
Whenever you make a search query on Google, YouTube, or Instagram, you get a popover with suggestions that may be close to or exactly what you were thinking. Ever wondered how this auto-complete feature works?
As it turns out, some auto-complete features are powered by a data structure type called a trie (some pronounce it as “tree” and others “try”).
A trie’s structure looks like a tree — the data begins at one origin but branches off to sub-tries and beyond. The trie data structure is ideal for efficiently storing, searching, and retrieving strings from large databases.
In UX design, trie data structures can optimize a user’s experience by outputting logical search results, assisting the user with suggestions, and correcting spelling errors.
Think of spell-checking algorithms and text prediction. We use these additional features on a daily basis, and they seem so effortless, right? Well, it is a bit more complicated, but we’ll break it down in this article.
Let’s further discuss what trie data structures are, review the trie operations, see their applications in UX design, and then get into the pros and cons of using tries.
First of all, why is it called a trie data structure?
“Trie” comes from the word “retrieval” – one of its main functionalities. Tries both store and retrieve data from a large collection of strings. These strings can be any sequence of letters, numbers, spaces, and even symbols surrounded by double-quotations.
The singular word “hello” and the phrase “how to bake a cake in under 20 minutes?” are both considered strings.
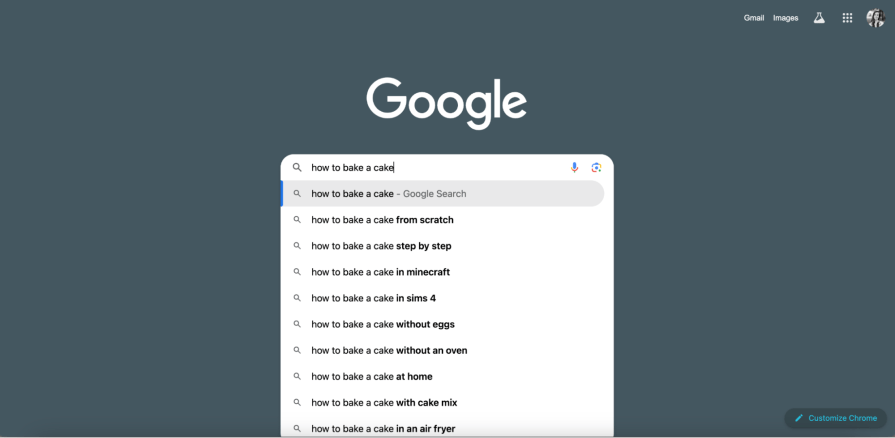
There are countless combinations of strings given the volume of words and numbers in any specific language. But managing an extensive set of strings becomes more doable when trie data structures are implemented.
A trie comprises three main components:
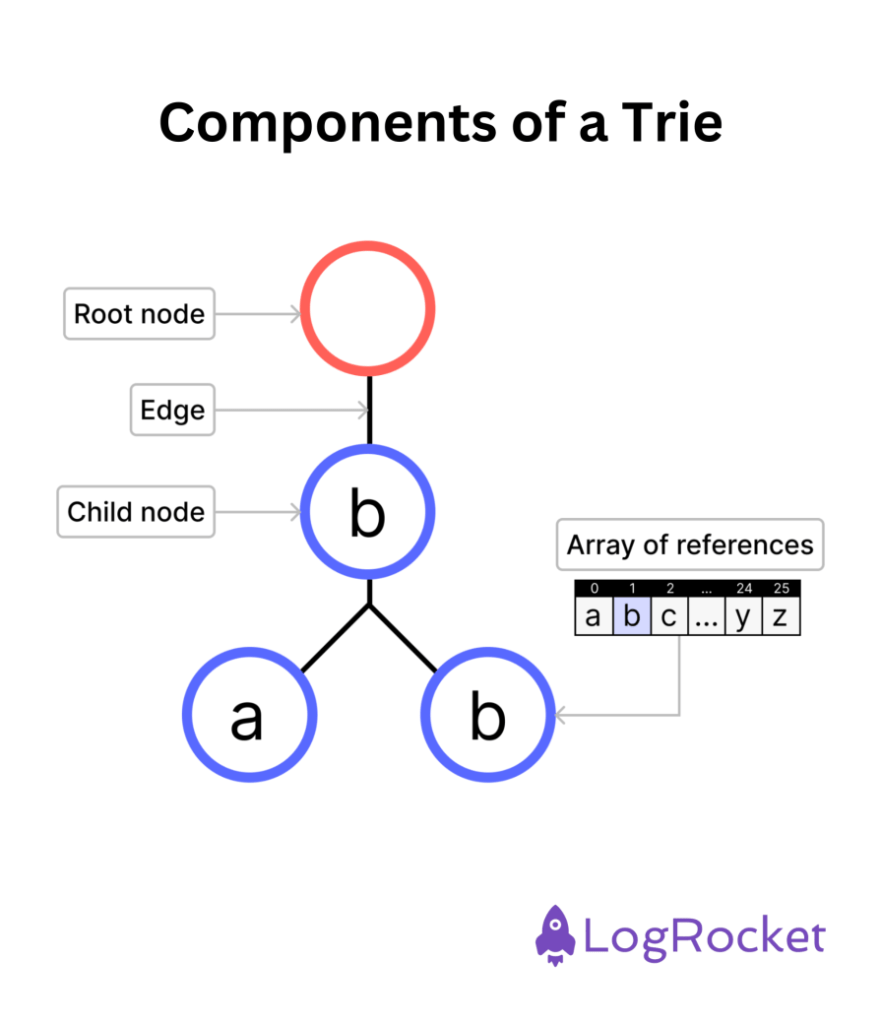
*Note: An array of references can be anything that makes up a string in the trie data structure. For example, there are 26 letters in the English alphabet. If a trie only supports the English alphabet, every node will contain an array that references the 26 possible letters. Since arrays start at 0, the array will span from 0 to 25 (or A to Z).
Let’s look at an example of a trie with the words — baby, bark, bars, and bed.
ba and the other e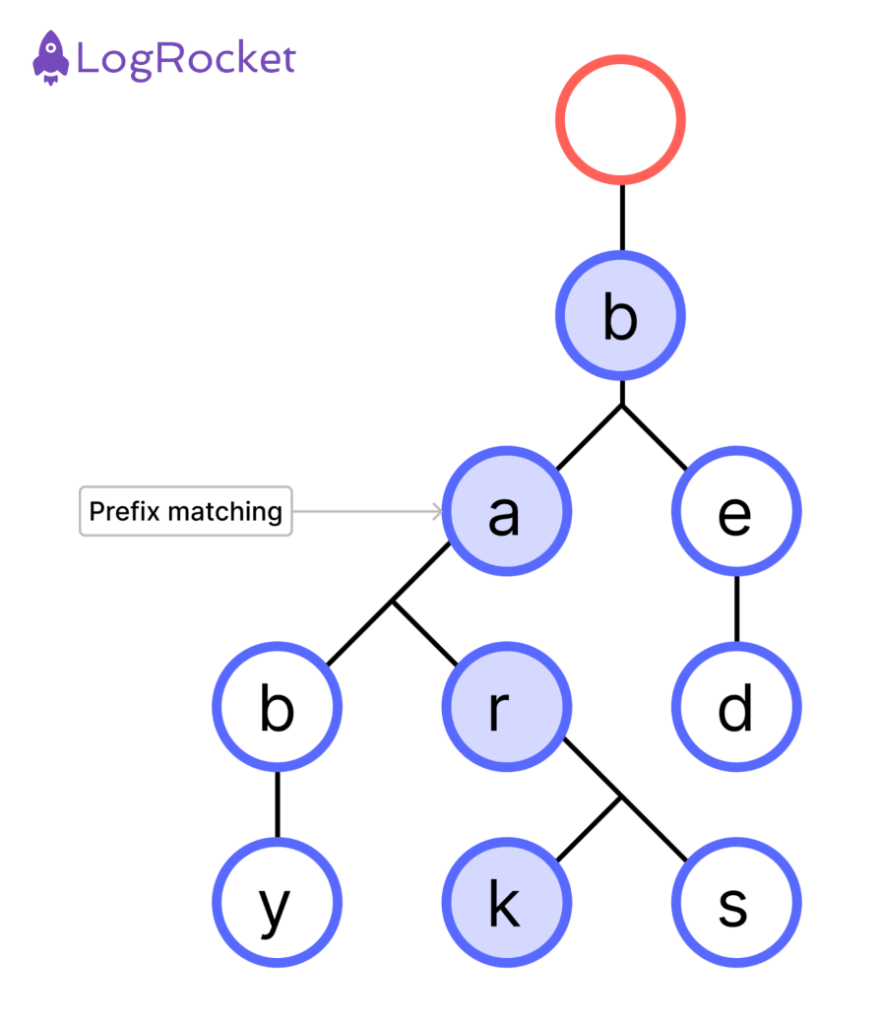
As you can see, prefix matching is used to organize the nodes based on shared references. All words share the prefix “b-” and three words share the prefix “ba-.” Instead of having to list each string in a database individually, strings can be grouped based on their prefixes. This supports better efficiency in how the data is searched and retrieved when called on, as well as saves on storage space.
Now that we’ve explored what a trie is and its benefits of organizing and retrieving data, let’s dive deeper to discuss some trie operations.
When a data structure is being built or used, various operations need to be performed to keep the database updated or correct any errors. For trie data structures, the main operations supported include insertion, searching, and deletion.
I’ll discuss each to explain how a trie works:
The insertion operation can be seen as an “add” tool. If you’re starting with the first few strings in the data structure or inputting the final ones, you’ll use the insertion operation to add the data.
Let’s practice by inserting the string “bark” into a predefined trie with the words — baby and bars.
Here is a code snippet and demo for this insertion operation in JavaScript:
// I have a predefined trie with the words "baby" and "bars"
const trie = {
"b": {
"a": {
"b": {
"y": {
"isEndOfWord": true
}
},
"r": {
"s": {
"isEndOfWord": true
}
}
}
}
};
// Function that inserts a word into the trie
function insertWord(word) {
let currentNode = trie;
for (let i = 0; i < word.length; i++) {
const char = word[i];
// If the character doesn't exist in the current node, create a new node
if (!currentNode[char]) {
currentNode[char] = {};
}
// Moves to the next node
currentNode = currentNode[char];
}
// Marks the end of the word
currentNode.isEndOfWord = true;
}
// Demo: Insert the word "bark" into the trie
insertWord("bark");
console.log(JSON.stringify(trie, null, 2));
// Output of the console log
{
"b": {
"a": {
"b": {
"y": {
"isEndOfWord": true
}
},
"r": {
"s": {
"isEndOfWord": true
},
"k": {
"isEndOfWord": true
}
}
}
}
}
The search operation is similar to insertion since you’re comparing the string you’re looking for to the existing nodes. But instead of adding nodes to the data structure, you’re simply traversing the nodes to see if the string exists.
Let’s search for the string “barn” in a predefined trie with the words — baby, bark, and bars.
If the trie doesn’t include a matching prefix branch (such as “bar-”), then the string doesn’t exist. Also, if the end of the string doesn’t include an “end of word” mark, the string doesn’t exist. For instance, the word existing in the trie could be “barns” and not “barn.”
Here is a code snippet and demo for this search operation in JavaScript:
// I have a predefined trie with the words "baby", "bark", and "bars"
const trie = {
"b": {
"a": {
"b": {
"y": {
"isEndOfWord": true
}
},
"r": {
"k": {
"isEndOfWord": true
},
"s": {
"isEndOfWord": true
}
}
}
}
};
// Function that searches for a word in the trie
function search(word) {
let currentNode = trie; // Starts at the root node
// Loops through each character in the word
for (let char of word) {
// If the character is not found in the trie, return false
if (!currentNode[char]) {
return false;
}
// Moves to the next node
currentNode = currentNode[char];
}
// Checks if the current node marks the end of a word
return currentNode.isEndOfWord === true;
}
// Demo: Search for the word "barn"
const isFound = search("barn");
console.log(isFound ? "Word found!" : "Word not found."); // Searches the trie
// Output of the console log
Word not found.
Lastly, the deletion operation removes unneeded strings from the trie. Unlike insertion and search, deletion requires some caution to ensure you aren’t affecting strings that share a prefix with the string being removed.
Let’s delete the string “boom” in a predefined trie with the words — boom, boomer, and body.
If the string “boomer” didn’t exist in the trie, I could remove the nodes with the values m and o since they would no longer be needed to complete a string.
Here is a code snippet and demo for this deletion operation in JavaScript:
// I have a predefined trie with the words "boom", "boomer", and "body"
const trie = {
'b': {
'o': {
'o': {
'm': {
'isEndOfWord': true,
'e': {
'r': {
'isEndOfWord': true
}
}
}
},
'd': {
'y': {
'isEndOfWord': true
}
}
}
}
};
// Function that deletes a word from the trie
function deleteWord(trie, word) {
function deleteHelper(node, word, index) {
if (index === word.length) {
// If the end of the word is found
if (node.isEndOfWord) {
node.isEndOfWord = false;
// Checks if node has no other children
return Object.keys(node).length === 1;
}
return false;
}
const char = word[index];
if (node[char]) {
const shouldDeleteChild = deleteHelper(node[char], word, index + 1);
if (shouldDeleteChild) {
delete node[char];
// Checks if current node has other children
return Object.keys(node).length === 0;
}
}
return false;
}
deleteHelper(trie, word, 0);
}
// Demo: Delete the word 'boom' from the trie
deleteWord(trie, 'boom');
console.log(JSON.stringify(trie, null, 2));
// Output of the console log
{
"b": {
"o": {
"o": {
"m": {
"isEndOfWord": false,
"e": {
"r": {
"isEndOfWord": true
}
}
}
},
"d": {
"y": {
"isEndOfWord": true
}
}
}
}
}
Though tries heavily rely on software engineers to be properly implemented, UX designers can still benefit from understanding and advocating for the usage of tries in their websites or applications (unless you’re a unicorn who can design and code).
As we’ve discussed, tries help applications run important features such as auto-complete, spell-checking algorithms, and text prediction. Each of these features improves the interface’s functionality by assisting the user as they complete tasks.
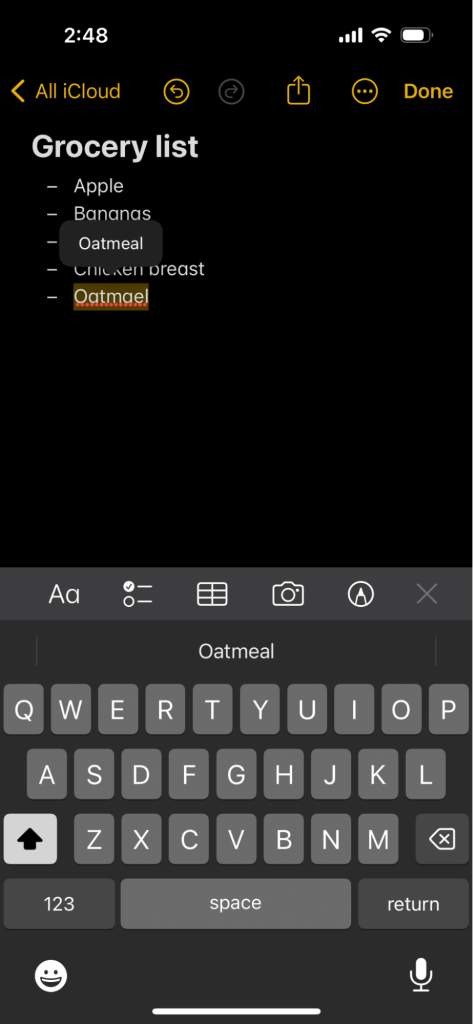
Let’s say I’m making a grocery list in my iPhone’s Notes app. As I type in items in the list, there’s a bar above the keyboard with options that dynamically update depending on what I type.
In the image below, I typed “Oa-” and I received a suggestion for “oatmeal” (which was correct):
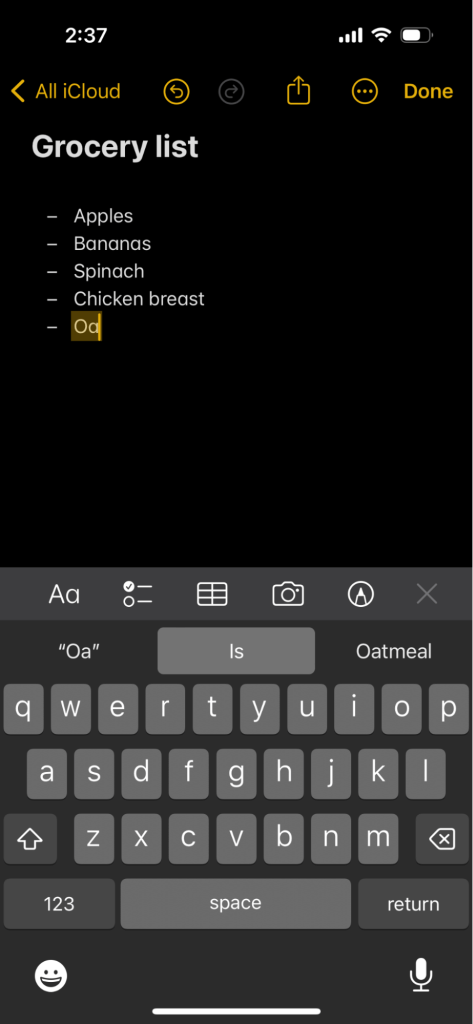
Instead of typing “Oatmeal,” I can simply select the suggestion to replace what I’ve already typed. Not only that, if I accidentally type “Oatmael,” it automatically updates my spelling mistake after I finish typing the word.
Because trie data structures were implemented, it used my input of “Oa-” to search the trie and prefix match for possible options. It then showed me the suggestion of “Oatmeal” since that was a match (I may get more than one suggestion depending on the prefix).
As for spell-checking, my incorrect input of “Oatmael” was traversed in the trie, and nodes with invalid characters were replaced to be valid.
These examples of auto-complete and spell-checking add value to any website or app with tasks that involve typing by taking some of the work off the user’s plate.
Who wants to memorize how to spell “restaurant”? I don’t. Because trie data structures are implemented in the apps I use, all I have to do is type “res-” and let my device do the rest of the work for me.
This section will guide you in determining if using a trie is the best option for structuring data on your website or application.
But before we get into the pros and cons, let’s review two similar data structure types to compare tries to — hash tables and binary search trees:
Trie data structures have already proven to be advantageous since they are used in many applications, but let’s review specific strengths of a trie:
Trie data structures are powerful and useful when implemented, but they do come with limitations. Let’s review some of the weaknesses of a trie:
Tries, hash tables, and BSTs are efficient data structures but are strongly suited for particular applications.
For instance, if you need exact data matching, hash tables will be the best option since they will be the quickest at finding the match. Or, if you need auto-complete or text-prediction, tries will be the best option due to its prefix matching capabilities.
In this article, I shared how trie data structures efficiently store, search, and retrieve strings from large collections of data. Whether you know it or not, many of the features we use on a daily basis are powered by trie data structures, such as auto-complete and spell-checking algorithms.
Tries are built from a root node and child nodes, and relationships between nodes are made from edges. Each root node contains a null value, and each child node holds one value that references an array of possible values. As you traverse down a trie, you will be able to spell out strings that have been inserted; the strings can spell out anything, such as “hello!” or “buy sunglasses”.
Trie data structures support three main operations — insertion, searching, and deletion:
In terms of UX design, tries are critical to enhancing the functionality of a website or application. If you expect a user to frequently type or use a search function, implementing a trie data structure will assist the user in completing tasks effectively. The user will be able to do tasks like filling out forms or searching a page quickly while reducing the UI costs.
Trie data structures are effective when managing datasets, and they reduce redundancies when strings share common prefixes. Tries are versatile and powerful tools to implement in your projects for the right use cases.

LogRocket lets you replay users' product experiences to visualize struggle, see issues affecting adoption, and combine qualitative and quantitative data so you can create amazing digital experiences.
See how design choices, interactions, and issues affect your users — get a demo of LogRocket today.

Radio buttons for single choice. And checkboxes for multiple choices. Seems simple? There’s a lot more to it. I talk about the differences, use cases, and the best UX practices for using them.

Creating intuitive interfaces starts with the HIG. In this blog, I’ll summarize all of the HIG principles, why they matter, and how you can apply them to build better UX.

Cart abandonment is a major hurdle. But with these 10 UX tweaks, you can create a more convincing path to purchase, drive conversions, and minimize dropoffs.

Design engineering is becoming integral to UX roles. But how is this shift impacting job descriptions for UX designers, and what can you do about it?


