Third-party packages, compilers, and bundlers are magic behind the curtain. Due to lack of time and massive competition, we don’t worry enough about the low-level stuff to know what’s exactly happening behind the scenes in these third-party packages.

In this article, we are going to build a file upload service with vanilla JavaScript from scratch. The goal is to build this with no external libraries to understand some of JavaScript’s core concepts. We will be reading the file uploaded by the user on the frontend and streaming it in chunks to the backend, storing it there.
Here’s a quick look at what we will be making:
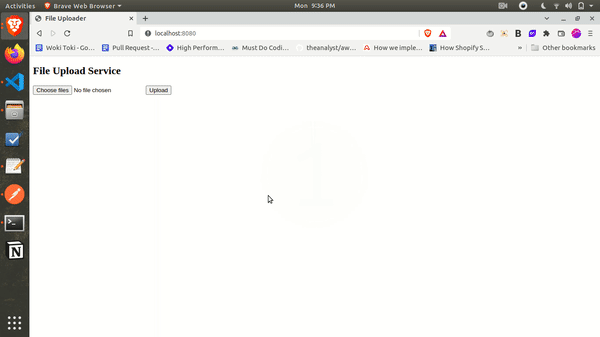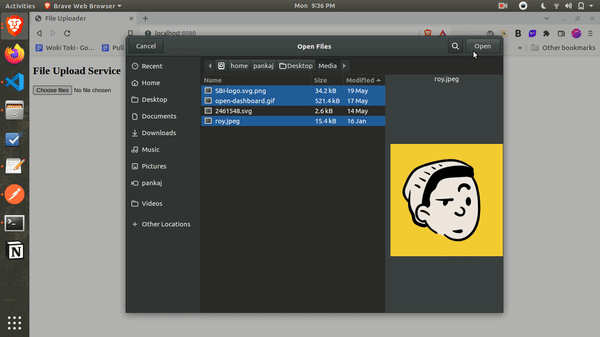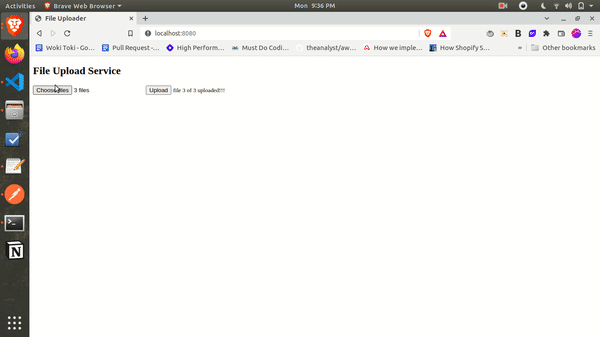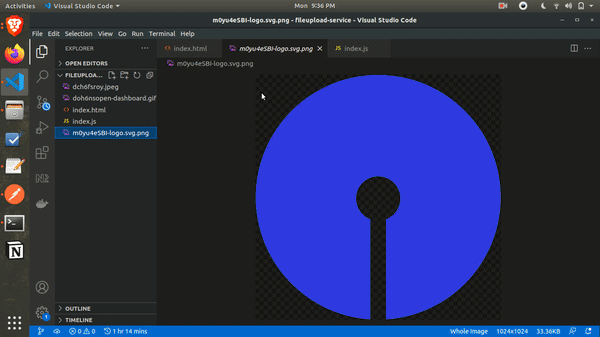
Let’s dig in.
We are going to make use of the beautiful, inbuilt HTTP package to set up the backend server.
First, we need to create a new folder for the project.
mkdir fileupload-service
After doing so, we need to create an index.js file that would be the entry point of our backend server.
touch index.js
After this, create the HTTP server.
const http = require('http'); // import http module
const server = http.createServer(); // create server
server.listen(8080, () => {
console.log('Server running on port 8080') // listening on the port
})
The above code is pretty self-explanatory. We have created an HTTP server, running on port 8080.
The next step is to set up the frontend. As we are not doing anything fancy, we will create a basic HTML file with file input and an upload button, which will initiate the uploading process when clicked. There would be a tiny status text that would declare the status of the file upload.
In vanilla JS, to add an action on any button click, we can simply attach an event listener.
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>File Uploader</title>
</head>
<body>
<h2>File Upload Service</h2>
<input type="file" id="file">
<button id="upload">Upload</button>
<small id="status"></small>
<script>
const file = document.getElementById('file');
const upload = document.getElementById('upload');
const status = document.getElementById('status');
upload.addEventListener('click', () => {
console.log('clicked the upload button!');
})
</script>
</body>
</html>
Users can select the file and upload it by clicking on the upload button. Easy-peasy!
To serve this HTML file on calling the home route, we need to send this file from the backend. The simplest approach is below.
server.on('request', (req, res) => {
if(req.url === '/' && req.method === 'GET') {
return res.end(fs.readFileSync(__dirname + '/index.html'))
}
})
N.B., the
server.on('request')method is used to listen to all HTTP requests in a Node backend server.
As our backend server is up and running, we need a way to read the file on the frontend. To do so, we are going to use the FileReader object. It lets web applications asynchronously read the contents of files (or raw data buffers) stored on the user’s computer, using File or Blob objects to specify the file or data to read.
The syntax to read a file on the client-side using FileReader object is the following.
const fileReader = new FileReader(); // initialize the object fileReader.readAsArrayBuffer(file); // read file as array buffer
We can access selected input files under the files field for the input. Currently, we are only building it for a single file upload, but later on, we can extend it for multiple file uploads as well.
const selectFile = file.files[0];
To read a file, FileReader provides a couple of methods.
FileReader.readAsArrayBuffer() — read file as array buffer
FileReader.readAsBinaryString() — read the file in raw binary data
FileReader.readAsDataURL() — read the file and returns result as a data url
FileReader.readAsText() — If we are aware of the type of file as text, this method is useful
For our use case, we will be using the readAsArrayBuffer method to read the file in bytes and stream it to the backend over the network.
To track reading the file on the client side, FileReader provides a couple of event listeners like onload, onprogress, etc.
Our goal is to read the file, split it into chunks, and upload it to the backend, so we will be using the onload event, which is triggered once the file reading is completed.
You might wonder, why we are not using the onprogress method to make the application for a fully streamable file upload? But the issue with the onprogress method is it does not tell the new read chunk, it tells the complete data read until now. So, we use the onload method.
Once the file is completely read, we split it into small chunks and stream it to the backend.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>File Uploader</title>
</head>
<body>
<h2>File Upload Service</h2>
<input type="file" id="file">
<button id="upload">Upload</button>
<small id="status"></small>
<script>
const file = document.getElementById('file');
const upload = document.getElementById('upload');
const status = document.getElementById(status);
upload.addEventListener('click', () => {
// set status to uploading
status.innerHTML = ‘uploading…’;
const fileReader = new FileReader();
fileReader.readAsArrayBuffer(file.files[0]);
fileReader.onload = (event) => {
console.log('Complete File read successfully!')
}
});
</script>
</body>
</html>
You might have noticed we are using a <small> tag that changes to uploading... as we start uploading and becomes uploaded!!! once the file is uploaded on the backend successfully!
Sometimes, the file size can be large, so it’s not a good practice to send the complete file at once. Some of the proxy servers such as Nginx might block it because it seems malicious.
So, we will be splitting this file into a chunk size of ~5000 bytes and sending it to the backend one by one.
If we carefully look at the event parameter, we find out that, once it has read the file, we can access the content of the file as an array buffer in the event.target.result field.
We are going to split the array buffer of this file into chunks of 5000 bytes.
// file content
const content = event.target.result;
// fix chunk size
const CHUNK_SIZE = 5000;
// total chunks
const totalChunks = event.target.result.byteLength / CHUNK_SIZE;
// loop over each chunk
for (let chunk = 0; chunk < totalChunks + 1; chunk++) {
// prepare the chunk
let CHUNK = content.slice(chunk * CHUNK_SIZE, (chunk + 1) * CHUNK_SIZE)
// todo - send it to the backend
}
Now, we need to send these chunks to the backend. To hit the backend server, my old friend fetch is here to the rescue.
Before we send the chunks to the backend, we need to make sure we do it in order otherwise the file will be corrupted.
The second thing is to use async await while uploading because we don’t want to flood the backend server with requests.
fileReader.onload = async (event) => {
const content = event.target.result;
const CHUNK_SIZE = 1000;
const totalChunks = event.target.result.byteLength / CHUNK_SIZE;
// generate a file name
const fileName = Math.random().toString(36).slice(-6) + file.files[0].name;
for (let chunk = 0; chunk < totalChunks + 1; chunk++) {
let CHUNK = content.slice(chunk * CHUNK_SIZE, (chunk + 1) * CHUNK_SIZE)
await fetch('/upload?fileName=' + fileName, {
'method' : 'POST',
'headers' : {
'content-type' : "application/octet-stream",
'content-length' : CHUNK.length,
},
'body': CHUNK
})
}
status.innerHTML = ‘uploaded!!!’;
}
As you can see, we have added the file name as a query parameter, and you might wonder why we are sending the file name as well. See, all the API calls to the backend server are stateless, so to append the content to a file, we need to have a unique identifier, which would be the file name for our case.
Because the user might want to upload the file with the same file name to make sure the backend does work as expected, we need a unique identifier. For that, we use this beautiful one-liner:
Math.random().toString(36).slice(-6)
Ideally, we should not send any custom header because most of the proxies such as Nginx or HAProxy might block it.
Because we have completely set up the frontend, the next step is to listen to the file chunks and write them to the server.
To extract the file name from the query params of the request, we use the below piece of code.
const query = new URLSearchParams(req.url); const fileName = query.get(‘/upload?fileName’);
So, our final code looks like this:
server.on('request', (req, res) => {
if(req.url === '/' && req.method == 'GET') {
return res.end(fs.readFileSync(__dirname + '/index.html'))
}
if(req.url=== '/upload' && req.method == 'POST') {
const query = new URLSearchParams(req.url);
const fileName = query.get(‘/upload?fileName’);
req.on('data', chunk => {
fs.appendFileSync(fileName, chunk); // append to a file on the disk
})
return res.end('Yay! File is uploaded.')
}
})
So far, we have built a beautiful single file upload application with vanilla JS. Now, our next goal is to extend our current implementation to support multiple file uploads as well.
Let’s get on it.
If we clearly look at it, we see that the backend is smart enough to smoothly work for multiple file uploads as well because it has a very simple job: take a chunk and append it to the respective file name received in the request. It is completely independent of how many files are being uploaded from the frontend.
So, let’s take the advantage of it and improve our application for it.
The first step to accepting multiple file selections on the UI is to modify the file input. Currently, it by default takes single file input. To accept more than one file, we use the multiple option in input:
<input type="file" id="files" multiple>
Now we are all set to accept multiple files in the file input. And in case you missed it, we have updated the id of the file input from file to files as well.
We are aware of the fact that all input files are now accessible via the files.files array. So, our thought is pretty simple: we will iterate over the array of selected files, break it into chunks one by one, and stream it to the backend server and store it there:
for(let fileIndex=0;fileIndex<files.files.length;fileIndex++) {
const file = files.files[fileIndex];
// divide the file into chunks and upload it to the backend
}
Our good friend for loop makes it very simple to go over each file and upload it to the backend.
To keep track of file upload status, we maintain a variable that gets updated on each file upload.
So, our file upload script looks like this:
const files = document.getElementById('files');
const upload = document.getElementById('upload');
const status = document.getElementById('status');
upload.addEventListener('click', () => {
// set loading status
status.innerHTML = 'uploading...';
let fileUploaded = 0;
for(let fileIndex = 0; fileIndex < files.files.length; fileIndex++) {
const file = files.files[fileIndex];
const fileReader = new FileReader();
fileReader.readAsArrayBuffer(file);
fileReader.onload = async (event) => {
const content = event.target.result;
const CHUNK_SIZE = 1000;
const totalChunks = event.target.result.byteLength / CHUNK_SIZE;
const fileName = Math.random().toString(36).slice(-6) + file.name;
for (let chunk = 0; chunk < totalChunks + 1; chunk++) {
let CHUNK = content.slice(chunk * CHUNK_SIZE, (chunk + 1) * CHUNK_SIZE)
await fetch('/upload?fileName=' + fileName, {
'method' : 'POST',
'headers' : {
'content-type' : "application/octet-stream",
'content-length' : CHUNK.length
},
'body' : CHUNK
})
}
fileUploaded += 1;
status.innerHTML = `file ${fileUploaded} of ${files.files.length} uploaded!!!`;
}
}
})
I’m not sure if this came to your mind by looking at our implementation, but we have achieved multiple file uploads in parallel as well. If you clearly look at the network tab, you see that file chunks are being uploaded in parallel, but yes, files are themselves being uploaded in a serial manner.
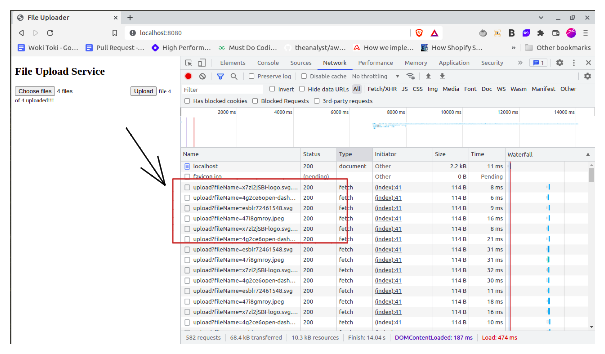
As are we not waiting for the previous file to upload completely, all the files are being uploaded in parallel. As our backend is stateless, this functionality is perfectly working.
If you are keen on exploring the GitHub repository of the codebase, you can find it here.
We learned how to build a file upload service with vanilla JS. Obviously, it’s not the most efficient implementation, but it’s more than enough to give you a fair idea of a couple of core concepts.
We can extend it to have a progress bar while uploading, retry chunk upload in case of failure, upload multiple files, upload multiple chunks at once, and so on.
I’m active on Twitter as the2ndfloorguy and would love to hear your thoughts. And in case you are interested in my other articles, you can find them here.
Debugging code is always a tedious task. But the more you understand your errors, the easier it is to fix them.
LogRocket allows you to understand these errors in new and unique ways. Our frontend monitoring solution tracks user engagement with your JavaScript frontends to give you the ability to see exactly what the user did that led to an error.
LogRocket records console logs, page load times, stack traces, slow network requests/responses with headers + bodies, browser metadata, and custom logs. Understanding the impact of your JavaScript code will never be easier!
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now
Discover how to use Gemini CLI, Google’s new open-source AI agent that brings Gemini directly to your terminal.

This article explores several proven patterns for writing safer, cleaner, and more readable code in React and TypeScript.

A breakdown of the wrapper and container CSS classes, how they’re used in real-world code, and when it makes sense to use one over the other.

This guide walks you through creating a web UI for an AI agent that browses, clicks, and extracts info from websites powered by Stagehand and Gemini.



8 Replies to "How to build a file upload service with vanilla JavaScript"
Many thanks. Useful article. Quotes for `status` was missed in “Set up the frontend” section.
Good catch, thanks for that. Updated
Thanks for your article.
After all, what a great site and informative posts.
Glad to read this article. Very Good!
Always had issued doing that. Just got cleared. BIG THANKS
Thank you! I have a question though, when I implemented it this way, some of the chunks went missing. The res.on(‘data’) part wasn’t getting called. I did manage to fix it with doing the appendFileSync() inside of a ‘for await(const chunk of req)’ , but I’m not sure what the problem was. I was wondering if you had any clues..
That appears to be excellent however i am still not too sure that I like it. At any rate will look far more into it and decide personally!
Such a worthy information. Amazing to read