Let’s say you are trying to implement a large dataset into a table. How large, you ask? Let’s say 100,000 rows need to be viewed in a single tabular format.

If you use the native implementation in Vue.js, it will take forever for the page to render all that data. Just because you are a frontend developer doesn’t mean you get a free pass at having to worry about performance issues!
Even if you are rendering a table with just 1,000 rows, it’s not going to be fun for the user to work through a table of that length. You’ll notice that scrolling isn’t as smooth as it typically is, especially when using the mouse wheel.
In this article we will talk about several ways to reduce rendering time and increase overall performance for large datasets in Vue, as well as a few memory handling tips that will help your data-heavy sites run more smoothly and use less RAM.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
This is one of the most common solutions for rendering large datasets. Pagination means breaking down the table into separate pages, so it will only render a single page at a time.
You can use the items prop, which accepts the item’s provider function to fetch data from a remote database. Then, use pagination and filtering in your API request to fetch only the required data for about 100 items on each request.
That seems simple enough. But what if you need to load the whole table on a single page? Maybe you need an endpoint to pull everything back and run some calculations on the data.
In such a case, there’s another method we can use to load our table.
There are a few ways we can load specific areas of data without pagination: with Clusterize.js and with Vue-virtual-scroller and other related components.
Clusterize.js is a JavaScript library that solves this problem quite easily. It enables us to load and display just a specific area of the table. So how does it work?
The table is put inside a scrollable container that displays a few rows at a time and allows you to move through the entire table. Only the visible part of the table will be created in the DOM structure.
As soon as the user scrolls within the table container, new table data is loaded. So the data loading happens in the background, and the user won’t notice any difference.
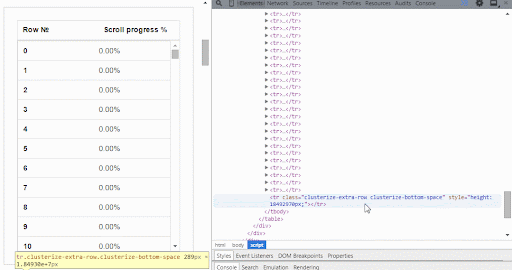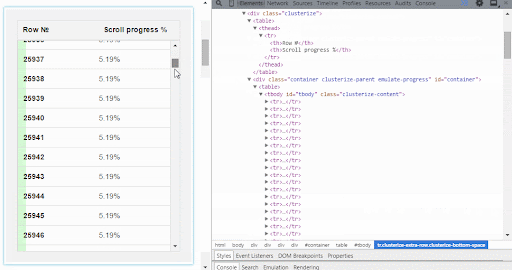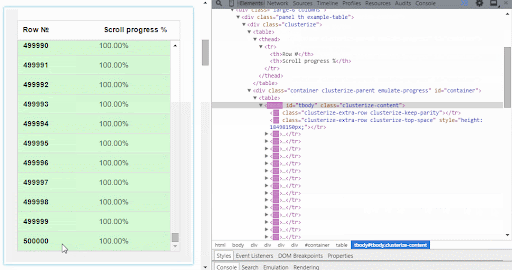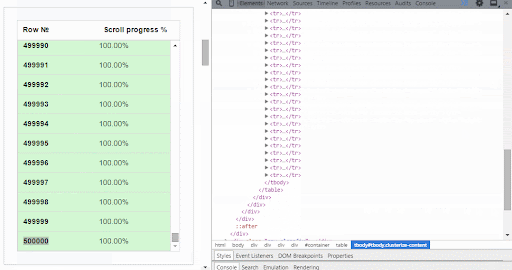
Using Clusterize.js in your code is quite straightforward.
The difference in performance after adding this plugin is remarkable. However, if you need to be sure, there’s a compelling example at the top of their website that allows you to easily compare a regular table to a Clusterize.js-optimized table. Make sure you check out their playground, too, for even more proof.
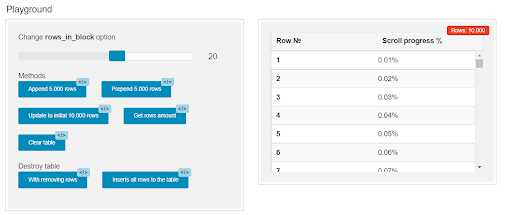
These popular components allow for quick scrolling through large amounts of data in Vue apps, but do come with a caveat; Vue-virtual-scroller and Vue-virtual-scroll-list don’t deal with dynamic heights unless you hardcode them. If you want to test it out, there is a playground available for Vue Virtual Scroller here.
Another option is the Vue-collection-cluster component, which allows you to calculate heights dynamically, but it lags miserably at about 50,000 items.
However, even with these drawbacks, each of these libraries allow you to build an adequate virtual scroll. In the end, if you have a database pushing about 10–100MB of JSON data, you are all set in performance.
If your website is performance-optimized, we can move on to the next section.
When dealing with a large dataset, the biggest thing you need to worry about is handling memory usage. If you allow users to edit a data-heavy table, you are going to be hitting a memory limit, and your web browser will stop running JavaScript altogether.
Loading that much data puts a burden on web browsers (and the number of nodes they can retain in memory) and causes your devices’ RAM use to skyrocket.
The problem will be amplified on devices with less memory, like smartphones and tablets, and could even cripple those devices. It’s biting off more than you can chew.
Now, memory handling can be improved in many ways. I’ll separate it into five steps below.
We can keep things simple and reduce the stress on our back end by fetching plain objects without related models. Then, the main results will only have ID keys to related objects.
Plus, by using Axios (or a similar library) to fetch related data with separate AJAX requests (e.g., “customers”, “projects”, “locations”), we can use VueX to store them in their own list properties. This will avoid fetching full-model trees.
First, create getters for each object so we can use related models for fetching labels (or full objects when required) and our back end doesn’t need to fetch related data more than once:
projectsById: state => {
return _.keyBy(state.projects, "id")
},
Then, we can fetch different lists, each with its own controller endpoint, and cache the results to the VueX store. Keep in mind that you can send multiple requests using Axios.all([...]).
It is necessary to optimize the way we handle our data. You can use the component object as data storage for your custom objects and object lists.
An optimized list component setup looks like this:
module.exports = {
items: [],
mixins: [sharedUtils],
data: function() {
return {
columns: {
all: []
etc...
It’s better to handle an item array as non-reactive, but how can we handle it in a nonreactive manner if we want the table to be reactive with real time filters?
Whenever a user clicks a filter button or inputs a string filter (such as a name), we need to trigger the filtering of the items array. This processFilters method goes through the nonresponsive items array and returns filteredItems, which are stored in DataContext, so it automatically becomes reactive as it is transformed:
<tr v-for="item in filteredItems"
This way, all the items within filteredItems stay reactive, but also lose reactivity when they are filtered out, saving a lot of memory.
However, the issue here is that we can’t just use items in DataContext directly within a template.
So you cannot use this:
<div v-if="items.length > 0 && everythingElseIsReady">
Instead, you have to store the length of the items array to a separate data prop.
With a nonreactive main data array, modifications made directly against items within that main array won’t trigger any changes to the UI or subcomponents.
To solve this issue, we need a separate container that holds all the results from the back end with a smaller (filtered) presentation array of that larger container. In this case, we use good REST architecture to handle nonreactive data storage.
Sometimes when representing the same sub-object multiple times for different master records, without even realizing it, you might be creating objects that do not reference other objects.
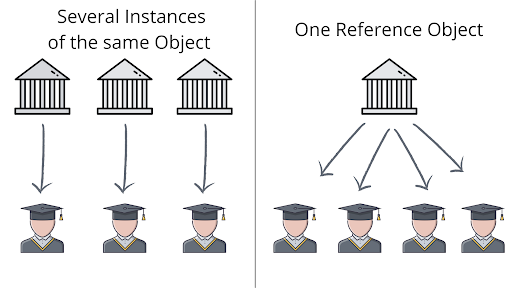
For example, imagine you have a student-object that contains a university-object. Now, multiple students go to the same university. But when you fetch JSON data from the back end, are you sure those duplicated university-objects are the same university? Or are they multiple representations of the same object?
You can, of course, pass university as a property to your student-object. At the same time, if you are unsure whether you are referring to a shared university-object or using dozens of instances of the same sub-objects, you could simply do the referencing inside your student-list component.
A student will contain a university-id, so fetch a list of Universities with a separate REST-method (e.g., getUniversities()), and do the pairing on the UI level. This way, you have only one list of Universities, and you can resolve the University from that list and inject it into a person, thereby making reference to only one.
Basically, you need to manage your master records (e.g., persons or products) vs. related records (sub-objects or relational objects).
Keep in mind that you can’t use this method if the sub-object is reactive. If it needs to be editable, then you need to make sure that you are not using the referred object!
In this article, we briefly discussed Pagination and using Clusterize.js to optimize a website’s performance. Then, we dove into memory handling with five easy steps: limiting unnecessary data passing, optimizing data handling, making it non-reactive, having a hidden container, and differentiating instances of objects from referenced ones.
All things considered, Vue is fairly efficient in handling large datasets. But like everything, the best way to see if it is suitable for your needs would be to create the type of components, filter, and sorts that you need, then load them with large sets of (seed or testing) data to check if they are performant enough for your needs.
Debugging Vue.js applications can be difficult, especially when users experience issues that are difficult to reproduce. If you’re interested in monitoring and tracking Vue mutations and actions for all of your users in production, try LogRocket.
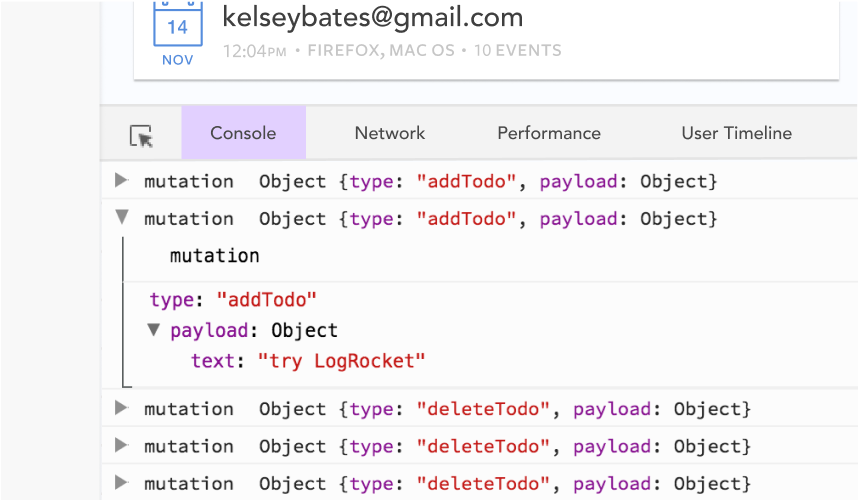
LogRocket lets you replay user sessions, eliminating guesswork by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
With Galileo AI, you can instantly identify and explain user struggles with automated monitoring of your entire product experience.
Modernize how you debug your Vue apps — start monitoring for free.

Learn how to use Gemini CLI subagents to delegate frontend, backend, testing, and docs tasks to specialized agents with guardrails and clear ownership.

Learn how next-browser gives AI agents runtime context for debugging Next.js apps, including React props, hydration, PPR, forms, and performance.

Build dynamic LLM routing in Next.js with OpenRouter, TanStack AI, task classification, model fallbacks, and cost-aware routing.

TSRX adds first-class control flow, conditional hooks, and scoped styles to React via a TypeScript compiler extension — no new framework required.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

