Over the years, Storybook as a tool has become quite a staple in frontend projects. It enables rapid development speed, higher-quality and more maintainable frontend code, and a smooth integration with the design department. For any frontend-related project or library, it’s nowadays more common to see the inclusion or involvement of Storybook than not.

However, one of the major downsides of Storybook is the speed of its internal server. Despite the benefits that Storybook brings, its performance is something that developers oftentimes identify as a key drawback. This becomes even more prominent when adding custom configurations, styling, or plugins on top of the existing server. Several measurements can be found in Storybook’s own benchmark where they compared their webpack server to Vite.
This is where the new kid on the block comes in: Ladle. Created by teams at Uber, Ladle is meant to be (and is advertised as) a drop-in alternative to Storybook. Built on top of Vite, using esbuild, and embracing ES modules, Ladle is clearly positioned as a significantly more performant competitor.
In Ladle’s own benchmarks, the performance improvements are tremendous and extremely promising, ranging from a reducing factor of 4 to 25. However, both this benchmark and Storybook’s were only performed on an extremely large project with over 250 stories.
While this can really highlight the difference in performance in the long run, the scenario isn’t representative of all frontend projects that could benefit from either tool. Most projects aren’t as large, and therefore won’t have as many stories to consider when choosing between Storybook and Ladle. Some projects will be extremely small, such as when teams consider either tool to be the starting point; others will make the decision when they’re medium-sized and still growing.
This article will extend upon the existing benchmarks to identify potential performance improvements and use cases for adopting Ladle over Storybook. We’ll conduct an experiment that will cover different project sizes that represent the different scenarios described above, measure the metrics based on the existing benchmarks, and compare the performance of Ladle and Storybook in the different environments.
Here’s what we’ll cover:
To compare the performance of both tools, we’ll be looking at several metrics. Instead of reinventing the wheel, we’ll combine metrics used in previous benchmarks from both Storybook and Ladle:
Unfortunately, I wasn’t able to get the auditing tool @storybook/bench working on most Storybook projects. So, instead, the startup time metrics for Storybook projects will be measured by the numbers logged by Storybook itself. To measure the hot reload time, we’ll use the time as logged by the webpack server behind Storybook. Lastly, we’ll measure the build size of the project by the disk size of the resulting artifacts.
For Ladle projects, I had to make some manual measurements because the Ladle server doesn’t log any performance numbers itself. For the startup time, we’ll start the timer when Ladle’s CLI starts building the server and stop it when the server indicates it is connected.
For the hot reload time, the underlying server keeps track of when the change was triggered. We’ll use this and log the duration when the server indicates that it’s done with the HMR. Lastly, the build size is measured the same way as Storybook projects.
On top of that, we’ll benchmark three projects of different sizes representing different categories of projects:
For the results, we’ll look into all of the metrics individually. For every one of them, we’ll compare the results between Storybook and Ladle, but also pit the three different project sizes against each other so that we can:
All of the measurements are performed on my personal machine, a 2016 Intel Macbook Pro on macOS 10.15.3 with 8GB of memory. For every metric, I’ll make five measurements and take the average of those runs as the final value.
The first metric we’ll look into is the cold startup time. This is the time it takes for either tool to get their server running for developers without an existing cache.
This metric is not only relevant for the first time the server is spun up, but also when the cache is invalidated. Think of when the configuration changes for the development environment: this invalidates the cache and causes the server to perform another cold startup. A lower startup time means less waiting and thus a better experience and performance.
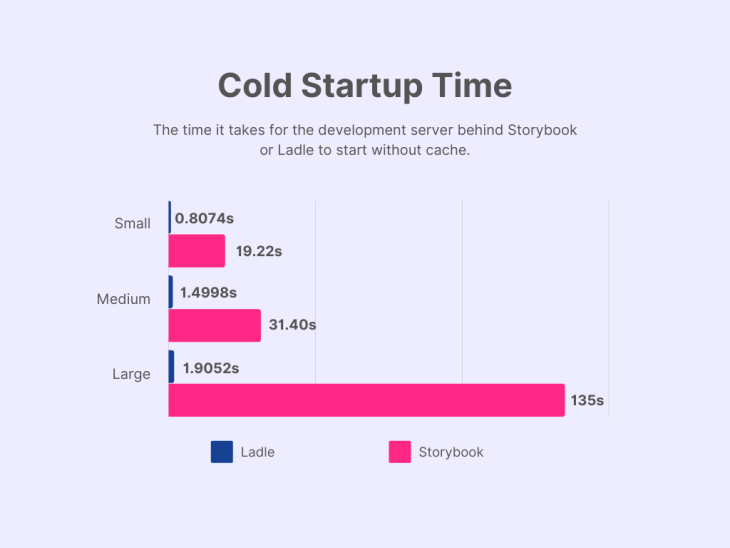
At first glance, we can spot an increasing trend in the cold startup time as the size of the project and the number of stories grow. This applies to both Ladle and React and is a trend we expected to observe.
Another expected observation is that Ladle outperforms Storybook no matter the size of the project. The degrees of speedups in our experiment are a factor of 71, 21, and 23 for the large, medium, and small-sized projects, respectively.
While the difference in performance improvements between those two projects is significant, the difference between medium-sized and small-sized projects isn’t.
Hot startup time is a metric that developers will likely encounter more frequently than cold startup time. More often than not, when starting the development server of either tool, the cache will still be valid and a large portion of the initial setup can be ignored.
Like the cold startup time, a lower hot startup time means less waiting and is thus considered better.
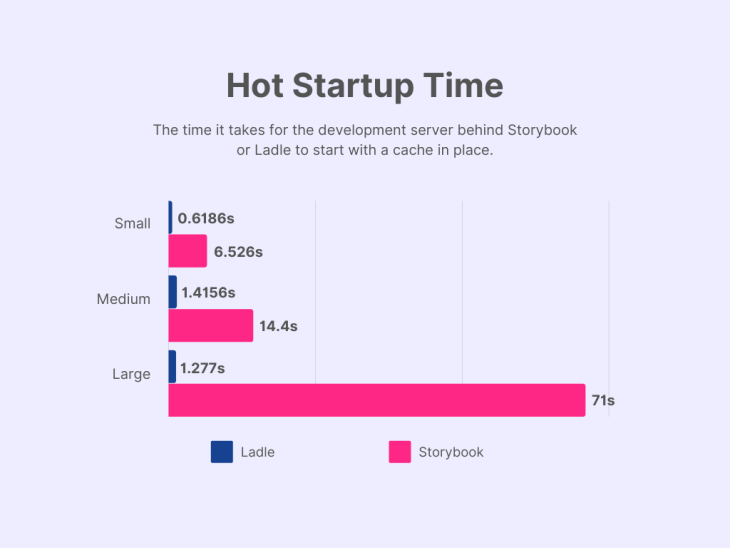
In the case of Storybook, we can once again observe that the startup time increases as the size of the project increases, even with a cache in place.
Unexpectedly, for Ladle, the hot startup time for our large project is shorter than for our medium project. While the difference is not significant, it might indicate that Ladle’s performance isn’t strictly limited by the number of stories in the project.
The difference in performance between Ladle and Storybook for the hot startup time is as follows:
Once again, the measurements indicate a similar gain in performance for small and medium-sized projects, while the difference is more notable for large-sized projects.
The reload time of either tool is most likely something that developers will come across the most. This metric is the time that it takes for the development server to rebuild and re-serve the relevant files to the developers after detecting a change. The higher the reload time, the longer developers have to wait for their code changes to reflect in what they see on the screen. Thus, a lower number indicates a shorter reload time and is considered better.
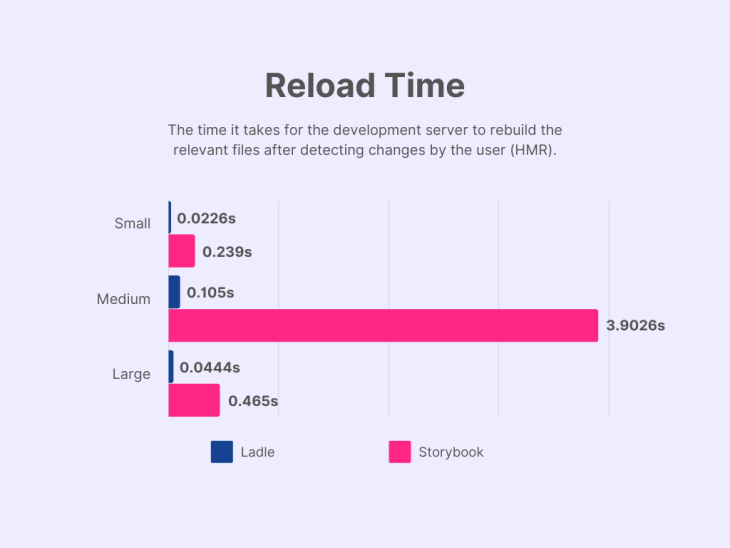
Both the small- and large-sized projects show a nearly identical performance gain for the reload time when swapping out Storybook for Ladle. For the small project, reload time goes down, from 0.239s to 0.0226s (a factor of 10.58), while for the latter it goes from 0.465s to 0.0444s (a factor of 10.47). The biggest performance gain came from the medium-sized project, which had a factor of 37.
The most surprising observation is that the medium-sized project had the worst performance in this metric for both tools. Storybook almost spent 4s on the reload time for this project, while the large-sized project never even came close to hitting the 1s mark. Even Ladle spent significantly more time for its standards on reloading this project compared to the large-sized project.
The build size metric is about the size of the production build of either tool. These assets are mainly used for statically hosting the design system, either internally or externally. The relevancy of this metric doesn’t necessarily apply to all users of Storybook or Ladle, since that depends on how they decide to host the application. But for the scenarios in which they do host the app themselves, the build size impacts the performance of the hosted application. A smaller build size results in a better performance of the application.

For Storybook, the build size stays relatively the same across the different projects that were tested in this experiment; all of them output roughly 7MB worth of assets. Ladle, on the other hand, produces a build size that’s 8.75x smaller than the small-sized project output, which was below 1MB.
The medium and large-sized projects still produced relatively small bundles of respectively 1.8MB and 3.8MB. However, as the size of the project increases, the size factor relative to Storybook decreases, to 3.89 and 1.76, respectively.
For the sake of this article and small scale experiment, I made several decisions to keep it in scope, which involved altering parts of the methodology while attempting to address unforeseen difficulties or anything outside the methodology. Here, I’ll state and briefly discuss them. In turn, these are meant to serve as pointers towards improving future work or extending upon this experiment.
The projects used in this experiment were chosen based on their size and represent the main different stages of a frontend project in which either Ladle or Storybook could be considered. The exact details regarding these scenarios are stated in the methodology section.
However, the number of stories in a design system isn’t always a perfect reflection of a project’s size. Unfortunately, the availability of projects in the ecosystem with either Storybook or Ladle implemented imposed limitations on what I could use in this experiment. Despite those limitations, I believe that the selection of projects used in this experiment is still reflective of the scenario that they represent.
No frontend project makes use of both Storybook and Ladle. While that makes absolute sense, it does make it non-trivial to benchmark both tools in a single project.
For this reason, I had to manually install the other tool based on the tool that the projects were using. In the case of react-bootstrap-typeahead, I installed Ladle, while for Base Web I installed Storybook.
While I made sure that the applications would start correctly and load up the stories in a usable state, it’s difficult to confirm that not a single piece of custom configuration or internal code was missed.
Compared to previous benchmarks, our experiments expanded upon them by considering multiple types of projects depending on their size. While that is an improvement, the scale of this experiment is still limited.
In future experiments, one could decide to include more projects per category, expand upon the categories, or perform more than five measurements per metric.
Ladle is marketed as a more performant drop-in alternative to Storybook and the numbers from existing benchmarks are very promising. However, these benchmarks were only focused on its performance in a large-sized project with a tremendous amount of stories, which isn’t a representative scenario for all projects. For this reason, we conducted an experiment to explore the performance differences between Ladle and Storybook in different sizes of projects.
Ultimately, the results in this experiment only enhance the performance-related statements from Ladle. A trend among most of the time-related development metrics was that the biggest difference in performance was found in large-scale projects. Compared to this, the medium-sized projects had fewer performance improvements and were not too different from small-sized projects.
But, regardless of these differences between projects, there was one conclusive finding. For all of the metrics in this experiment, the performance gains by adopting Ladle over Storybook were significant no matter the scenario.
Install LogRocket via npm or script tag. LogRocket.init() must be called client-side, not
server-side
$ npm i --save logrocket
// Code:
import LogRocket from 'logrocket';
LogRocket.init('app/id');
// Add to your HTML:
<script src="https://cdn.lr-ingest.com/LogRocket.min.js"></script>
<script>window.LogRocket && window.LogRocket.init('app/id');</script>

Discover how React Fiber works under the hood. Learn how React builds the DOM, handles concurrent rendering, and works alongside React 19 features and the new React Compiler.

Learn how to use Skybridge, an open-source React framework, to build and deploy cross-platform AI apps and interactive UI widgets for ChatGPT, Claude, and MCP clients from a single codebase.

Learn how to set up Meilisearch, index documents, and build keyword, semantic, and hybrid search with AI-powered retrieval.

Compare pnpm and npm across security defaults, disk usage, dependency strictness, and workspace policy to decide which package manager fits your project.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

