Web development has taken a fascinating turn with the introduction of WebGPU, a new API that allows web applications to directly access a device’s Graphics Processing Unit (GPU). This development is significant, as GPUs excel at complex computations.
One project that illustrates the potential of WebGPU is WebGPT. It’s a simple application written in JavaScript and HTML, built to showcase the capability of the WebGPU API.
In this post, we’ll discuss why WebGPT is important and how to implement it both locally and in-browser. Let’s go!
Jump ahead:
Before we delve into the practical implementation of WebGPT, let’s briefly examine how it works under the hood.
WebGPT is a JavaScript and HTML implementation of a transformer model, a specific machine-learning model designed to process sequence data efficiently. In natural language processing (NLP), sequence data often refers to text, where the order of words and characters is crucial to their meaning; the parts of a sequence are as important as the whole.
Transformer models are machine learning models that excel at handling NLP sequence data. These models form the basis for many state-of-the-art natural language processing models, including GPT (Generative Pretrained Transformer).
WebGPT’s transformer model is designed to work with WebGPU, an API that allows web applications to access and use a device’s GPU. GPUs are particularly good at performing the type of parallel computations that machine learning models require, making them a powerful resource for WebGPT.
Before WebGPU, applications had to rely primarily on the device’s central processing unit (CPU) or older, less efficient APIs like WebGL. In contrast, WebGPT uses a transformer model explicitly designed to function in the browser using the WebGPU API.
When WebGPT receives input, it uses its transformer model to process the data. It can perform computations locally on the user’s device, thanks to the WebGPU API. Then, results are returned directly in the browser, leading to fast and efficient execution.
Bringing such powerful machine learning models to the browser has profound implications for web development, including:
WebGPT is designed to be simple to use: it only requires a set of HTML and JavaScript files to function. However, since WebGPU is a fairly new technology, you need a browser compatible with WebGPU.
As of July 2023, Chrome v113 supports WebGPU. An alternative is to install Chrome Canary or Edge Canary to ensure compatibility.
You can try out WebGPT directly on its demo website at https://www.kmeans.org. Loading model weights remotely can be slower than loading them locally, so for a more responsive experience, it’s recommended to run WebGPT locally when possible.
To run WebGPT locally, follow these steps:
git clone https://github.com/0hq/WebGPT.git
git lfs install
git lfs pull
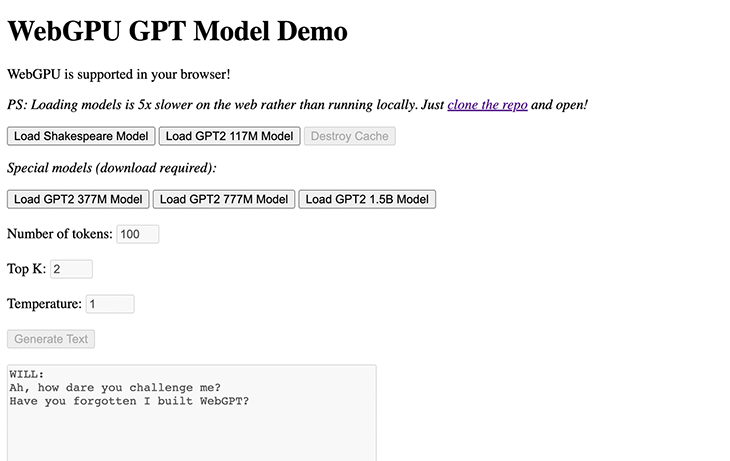
Click any of the Load Model buttons to load the model weights. After that, you can enter text into the input box and click Generate to generate text based on the input.
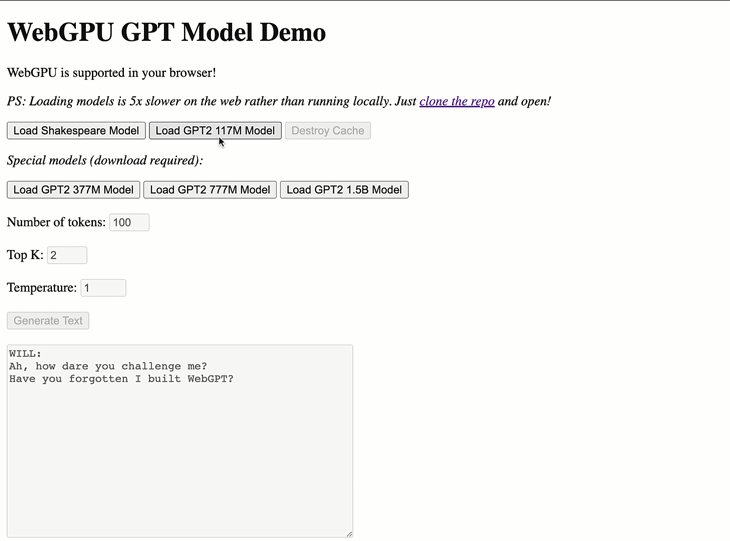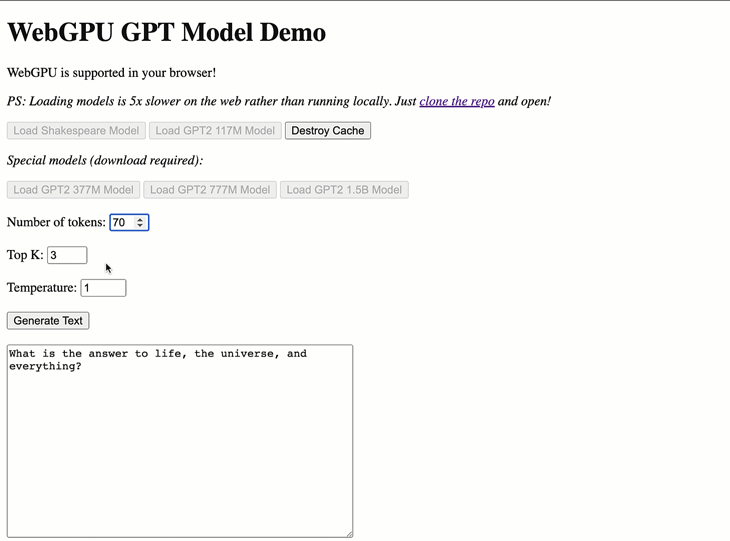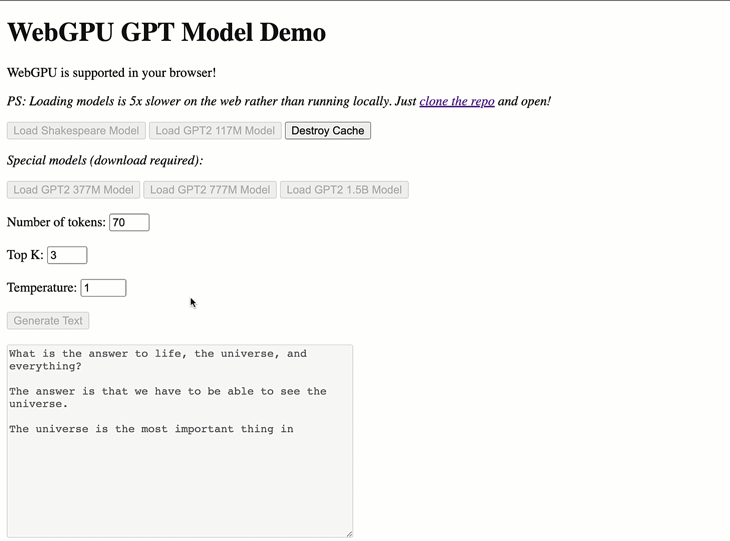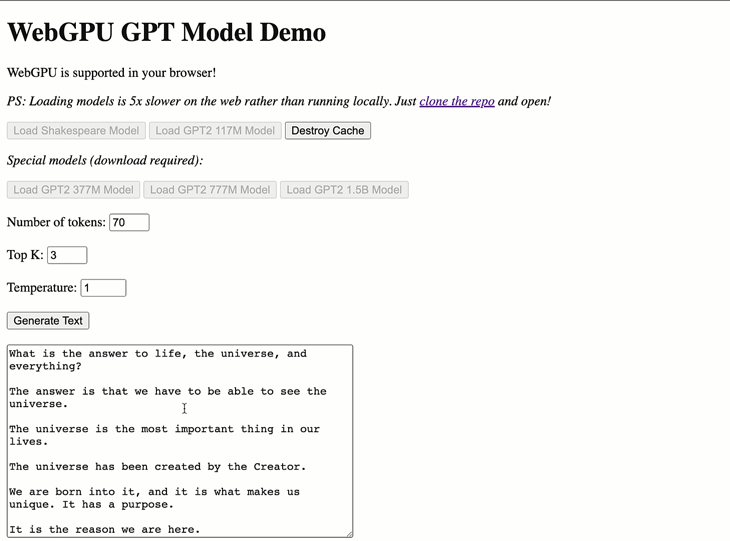
WebGPT has two built-in models: a small GPT-Shakespeare model and GPT-2 with 117 million parameters. If you want to use a custom model, check the other/conversion_scripts directory in the repository for scripts to convert PyTorch models into a format that WebGPT can use.
Here’s what our directory looks like:
Since WebGPT is built on WebGPU, it’s important to understand the challenges and limitations of WebGPU. While WebGPU is a promising technology, it’s still a relatively new API, and as such it has some challenges to overcome. Some of these include:
As the API matures and more browsers support it, we can expect to see these challenges addressed. In the meantime, tools like WebGPT can help with the experimentation and adoption of WebGPU.
GPT and similar models are primarily run on servers due to their high computational demands; however, WebGPT demonstrates that these models can be run directly in the browser, offering a performance that can potentially rival server-based setups.
With the capabilities offered by technologies like WebGPU and projects like WebGPT, we could expand our use of transformer models like GPT by quite a bit. As the technology matures and optimization improves, we could see even larger models running smoothly in the browser.
This could increase the availability of advanced AI features in web applications, from more sophisticated chatbots to robust, real-time text analysis and generation tools, and even accelerate research and development in transformer models. By making it easier and cheaper to deploy these models, more developers and researchers will have the opportunity to experiment with and improve upon them.
Bringing advanced machine learning models to the browser through WebGPU opens up many opportunities for developers, and it presents a vision of a future where web applications are more powerful, responsive, and privacy-conscious.
While the technology is still relatively new and has challenges to overcome, such as optimizing performance and ensuring stability with larger models, the potential benefits are significant. As developers start to embrace and experiment with these tools, we can expect to see more impressive implementations like WebGPT and new web applications that leverage in-browser machine learning.
Give WebGPT a try and let me know what you think in the comments. If you would like to keep in touch, consider subscribing to my YouTube channel and following me on LinkedIn or Twitter. Keep building!
There’s no doubt that frontends are getting more complex. As you add new JavaScript libraries and other dependencies to your app, you’ll need more visibility to ensure your users don’t run into unknown issues.
LogRocket is a frontend application monitoring solution that lets you replay JavaScript errors as if they happened in your own browser so you can react to bugs more effectively.
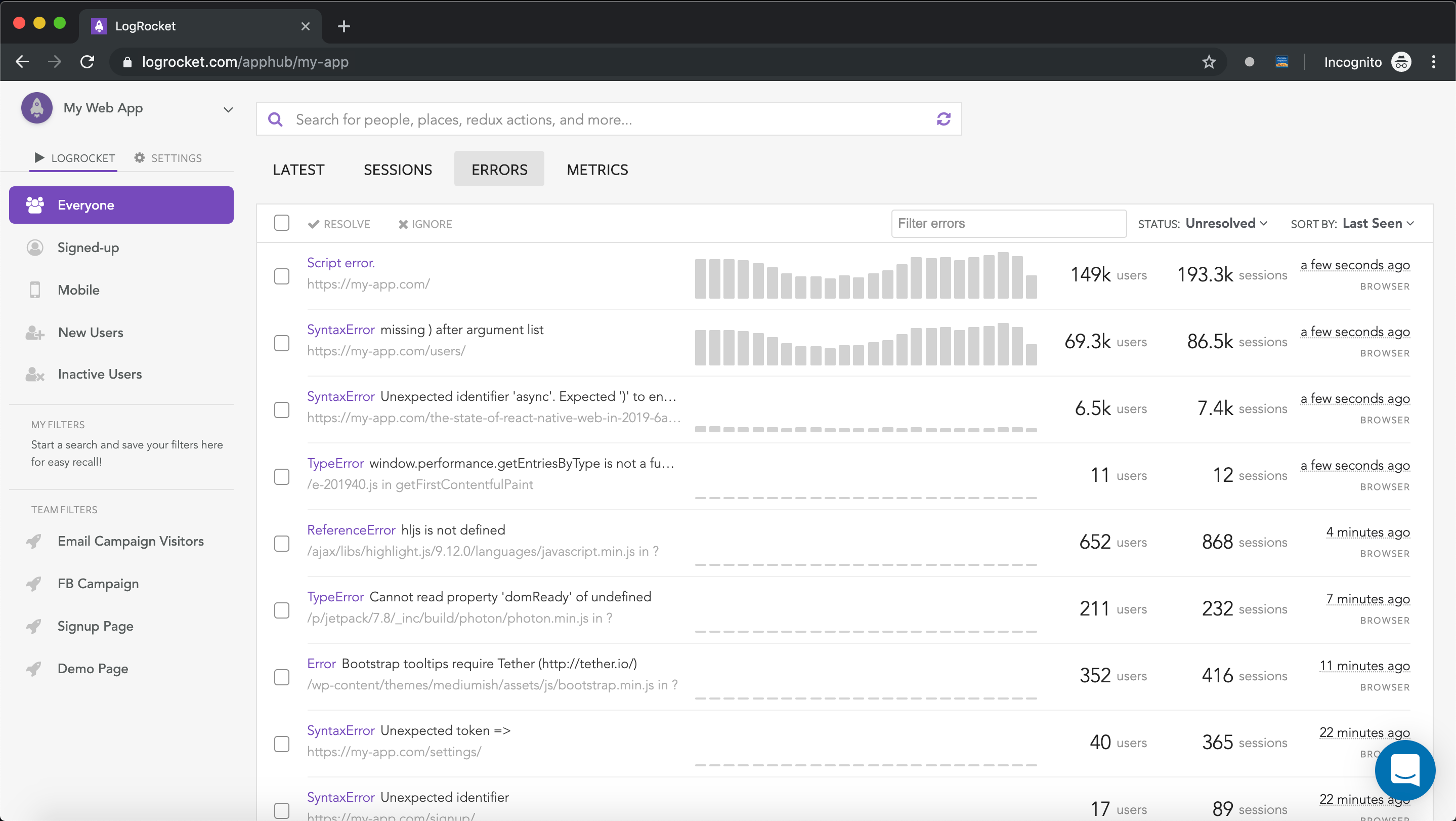
LogRocket works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and @ngrx/store. Instead of guessing why problems happen, you can aggregate and report on what state your application was in when an issue occurred. LogRocket also monitors your app’s performance, reporting metrics like client CPU load, client memory usage, and more.
Build confidently — start monitoring for free.

Learn how to protect full-stack projects from NPM supply chain attacks with a practical security checklist.

Explore 15 essential MCP servers for web developers to enhance AI workflows with tools, data, and automation.

Learn how contrast-color() automatically picks accessible text colors using native CSS, without JavaScript.

Learn how to build a harness-style AI workflow using Claude Code with specialized Dev, QE, and Ops subagents, gated handoffs, MCP telemetry, and LEARNING.md.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

