s web interface by going to Database and then selecting Extensions:
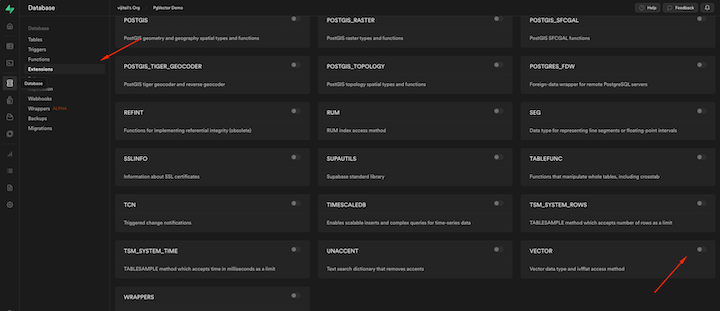
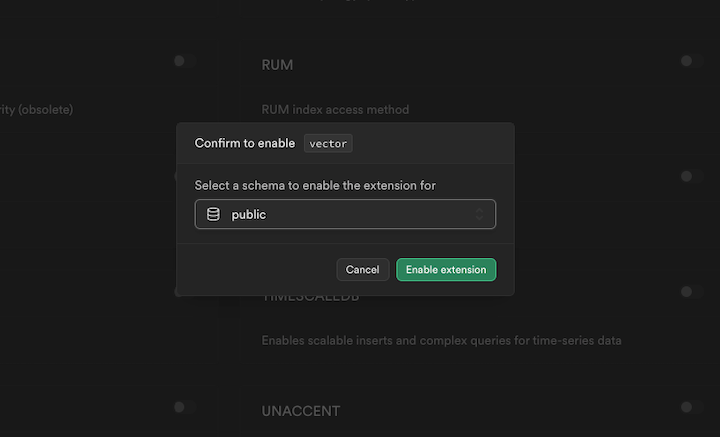
In the modal’s field, we select public schema, toggle the vector button, and the click Enable extension:
Next, we create the posts table to store the posts and their respective embeddings:
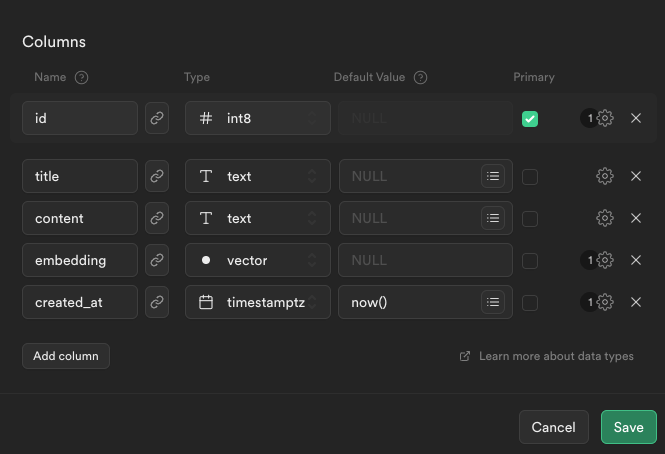
The pgvector extension enables a new data type named vector. In the above table, we create a column named embedding that utilizes this new vector data type. We also add text columns for storing the original title and content, which resulted in the generation of this particular embedding.
OpenAI provides an API that facilitates the creation of embeddings from a given text string using its language model. We can input text data (such as blog posts, documentation, or our organization’s knowledge repository), yielding a vector of floating-point numbers. This vector essentially encapsulates the “context” of the input text.
To generate embeddings using OpenAI, we’ll start by setting up our environment. We install necessary dependencies using the following command:
npm i express @supabase/supabase-js openai dotenv
Dependencies include the Express framework for handling server operations, Supabase client for interacting with our Supabase database, OpenAI package for generating our embeddings, and dotenv package for managing environment variables.
After importing the required modules, we initialize our Express application with the express() method. The Supabase client is created using environment variables for the Supabase URL and key. This client interacts with our Supabase database.
For the OpenAI API, we create an OpenAI configuration object using the OpenAI organization ID and API key from our environment variables. Once the configuration is ready, we instantiate the OpenAI API client with new openai.OpenAIApi() method.
Finally, we start the Express application to listen for requests on port 3001. Our application is now ready to interact with OpenAI and Supabase to generate and store embeddings:
const express = require("express")
require("dotenv").config();
const supabase = require("@supabase/supabase-js");
const openai = require("openai");
const app = express();
const supabaseClient = supabase.createClient(
process.env.SUPABASE_URL,
process.env.SUPABASE_KEY
);
const openAiConfiguration = new openai.Configuration({
organization: process.env.OPENAI_ORG,
apiKey: process.env.OPENAI_API_KEY,
});
const openAi = new openai.OpenAIApi(openAiConfiguration);
...
app.listen(3001, () => console.log("Server started"));
Next, let’s see the implementation of two API endpoints and a helper function to generate embeddings:
const getEmbedding = async (input) => {
try {
const embeddingResponse = await openAi.createEmbedding({
model: "text-embedding-ada-002",
input,
});
const [{ embedding }] = embeddingResponse.data.data;
return embedding;
} catch (err) {
console.log(err);
return null;
}
};
app.post("/api/generate-embeddings", async (_req, res) => {
try {
const posts = await supabaseClient.from("posts").select("*");
for (const post of posts.data) {
const embedding = await getEmbedding(`${post.title} ${post.content}`);
await supabaseClient
.from("posts")
.update({ embedding })
.eq("id", post.id);
}
return res.json({ isSuccess: true });
} catch (err) {
return res.json({ isSuccess: false, message: err?.message });
}
});
app.post("/api/create-post", async (req, res) => {
try {
const { title, content } = req.body;
const embedding = await getEmbedding(`${title} ${content}`);
await supabaseClient.from("posts").insert({ title, content, embedding });
return res.json({ isSuccess: true });
} catch (err) {
return res.json({ isSuccess: false, message: err?.message });
}
});
The getEmbedding() helper function accepts a text input and sends it to the OpenAI API to generate an embedding. It uses the createEmbedding() method, specifying the model as "text-embedding-ada-002". Then it extracts the embedding from the response and returns it. If an error occurs during this process, it is logged, and null is returned.
The /api/generate-embeddings route fetches all posts from the posts table in the Supabase database using the Supabase client. It loops over each post, generates an embedding for the post’s title and content using getEmbedding, and then updates the post in the database with the new embedding.
The /api/create-post route is a POST route that receives a request containing a title and content in the body. It generates an embedding using the title and content, and uses the Supabase client to insert a new post in the posts table, including the title, content, and embedding.
Once we create embeddings for the posts, it becomes fairly straightforward to compute their similarity using vector mathematical operations, such as cosine distance. A prime use case for cosine distance is implementing search functionality in an application.
As of this writing, there isn’t any API support to compare vectors using the Supabase client. So, to facilitate similarity search over the embeddings, we will need to create a function in the database.
The following PostgreSQL function, match_posts, is designed to find similar posts to a given query, based on the cosine distance between the vector embeddings of the posts and the query:
create or replace function match_posts (
query_embedding vector(1536),
match_threshold float,
match_count int
)
returns table (
id bigint,
title text,
content text,
similarity float
)
language sql stable
as $$
select
posts.id,
posts.title,
posts.content,
1 - (posts.embedding <=> query_embedding) as similarity
from posts
where 1 - (posts.embedding <=> query_embedding) > match_threshold
order by similarity desc
limit match_count;
$$;
The function takes three parameters:
query_embedding: a vector of 1536 dimensions, representing the embedding of the input querymatch_threshold: a floating-point number that serves as the minimum similarity score for a post to be considered a matchmatch_count: an integer that sets the maximum number of posts to returnThe cosine distance between the embeddings is computed using the <=> operator, which returns a value between 0 (meaning exactly the same) and 2 (completely dissimilar). We subtract this from 1 to get the cosine similarity, which is a value bound in [-1, 1].
Only posts that have a similarity score higher than the match_threshold are considered. These are ordered in descending order of similarity, and only the top match_count number of posts are returned.
We create a /api/search API endpoint to get the search results for top similar posts. We pass the search query in the query params, and generate a one-time embedding for the search operation. To invoke a database function, we use the rpc() method of the Supabase client:
app.get("/api/search", async (req, res) => {
try {
const { q } = req.query;
const embedding = await getEmbedding(q);
const matchedPosts = await supabaseClient.rpc("match_posts", {
query_embedding: embedding,
match_threshold: 0.8,
match_count: 3,
});
return res.json({ isSuccess: true, posts: matchedPosts.data });
} catch (err) {
return res.json({ isSuccess: false, message: err?.message });
}
});
And there you have it! You can now spin up your local server and put it to the test. Using tools like Postman, you can send HTTP requests to your endpoints and verify the search results. With your new vector search functionality, exploring and interacting with your data should feel more intuitive and responsive.
You can find the complete code from this tutorial on GitHub.
In this guide, we investigated how Supabase’s PostgreSQL extension, pgvector, can be used with OpenAI to manage and process vector embeddings. We touched on the fundamental concepts of vectors and embeddings and how they can power advanced features such as similarity search.
We also dove into the coding aspects, from setting up a basic Express server to handle API requests, to generating embeddings with OpenAI, and using them within our database. By leveraging these tools, we can develop more intelligent and contextually aware applications.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

Discover how React Fiber works under the hood. Learn how React builds the DOM, handles concurrent rendering, and works alongside React 19 features and the new React Compiler.

Learn how to use Skybridge, an open-source React framework, to build and deploy cross-platform AI apps and interactive UI widgets for ChatGPT, Claude, and MCP clients from a single codebase.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

