We all know how important garbage collection (GC) is to modern application development. Depending on your programming language, you may be doing this on your own, like in C. In other languages, it is so hidden that many developers barely know how it is done.

By any measure, garbage collection is always about freeing memory that is no longer being used. The strategies and algorithms to accomplish this vary from one language to another. JavaScript, for example, takes a few interesting paths, depending on whether you’re on a browser or a Node.js server.
But have you ever considered how this process works behind the scenes? Let’s take some time to understand how the JavaScript GC does its magic in both the browser and the server.
The reason why we need GC is due to the many allocations of memory made while programming. You create functions, objects, etc., and all of these take space.
The great advantage of JavaScript when compared to C, for example, is that it does the memory allocation automatically for you. This process is very simple and takes just three well-defined steps:
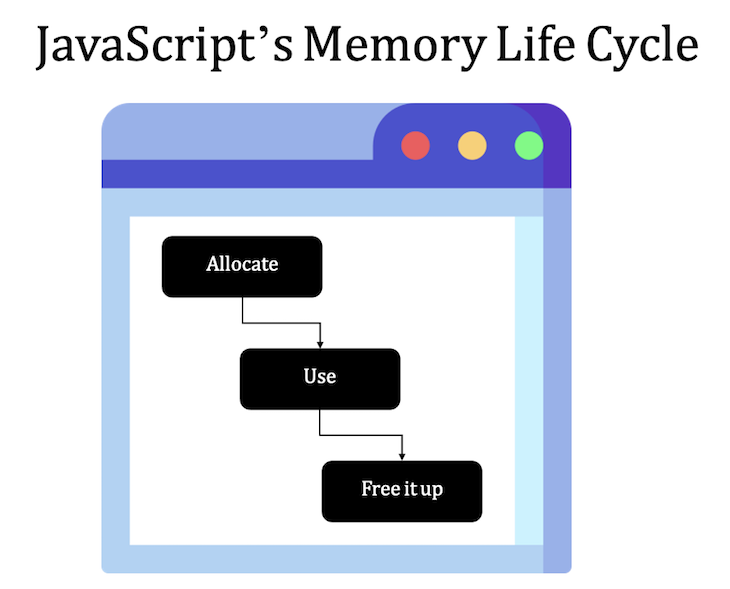
Right, but where does JavaScript store this data, exactly? There are essentially two destinations to which JavaScript sends the data: the first is the memory heap, and the second is the stack.
The heap is another term everybody has heard of. It is responsible for what we call dynamic memory allocation. In other words, this space is reserved for JavaScript to store resources such as objects and functions as they’re needed, without limitations to the amount of memory it could use.
That differs a bit from the stack, which is a data structure used to literally stack elements such as primitive data and references pointing to the real objects. The stack allocation strategy is “safer” due to the fact that it knows how much memory was allocated because it’s fixed.
It’s important to understand that these limitations also vary from vendor to vendor, so pay attention to that when going for large usages of memory.
Take the following code listing as an example:
// heap and stack
const task = {
name: 'Laundry',
description: 'Call Mary to go with you...',
};
// stack
let name = 'Walk the dogs'; // 1
name = 'Walk; Feed the dogs'; // 2
const firstTask = name.slice(0, 5); // 3
Every time you create a new object in JavaScript, space in the heap memory is dedicated to it. Its internal values are primitives, however, which means that they’re going to be stacked within the stack. The same goes for the task reference.
When it comes to special cases such as the use of immutable values (like the primitives in JavaScript), the language always favors new allocations over the use of the previous memory slot.
Here are the explanations for points comments 1–3 in the code example above:
Great, now we know how JavaScript handles memory allocation and where things go when allocated. But how does it free things up?
JavaScript’s garbage collector takes care of it, and the process is as simple as it sounds: once an object is no longer used, the GC releases its memory.
What is not so simple about this is how JavaScript knows which objects are prone to be collected. And this is where the algorithms enter the scene.
As its name suggests, this strategy goes through the resources allocated in memory and searches for those that have zero references pointing to them.
Let’s take the previous code snippet as a reference to get a better understanding:
const task = {
name: 'Laundry',
description: 'Call Mary to go with you...',
};
task = 'Walk the dogs';
So initially, the task object is holding a bunch of internal attributes. Then let’s assume another developer decided that a task could simply be represented as a primitive itself. So now, the first task object has no references pointing to it anymore, which makes it available for GC.
Wait, that can’t be so simple… indeed, it sounds naive! And it is.
However, there is a special edge case you must be aware of: circular dependencies. You probably never thought of them before because JavaScript also knows how to handle them. But usually, they happen this way:
function task(n, d) {
// ...
reporter = { ... };
assignee = { ... };
reporter.assignee = assignee;
assignee.reporter = reporter;
};
myTask = task('Laundry', 'Call Mary to go with you...');
This probably wouldn’t represent a functional task in a real-world application, but it’s enough to imagine a situation in which two objects’ internal attributes reference each other.
This creates a cycle. Once the function’s finished, JavaScript’s reference-counting GC won’t be able to interpret that these two objects can be collected because they still hold references to each other.
That’s a common scenario that can easily lead to memory leaks in real-world apps. To avoid that, JavaScript provides us with a second strategy in the battlefront.
The mark-and-sweep algorithm is famous for being used by many programming languages for garbage collection. In short, it makes use of a clever approach to determine whether a given object can be reached from the root object.
In JavaScript, the root object is the global object if you’re on a Node.js application; if you’re on the browser, it’s window.
The algorithm starts from the top and goes down the hierarchy again and again marking each of the objects that can be reached (i.e., that are still being referenced) from the root and sweeping the ones that cannot.
Can you see now how the GC will collect both reporter and assignee from the previous example?
Node (as well as Chrome) is powered by V8, Google’s open-source JavaScript engine. The important notes take place within Node’s heap memory.
Let’s take a look at the representation below:
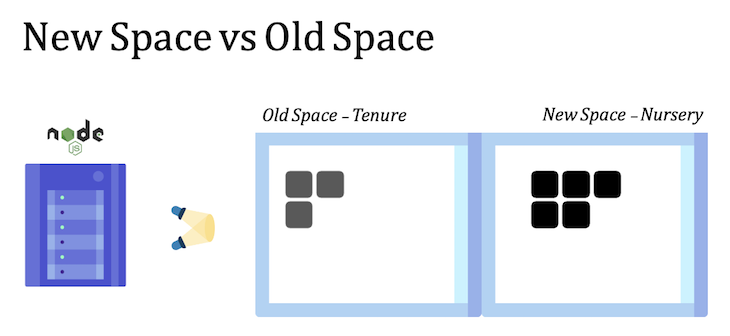
Node’s heap is divided into two main parts: the new space and the old space. As the names suggest, the former is where new objects (known as the young generation) are allocated, while the latter is the destination for objects that have survived for long periods (the old generation).
Consequently, garbage collection of objects in the new space occurs faster than in the old space. On average, up to 20 percent of the objects from the young generation survive log enough to get promoted into the old generation.
Because of all these peculiarities, V8 makes use of an additional GC strategy: the scavenger.
As we’ve seen, it’s more costly for Node to free things up in the old space. When it must do so, the mark-and-sweep algorithm runs to achieve the goal.
The scavenger GC exclusively collects garbage from the young generation. Its strategy consists of selecting the surviving objects and moving them to a so-called new page. For this step to happen, V8 ensures that at least half of the young generation remains empty; otherwise, it would face problems with lack of memory.
The idea is to track all the references into the young generation without the need to go through the entire old generation. Additionally, the scavenger also keeps a set of references from the old space that point to objects in the new space.
The process then moves the surviving objects to the new page in chunks, on and on, until the whole GC is finished. Finally, it updates the pointers for the original objects that were moved.
Of course, this was just an overview of the GC strategies in the JavaScript universe. The process is far more complex and deserves further reading. I strongly recommend the famous Mozilla GC docs and V8’s talk about the Orinoco garbage collector as complementary resources.
It’s essential to keep in mind that, as with many other languages, we can’t know for certain when the GC will run. Since 2019, it’s up to the GC to perform the clean-up from time to time, and you can’t trigger it yourself.
Other than that, the way you code very much impacts how much memory JavaScript will allocate. That’s why it’s very important to know the specificities of the garbage collector memory allocation, and strategies of freeing-up memory. There are several open-source lint and hint tools to help you out identifying and analyzing these leaks, as well as other pitfalls in your code. Go for them!
There’s no doubt that frontends are getting more complex. As you add new JavaScript libraries and other dependencies to your app, you’ll need more visibility to ensure your users don’t run into unknown issues.
LogRocket is a frontend application monitoring solution that lets you replay JavaScript errors as if they happened in your own browser so you can react to bugs more effectively.
LogRocket works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and @ngrx/store. Instead of guessing why problems happen, you can aggregate and report on what state your application was in when an issue occurred. LogRocket also monitors your app’s performance, reporting metrics like client CPU load, client memory usage, and more.
Build confidently — start monitoring for free.

I migrated 20 production-style components from Tailwind to StyleX. Here’s what the data showed about LOC, CSS bundle size, build time, and type safety.

A guide for using JWT authentication to prevent basic security issues while understanding the shortcomings of JWTs.

Discover how to build, render, and automate product demo videos with Remotion, replacing traditional screen recordings with reusable React code.

Chrome’s Modern Web Guidance embeds modern web platform skills into AI coding agents, helping them choose native HTML, CSS, and browser APIs over legacy patterns.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

