Maintaining a growing software product can be daunting. You go from a two bedroom apartment to an office full of people and along the way, teams are formed, deployments are slow, and the new data science guy only codes in R.

Everyone is producing code and lots of it, but where do you put it all?
At LogRocket, we have thousands of files that keep our services looking nice and running smoothly. From frontend to backend, every line of code is stored in a single, gloriously fat git repository.
This approach is known as a monorepo.
Surprisingly, it really isn’t. A common alternative approach is to have one repository per service.
This is clearly appealing.
It keeps services focused and avoids coupling of code. Unfortunately it just never stays this contained. If you deploy two microservices in the same language, odds are they’ll share a lot of boilerplate code. And if they also want to communicate, they should probably share an RPC schema.
The end result is a bunch of random shared repositories that only exist to serve as the glue between real services. It may look cleaner, but it really isn’t any less of a mess:
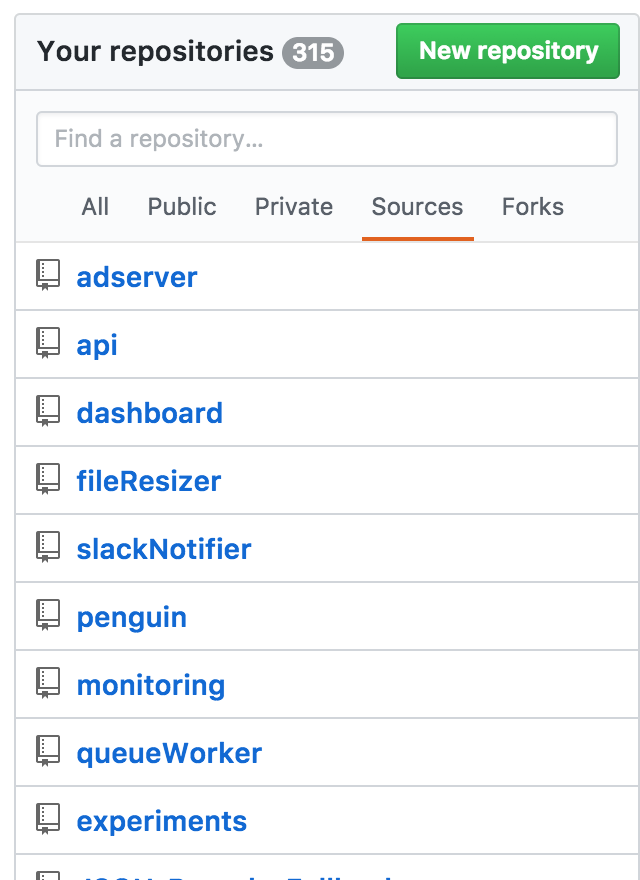
Repositories also add a lot of developer overhead. They need to be created, hooked up to CI, and cloned by everyone.
And that’s just to get started.
Keeping them up-to-date is hard, changes to more than one involve tracking multiple PRs at the same time. And git subrepos are rarely the answer if you want any sort of consistency. If most of your developers have the same set of repositories cloned into the same places, there must be some clear benefit to that separation.
Separation of code, you say. Of course, a monorepo can also backfire in similar ways. Keeping code together is enticing; having it grow into a seamless ball of mud is not. But separation is not the problem, repositories are the problem. Every project should still have a module structure to keep code separated. Luckily, this is easily solved by a bit of tooling.
In JavaScript, local module management is most easily done with one of two tools:
Both of these essentially turn your entire repository into a collection of private npm packages. Set up with yarn workspaces, the multi-repository project becomes:
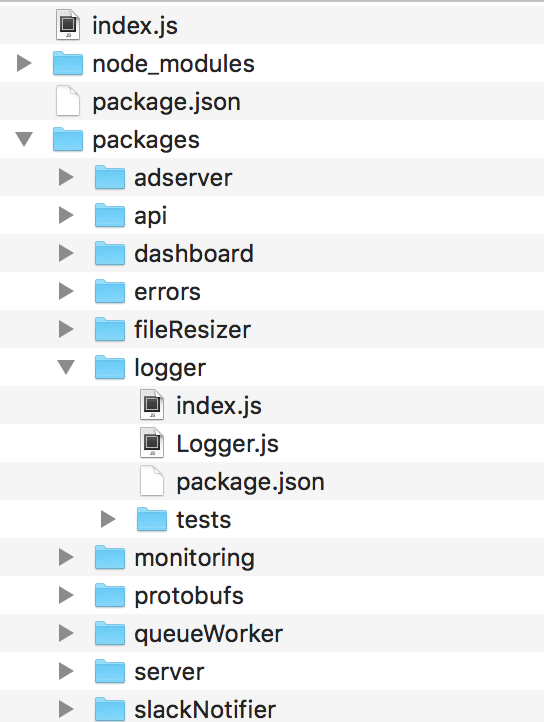
Since it avoids the overhead associated with creating and managing git repositories, a lot of things start to break out more clearly. The penguin base repository here has turned into separate server, logging, and errors packages.
Sharing a single directory tree is surprisingly handy. You can set up a file that imports all the services used by your app, and start them with a single command:
import Server from 'server';
import Queue from 'queueWorker';
import Resizer from 'fileResizer';
Server.create({ port: 5000 });
Queue.create({ port: 5001 });
Resizer.create({ port: 5002 });This is much simpler than having to remember to start everything, or taking the extra steps to recreate your production environment on a local docker installation.
Taking this idea of importing other packages further, end-to-end tests become much more manageable. Imagine for example, that you’re testing the processing pipeline for your instaphoto startup. You can simply mock out the parts you don’t want in any service of the pipeline. This is how you get truly fast end-to-end tests:
import Server from 'server';
import Logger from 'logger';
import Slack from 'slackNotifier';
import sinon from 'sinon';
it('should log startup errors and send them to slack', () => {
sinon.spy(Logger, 'logException');
Slack.notify = sinon.spy(() => {});
Server.create({ port: 5000 });
Server.create({ port: 5000 }); // port already taken
expect(Slack.notify).to.be.called();
expect(Logger.logException).to.be.called();
});This setup allows for much simpler development than having to recreate your production environment on a local docker installation.
In a monorepo, all code changes for an improvement or a new feature can be contained in a single pull request. So you can, at a glance, see the full scope of the change. Code review can also be done in one place and discussions are tied to the feature, not the individual parts of whatever teams are involved. That’s true collaboration.
Merging a pull request like this means deployment to all involved systems can happen at the same time.
There is some work required to build an individual package when using lerna or yarn workspaces. At LogRocket we’ve settled on roughly this:
And since there’s nothing like production traffic to find edge-cases, rolling back buggy code is as easy as reverting a single commit. Something that is easily done, even at 3am on a Sunday.
At LogRocket we share code across our entire stack: backend, frontend, and even with our public SDK. To keep our wire format in sync, the SDK is published with some of the same packages used by the backend services that process data. They’re never out of sync, because they can’t be out of sync.
There are still cases where you will still need separate repositories. If you want to open source some of your code, or if you do client work, you may wish to keep some things separate.
Do you have a better way? Let us know here or on Twitter.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

Learn how to use Fallow to analyze AI-generated code, detect dead code, duplicate logic, and complexity issues, and integrate automated code quality checks into your AI-assisted development workflow.

Learn how to protect full-stack projects from NPM supply chain attacks with a practical security checklist.

Explore 15 essential MCP servers for web developers to enhance AI workflows with tools, data, and automation.

Learn how contrast-color() automatically picks accessible text colors using native CSS, without JavaScript.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

