Writing the perfect app is only half of the job of a developer. How you design your app’s deployment strategy and monitor it throughout its lifecycle can determine the success or failure of your project, regardless of whether you’re using Heroku, Docker, or Kubernetes to manage your infrastructure.

In this article, we’ll explore a few best practices for managing production deployment in Node.js applications. First, we’ll review how Node.js works internally, then clarify production deployment requirements at the process level. Finally, we’ll explore possible approaches to managing production deployment.
Keep in mind that there are countless ways to perform production deployments in the Node.js ecosystem. Therefore, this article will focus solely on Node.js process management in production environments instead of containerization or fully-managed apps. Let’s get started!
To better understand the requirements for production process management, let’s consider how Node.js operates internally as an asynchronous, event-driven, and single-threaded platform.
Node.js can execute time-consuming operations asynchronously without blocking other operations. For example, Node.js can concurrently process multiple network requests by ordering callbacks to be executed in a FIFO queue, the Event Loop.
As an event-driven environment, Node.js propagates state changes and events internally. For example,
A single instance of Node.js runs in a single thread. Even in multi-core systems, a Node.js process won’t take advantage of more than one CPU.
Now that we’ve revisited the primary characteristic defining Node.js, let’s dive into the intrinsic requirements for production deployments at the process level.
A successful production deployment is comprised of many moving pieces, for example, source code management, continuous integration pipelines, and continuous delivery pipelines. Monitoring your app’s processes and lifecycle once deployed is only one part of a larger process.
Before we can consider the different possible strategies for managing an app’s lifecycle, let’s review the requirements and best practices for a successful deployment strategy.
For example, let’s imagine that we’re building a web server that serves HTTP requests, a very common use case for Node.js.
When running a web server in production, it’s safe to assume that it must be continuously active in order to respond to incoming HTTP requests. The web server must be resilient and able to recover gracefully from unexpected errors, crashes, and unhandled exceptions. In Node.js, a single unhandled exception has the potential to crash the entire process.
Secondly, once deployed, the server should fully utilize the infrastructure underneath. When deploying Node.js through cloud providers, multiple vCPUs are often available under the hood. By default, a Node.js process only takes advantage of one CPU, missing out on many potential performance gains.
Finally, as our web server gains more traffic, we need to monitor the Node.js process to spot faulty behaviors like memory leaks and identify potential bottlenecks. Debugging production issues on non-monitored processes is like coding using voice commands, which is not for the faint-hearted!
You should also consider any additional requirements that are specific to Node.js applications, for example, programmed execution for Chrome. While these are out of the scope of this article, they may be worth considering depending on your specific use case.
Now that we understand the main requirements for Node.js process management in production, let’s address them by leveraging PM2, the most popular Node.js process manager.
First, let’s set up PM2 by installing it as an npm package and replacing the script as follows:
// Add pm2 to your app (install it globally for terminal access) npm install pm2 -g // Start your app with: pm2 start app.js // 🎉 Congratulations, your app processes are now managed by PM2!
Let’s see how PM2 addresses the process management level requirements that we described above.
Whenever an unhandled exception is thrown in Node.js, the process will crash and exit. We can’t completely control how often this happens, so it’s crucial to plan conservatively. We can recover process crashes at different levels within our stack, for example, the system process level, the container level, or the server level.
When dealing with a stateless Node.js process that doesn’t rely on the server’s filesystem or memory to keep data between requests, I prefer to handle the crash recovery at the system process level, prioritizing speed. For example, when we restart a process within a container, like Docker, at the container level, the Node.js process startup time will be added to the container’s restart time.
By default, PM2 instantly restarts any process that crashes, increasing resiliency. Although crashing in production is a serious matter, the auto-restart gives you a head start to fix the source of the crash, minimizing the impact on your customers.
Even if a Node.js process is single-threaded, there are several ways that we can tap into the total CPU capacity of the environment that the process is running in.
For one, we could launch multiple instances of our web server process, then manually load balance the requests with an external tool such as NGIX. However, Node.js already provides a way to spawn multiple processes sharing the same port using the Cluster Module.
Additionally, PM2 abstracts away the Cluster Module, allowing for networked Node.js applications to scale to all available CPUs. A command line argument automatically creates as many processes as there are available CPU cores, load balancing the incoming network traffic between them.
When combined with the automatic restart feature, the app becomes way more resilient. PM2 handles each process’s lifecycle in isolation and restarts only what is needed:
// Start the app with as many processes as CPU cores are available pm2 start app.js -i max
While you can manually tap into the JavaScript V8 Engine and collect the data you want, I recommend using a prebuilt application performance monitoring (APM) tool. Luckily for us, PM2 already provides one through the terminal and as a paid web service. You can access valuable information about the app services, like CPU, memory usage, request latency, and console logs.
Once the app is running with PM2,add the following code in the terminal:
pm2 monit
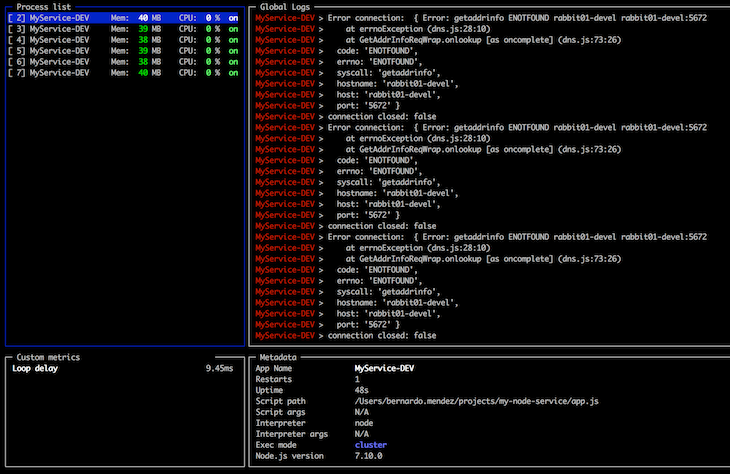
Hopefully, this article has shed some light on the importance of proper Node.js process management in production, an aspect that is often disregarded in my own experience.
Production process management is a complex topic, and PM2 is not a silver bullet. The best solution for your project will depend on the stack your company uses and its existing infrastructure. With that said, it’s worth checking if your production Node.js deployments are benefiting from the infrastructure.
Good process management is just the first step in scaling your Node.js application. Happy coding!
 Monitor failed and slow network requests in production
Monitor failed and slow network requests in productionDeploying a Node-based web app or website is the easy part. Making sure your Node instance continues to serve resources to your app is where things get tougher. If you’re interested in ensuring requests to the backend or third-party services are successful, try LogRocket.

LogRocket lets you replay user sessions, eliminating guesswork around why bugs happen by showing exactly what users experienced. It captures console logs, errors, network requests, and pixel-perfect DOM recordings — compatible with all frameworks.
LogRocket's Galileo AI watches sessions for you, instantly identifying and explaining user struggles with automated monitoring of your entire product experience.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now
This guide walks you through creating a web UI for an AI agent that browses, clicks, and extracts info from websites powered by Stagehand and Gemini.

This guide explores how to use Anthropic’s Claude 4 models, including Opus 4 and Sonnet 4, to build AI-powered applications.

Which AI frontend dev tool reigns supreme in July 2025? Check out our power rankings and use our interactive comparison tool to find out.

Learn how OpenAPI can automate API client generation to save time, reduce bugs, and streamline how your frontend app talks to backend APIs.


